如何爬取微信公众号所有历史文章的阅读量和点赞量?该文介绍了两种突破难点的方法:一是使用微信个人订阅号进行爬取,二是在电脑上使用Fiddler进行抓包分析。详细的操作步骤及代码实现都在文中。缺陷是需要手动获取一些关键参数。针对被封禁的问题,文中提供了两种解决方案。
项目实现地址。查看我的Github地址
日更两次,获取公众号的最新文章链接,暂不支持实时获取阅读点赞
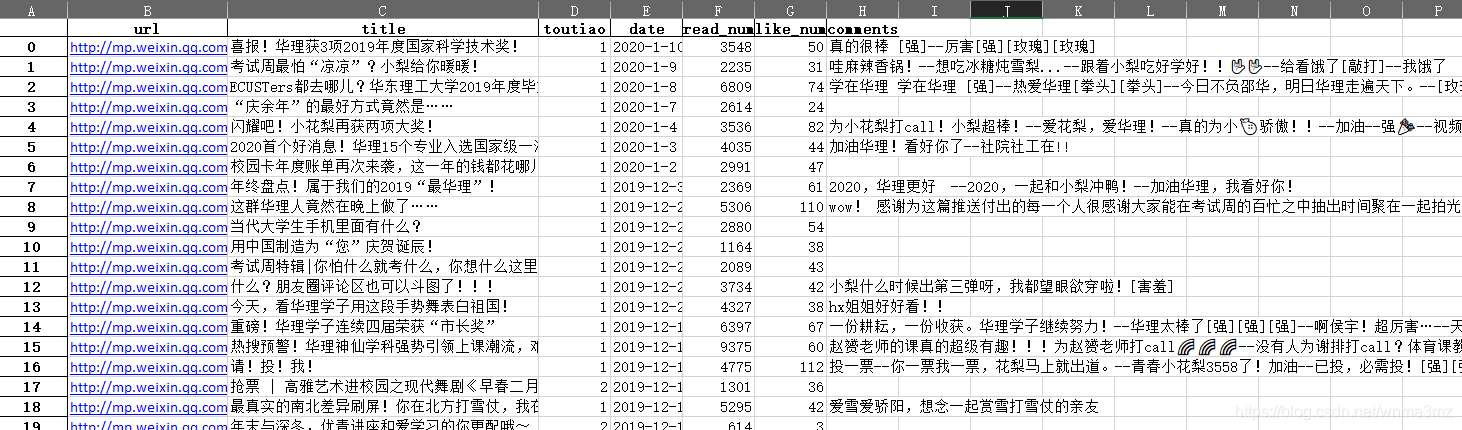
支持下载文章内容为HTML(含图片,经过二次处理可转换为PDF、Word)。欢迎技术交流,微信:wnma3mz,烦请进行相关备注,如hexo_wechat_spider。二维码见文末,样例图:
目前具体可获取指标(包含但不局限):阅读数、点赞数(在看)、评论内容及总数、正文内容及图片、是否为头条、是否为原创。
项目已经实现,比本文介绍的更加方便简单,可直接调用。
关于批量关注公众号的问题已解决,见我的另一篇文章:自动批量关注微信公众号(非逆向)
不求完美,只求能够用。。。
截至2019年4月项目可正常运行, 方法已更新。
3月1号更新:
- 获取阅读点赞时,每篇文章间隔10s 一次性可获取500篇文章以上
- 从公众号获取永久链接时,间隔3分钟,可以连续获取几小时(网友测试)
公开已爬取的公众号历史文章的永久链接,数据上传至GitHub,日期均截止commit时间。
需求
某某微信公众号历史的所有文章的阅读数和点赞数
难点
- 微信公众号历史的所有文章(来源???)
- 每篇文章的阅读量和点赞量(电脑上浏览文章只显示内容,没有阅读量、点赞量、评论……)
突破难点一
- 搜狗微信搜索,可以搜索微信公众号文章。但是貌似只能显示该公众号最近十篇的文章。放弃……
- 利用抓包工具(Fiddler),抓取文章。成本有点大……,且貌似只能抓取原创文章。不符合个人需求,放弃……
- 利用微信个人订阅号进行爬取,神奇的操作。
操作
- 拥有一个微信个人订阅号,附上登陆和注册链接。微信公众平台
- 好在之前无聊注册过一次,所以就可以直接登陆操作。没有注册的童鞋可以用自己的微信号注册一下,过程十分简单,在此就不赘述了
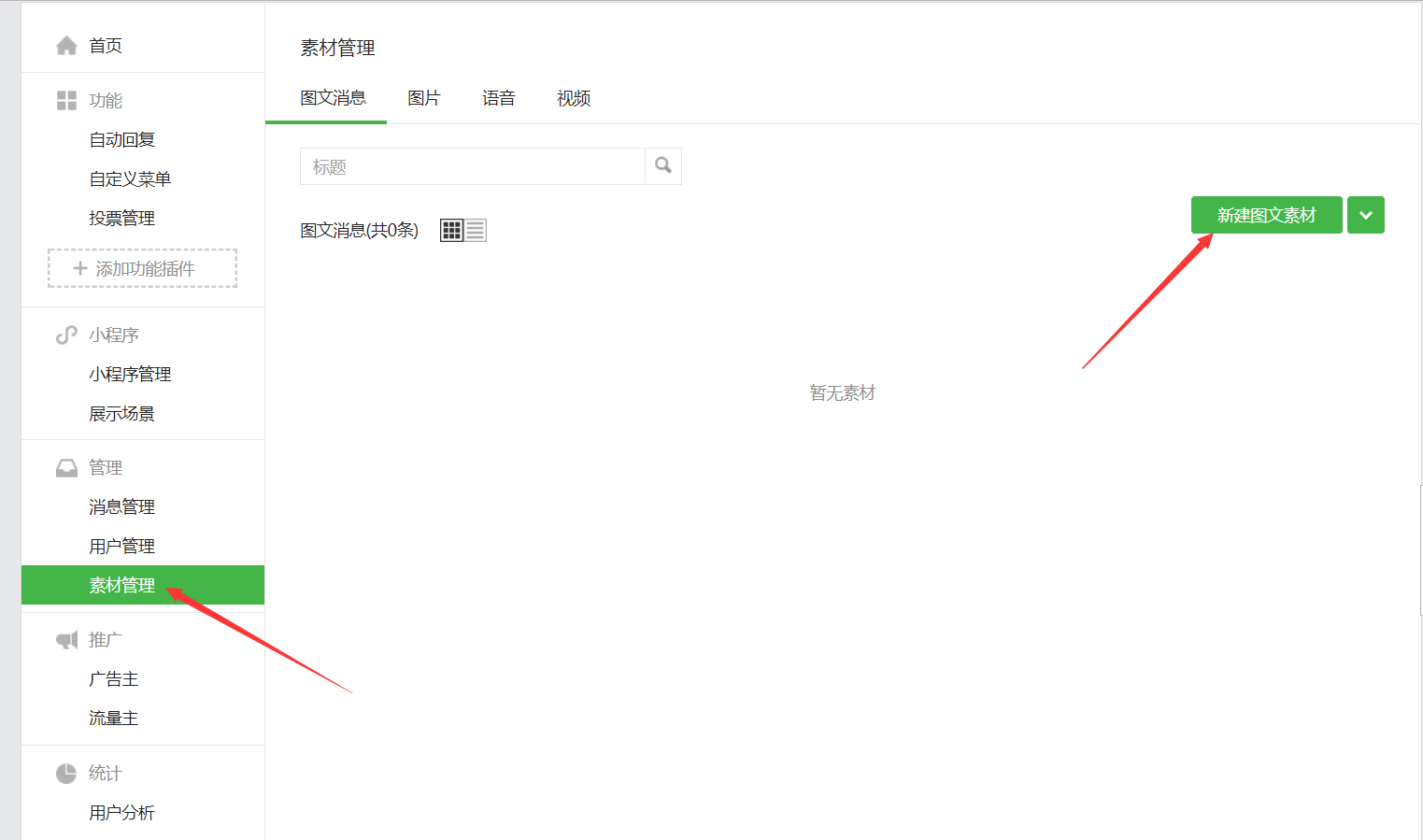
- 登陆之后,点击左侧菜单栏“管理”-“素材管理”。再点击右边的“新建图文素材”
- 弹出一个新的标签页,在上面的工具栏找到“超链接”并点击

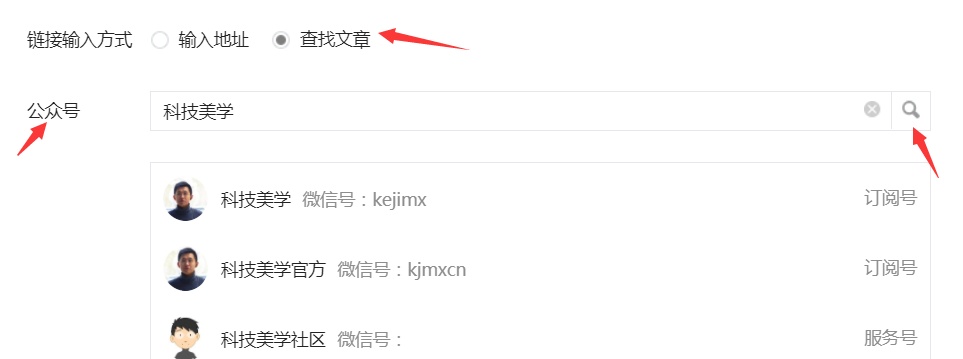
- 弹出了一个小窗口,选择“查找文章”,输入需要查找的公众号,这里用“科技美学”公众号作为例子
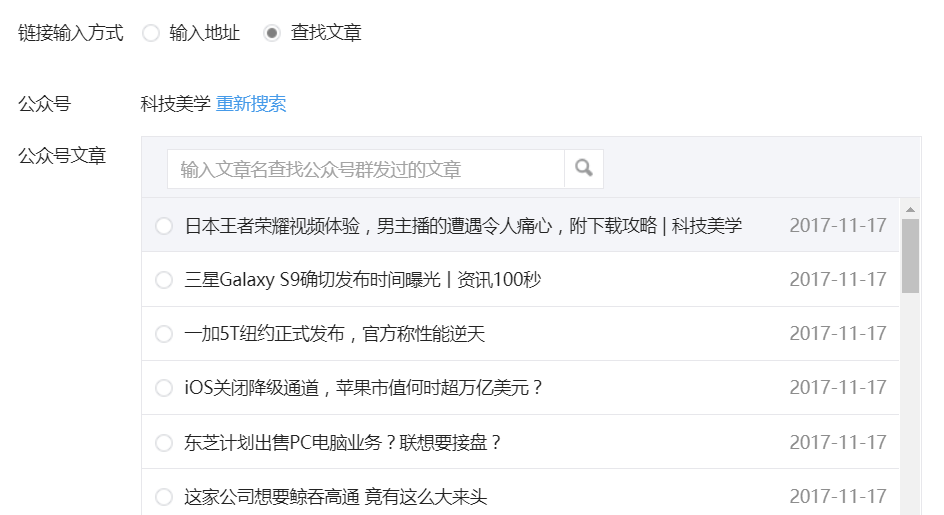
- 点击之后,可以弹出该公众号的所有历史文章
代码实现
1 | # -*- coding: utf-8 -*- |
以上,即可爬取微信公众号的一页数据,如果是爬取所有页的数据,则需要改变number进行爬取。
注:每次抓取完一页之后,最好设定time.sleep(3)。过快会导致爬取失败
突破难点二
这里我使用的方法是在电脑上登陆微信客户端,进行抓包分析。从客户端看推文可以看到阅读量、点赞量。
我使用的是Fiddler。Fiddller具体使用就不赘述了。下面直接演示操作
操作
- 打开fiddler开始监控
- 登陆微信客户端,浏览该公众号的任意一篇推文
- 可以观察到这里的内容显示会有阅读量、点赞量、评论等
- 观察fiddler的监控数据,如下图显示
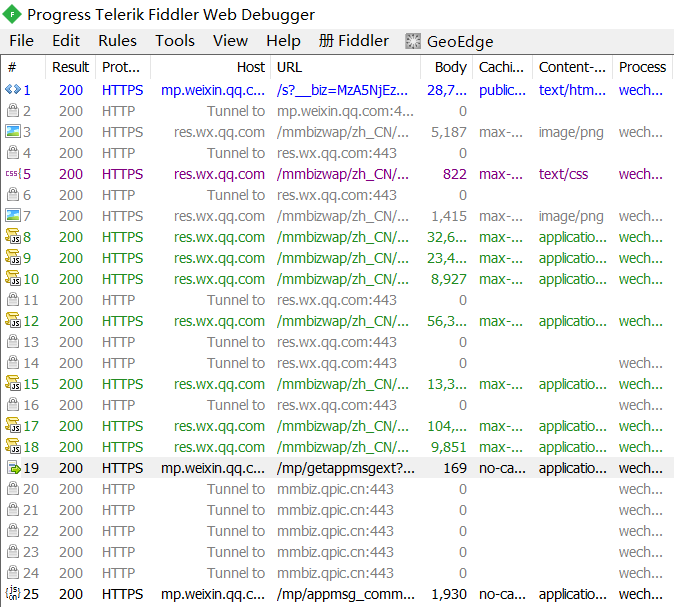 5. 其中
5. 其中
/mp/getappmgsext?...是我们推文内容的url,双击之后,fiddler界面右边出现如下图数据
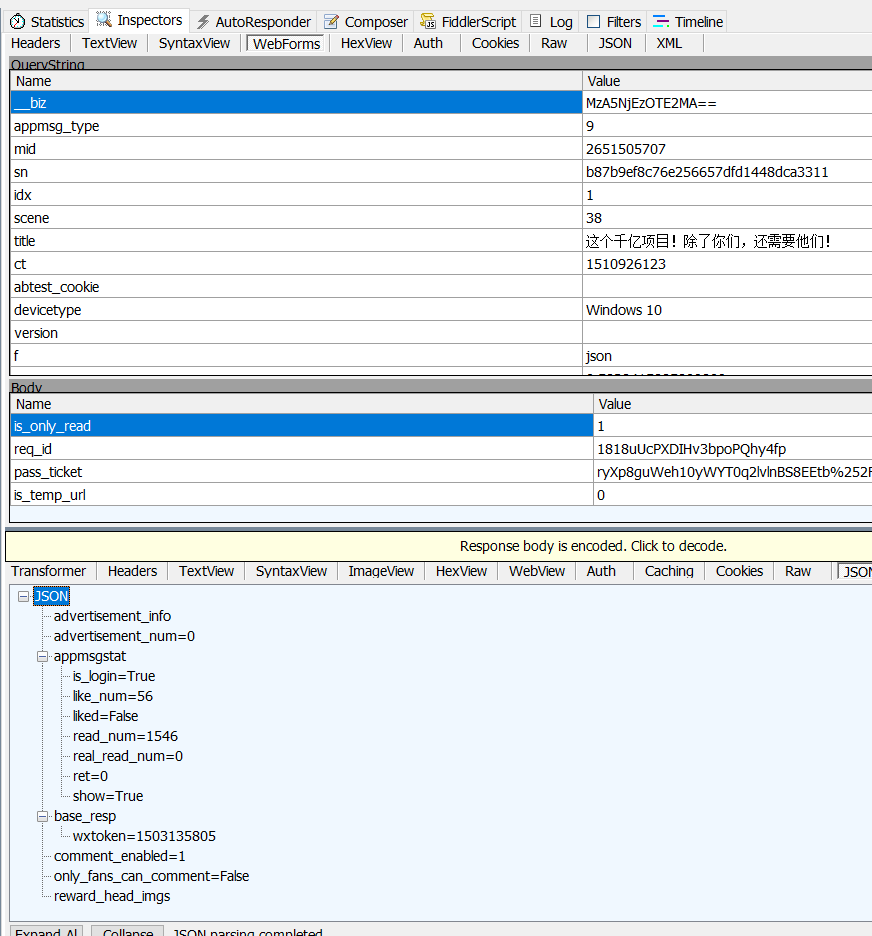 6. 上图下侧的json里面的
6. 上图下侧的json里面的
read_num、like_num分别是阅读量和点赞量
####代码实现
1 | import time |
以上即可获取到一篇文章的阅读量、点赞量。
Cookie、req_id、pass_ticket、key、appmsg_token、__biz利用fiddler获取
如果是需要多篇文章,需要更改的参数
mid、sn、idx
如果是不同公众号,就需要根据url修改 __biz
多篇文章的爬取,需要根据之前爬取到的url进行提取关键信息,分别爬取。
注:每次抓取完一页之后,最好设定time.sleep(3)。过快会导致爬取失败。
写在最后
以上就是这次微信爬虫的经历。
需要掌握的基本技能:
- python爬虫的语法
- Chrome、Fiddler基本使用
- 网络爬虫基本常识
缺陷:
- 使用Cookie登陆,未实现自动登陆
- key、appmsg_token一些关键参数需要进行手动获取
- 实际运行之后,就算设定了爬取间隙时间,还是会被封禁(获取链接时)。
说明:
- 网上一些说法,key半小时过期,我好像没有遇到。
- 代码中若有细节问题,欢迎指出讨论
Github上已经实现了第1、2点,欢迎回到文章开头看github上的实现过程。
关于被封禁的问题,已有两个解决方案,均放在github上,在这不做讲解。
- selenium解决方案,提高约十倍抓取量(不确定)。优点:提高抓取量;缺点:速度慢,不一定能完全抓取完整,抓取量不确定。test_seleinum.py
- 利用个人微信号的查看公众号历史消息,抓取量在500条以上,具体未测试。优点:抓取量最多的方案;缺点:短时间内(5-10分钟)无法查看历史消息,或者说无法持续抓取;不保证微信号会被封号。test_GetUrls.py