这篇文章主要介绍了Hive在Hadoop上的安装及一些基本的Hive操作
写在开头
环境
Hadoop单机
Centos7
Hadoop-2.7.3
hadoop位置:/usr/loacl/hadoop
下载Hive
下载源码包1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21#在hadoop目录下操作
cd /usr/local/hadoop
#用wget下载
wget http://mirrors.cnnic.cn/apache/hive/hive-1.2.1/apache-hive-1.2.1-bin.tar.gz
#也可以在图形界面下下载之后,上传压缩包
#解压缩包
tar -zxvf apache-hive-1.2.1-bin.tar.gz
#配置环境变量
vim /etc/profile
#位置在之前配置的变量之后,大概12行左右,因为之前配置了jdk和hadoop变量
export HIVE_HOME=/usr/local/hadoop/apache-hive-1.2.2-bin
export PATH=$HIVE_HOME/bin:$PATH
#适当位置添加"$HIVE_HOME/bin:"
#保存退出
#使文件生效
source /etc/profile
安装MySQL
MariaDB数据库管理系统是MySQL的一个分支,主要由开源社区在维护,采用GPL授权许可。开发这个分支的原因之一是:甲骨文公司收购了MySQL后,有将MySQL闭源的潜在风险,因此社区采用分支的方式来避开这个风险。MariaDB的目的是完全兼容MySQL,包括API和命令行,使之能轻松成为MySQL的代替品。
在Centos7下,使用命令安装mysql,会安装成mariadb。
在这里先介绍安装MariaDB,原因如上。
安装MariaDB
1 | #安装 |
正式安装MySQL
1 | #下载,在这里使用的是命令行下载,也建议在图形界面下载,然后上传至服务器 |
配置MySQL
编码配置1
2
3
4
5
6
7
8
9#进入配置文件,若未安装vim,建议先使用命令yum install vim安装vim
vim /etc/my.cnf
#最后加上编码配置
[mysql]
default-character-set =utf8
#此处字符编码必须和/usr/share/mysql/charsets/Index.xml中一致。
#不过一般情况下使用的都是utf8
设置密码1
2
3
4
5
6
7
8
9
10
11
12#下面三种方法需要进入mysql
mysql -u root -p
#方法一
mysql>insert into user(host,user,password) values('%','user_name',password("password");
#方法二
mysql>set password for user_name = password("password");
#方法三
mysql>grant all on *.* to user_name@% identified by "password";
#下面这一种方法可直接在shell下设置密码
mysqladmin -u root password "password"
远程连接
1 | #进入mysql |
P.S.上文引号中的user_name表示数据库的用户名,password表示对应用户的密码。即这两项是由读者自行定义的。
常见问题及解决方案
Mysql创建用户失败
1 | # mysql在my.ini的配置文件中设置了严格模式,所以我们需要进行修改 |
支持中文
Centos7
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20# 编辑文件
vim /etc/my.cnf
# 在对应[xx]下增加修改如下代码
[client]
port = 3306
socket = /var/lib/mysql/mysql.sock
default-character-set=utf8
[mysqld]
port = 3306
socket = /var/lib/mysql/mysql.sock
default-storage-engine=INNODB
character-set-server=utf8
collation-server=utf8_general_ci
[mysql]
no-auto-rehash
default-character-set=utf8
# 保存退出,重启服务
# 重新登陆mysql检查是否成功,方法见下
Ubuntu16.04
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf
# 在对应[xx]下增加以下内容,如果不存在[xx]自行增加
[mysqld]
character_set_server=utf8
[mysql]
default-character-set=utf8
[mysql.server]
default-character-set=utf8
[mysqld_safe]
default-character-set=utf8
[client]
default-character-set=utf8
# 重启mysql
service mysql restart
# 进入mysql查看配置参数
mysql -uroot -p
# 查看database 的value变为utf8即可
>show variables like '%character%';
# p.s.如果之前创建了表,表编码不会改变
MySQL报错“1366 - Incorrect integer value: ‘’ XXXXXXX’ at row 1 ”
修改方法:(两种,建议第二种)
命令行。set names gbk;(此为设置通信编码)
my.cnf中查找sql-mode
将1
sql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION",
修改为1
sql-mode="NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION",
重启mysql后即可
关于my.cnf和my.ini的说明
my.cnf常见于Linux系统,my.ini常见与windows系统,二者都是属于mysql的配置文件。一般好像在一个系统下就是只出现一种配置文件,具体区别没有深入了解,修改配置文件,根据自己的系统进行查找修改配置文件即可
Mysql交互环境自动补全
1 | # 修改配置文件 |
配置Hive
我们之前在hadoop目录下安装了Hive,位置为/usr/local/hadoop/apache-hive-1.2.1-bin
1 | #进入hive配置目录下 |
下载JDBC
1 | #命令行下载,也可以使用图形界面上传文件 |
启动Hive1
2
3
4
5
6
7
8
9
10
11hive --service metastore &
jps
#结果会多出一个进程
#进入hive目录
cd /usr/local/hadoop/apache-hive-1.2.1-bin/bin
#启动hive,可能有点慢
hive
#若出现hive的命令行即代表成功,如下
hive>
常见问题及解决方案
1 | Logging initialized using configuration in jar:file:/home/hadoop/apache-hive-1.2.1-bin/lib/hive-common-1.2.1.jar!/hive-log4j.properties |
解决方法,直接关闭防火墙
1 | #这里的系统为Centos7,所以使用此命令 |
hive metastore 启动出错解决1
2
3
4
5
6# 查看与hive相关进程是否启动
ps -ef | grep hive
# kill相关进程,为进程号
kill num
# 重新启动
./hive
更多问题见此文章
Hive常见问题汇总
Hive的学习笔记
新建表
1 | -- 新建一张表,名为“test”,里面有“name”、“id”两类,分别是“string”、“int”的数据类型,以“|”隔开一列,表是作为textfile的。 |
加载表
1 | -- 从本地的/home/user/test.txt文件,将数据加载进test这个表 |
关联表
1 | -- 将两张表通过一个或多个字段关联在一起 |
保存表
1 | -- 由于hive下执行任务之后,并不会保存数据,所以我们使用INSERT命令来保存命令 |
排序问题
- order by
1 | hive> SELECT * FROM test ORDER BY id; |
sort by
1
hive> SELECT * FROM test SORT BY id;
distribute by
1
hive> SELECT * FROM test ORDER BY name DISTRIBUTE BY id;
DISTRIBUTE BY with SORT BY
DISTRIBUTE BY 和 GROUP BY 有点类似,DISTRIBUTE BY控制reduce如何处理数据,而SORT BY控制reduce中的数据如何排序。
注意:hive要求DISTRIBUTE BY语句出现在SORT BY语句之前。Cluster By
cluster by 除了具有 distribute by 的功能外还兼具 sort by 的功能。
默认升序排序,但DISTRIBUTE BY的字段和SORT BY的字段必须相同,且不能指定排序规则。
总结:
ORDER BY是全局排序,但在数据量大的情况下,花费时间会很长SORT BY是将reduce的单个输出进行排序,不能保证全局有序DISTRIBUTE BY可以按指定字段将数据划分到不同的reduce中- 当
DISTRIBUTE BY的字段和SORT BY的字段相同时,可以用CLUSTER BY来代替DISTRIBUTE BY with SORT BY。
hive常用函数
1 | # 以下无特殊说明,返回值皆为string |
hive导出数据
1 | # 导出至本地,content表示本地目录 |
转换类型
cast(xxx as xx)
将xxx类型转换为xx类型
下表为是否可转换类型的说明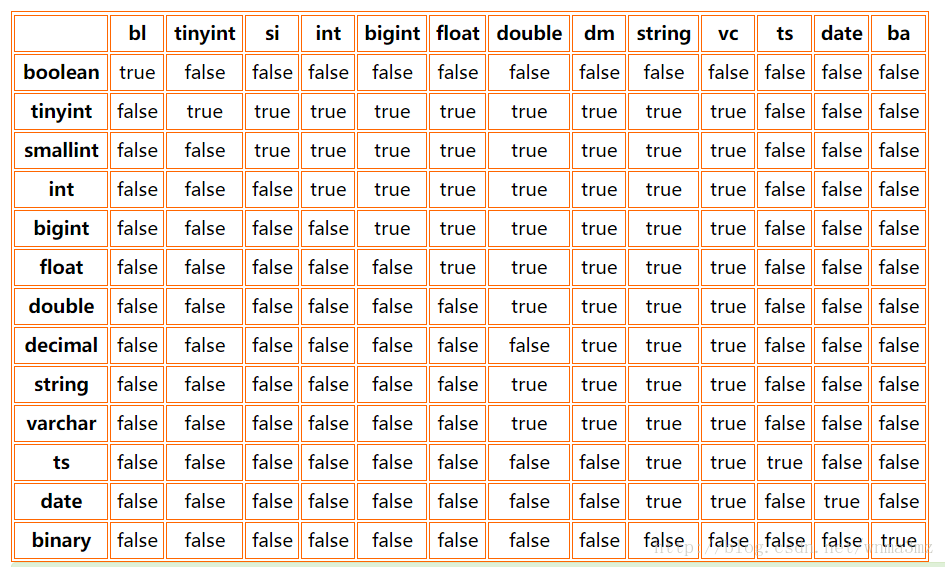
注:由于表格比较大,这里对一些比较长的字符串进行缩写,ts是timestamp的缩写,bl是boolean的缩写,sl是smallint的缩写,dm是decimal的缩写,vc是varchar的缩写,ba是binary的缩写。