NLP基本知识的介绍及NLTK模块的使用。
写在开头
在这里主要是对NLP的相关知识做一个整理和对NLTK模块的介绍,书中Python基础内容在这里不做介绍,如书中有我认为值得介绍的Python写法,我会进行说明。
由于书中nltk是老版本的问题,语法上存在一些变动,在这里也会进行修正。可能由于书是译本的原因(当然也可能原作者自己的失误),部分代码有些错误,在这里我也进行了校正。如果您发现了我的文章中有需要改正或改进的地方,欢迎在评论区提出。
最后十分感谢原作者的贡献和译者的翻译,强烈推荐读者亲自阅读此书。
nltk版本是3.2.3,官网
python版本3.6.1
数据、PDF和一些重要的代码已经放在了Github上了。github地址
第一章:语言处理与Python
NLTK库的安装,在这里不做介绍,强烈建议直接使用Anaconda环境。官网下载链接 。本文是直接使用了Anaconda环境。
数据的获取,这里nltk有官方提供的文本数据,可以直接使用nltk.download()打开图形界面,下载语料集book。由于使用这个方法下载速度比较慢的原因,我在这里Github上提供了数据集nltk_data,下载之后,移动到nltk.download()原本的下载目录下,之后再运行nltk.download()就不需要下载数据集而是直接解压数据集,速度会快上很多。下载链接
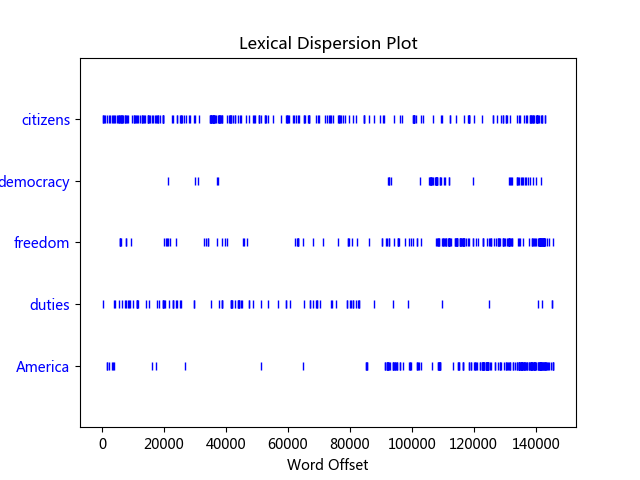
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import nltkfrom nltk.book import *text1.concordance("monstrous" ) text1.similar("monstrous" ) text2.common_contexts(["monstrous" , "very" ]) text4.dispersion_plot(["citizens" , "democracy" , "freedom" , "duties" , "America" ]) text3.generate()
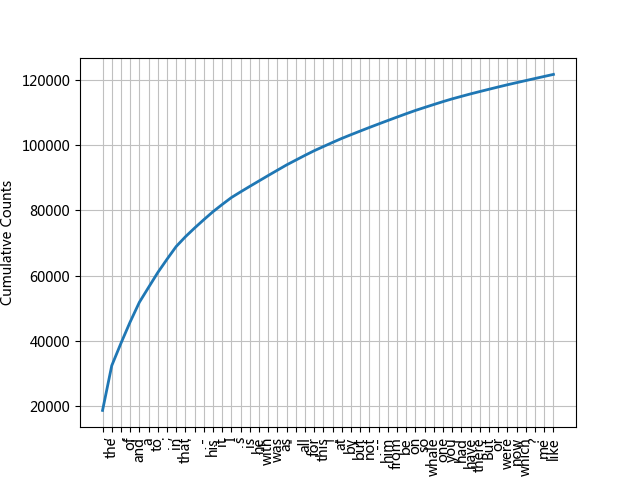
1 2 3 4 5 6 7 8 9 10 11 fdist1 = FreqDist(text1) fdist1.keys()[:50 ] fdist1['whale' ] fdist1.plot(50 , cumulative=True ) fdist1.hapaxes()
1 2 3 4 5 6 7 nltk.bigrams(['more' ,'is' , 'said' , 'than' , 'done' ]) [('more' ,'is' ),('is' ,'said' ),('said' , 'than' ), ('than' ,'done' )] text4.collocations()
1 2 3 4 5 from nltk.chat import chatbotschatbots()
补充部分:
text1
《白鲸记》(Moby Dick by Herman Melville 1851)
text2
《理智与情感》(Sense and Sensibility by Jane Austen 1811)
text3
《创世纪》(The Book of Genesis)
text4
《就职演说语料库》(Inaugural Address Corpus)
text5
《NPS聊天语料库》(Chat Corpus)
text6
《巨蟒与圣杯》(Monty Python and the Holy Grail)
text7
《华尔街日报》(Wall Street Journal)
text8
《个人文集》(Personals Corpus)
text9
《周四的男人》(The Man Who Was Thursday by G . K . Chestert)
概念补充:
词类型:一个词在一个文本中独一无二的出现形式或拼写。也就是说,这个词在词汇表中是唯一的。
频率分布:
词意消歧:需要算出特定上下文中的词被赋予的是哪个意思。单词可能存在相同/相近的含义,此时需要根据上下文来推断单词在此情景下的含义。
指代消解(anaphora resolution):确定代词或名词短语指的是什么
先行词:代词可能代表的对象
语义角色标注(semantic role labeling):确定名词短语如何与动词相关联(如施事,受事,工具等)
自动生成语言:需要解决自动语言理解。弄清楚词的含义、动作的主语以及代词的先行词是理解句子含义的步骤
机器翻译(MT):难点,一个给定的词可能存在几种不同的解释。
文本对齐:根据一个网站发布的多种语言版本,来自动配对组成句子
人机对话系统:图灵测试。
文本含义识别(Recognizing Textual Entailment 简称 RTE):根据假定的一些条件,来推断给出的一句话是否正确。
第二章:获得文本语料和词汇资源
古腾堡语料库
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from nltk.corpus import gutenberggutenberg.fileids() emma = gutenberg.words('austen-emma.txt' ) len (emma)emma = nltk.Text(emma) emma.concordance("suprprize" ) emma_sents = gutenberg.sents('austen-emma.txt' ) emma_raw = gutenberg.raw('austen-emma.txt' )
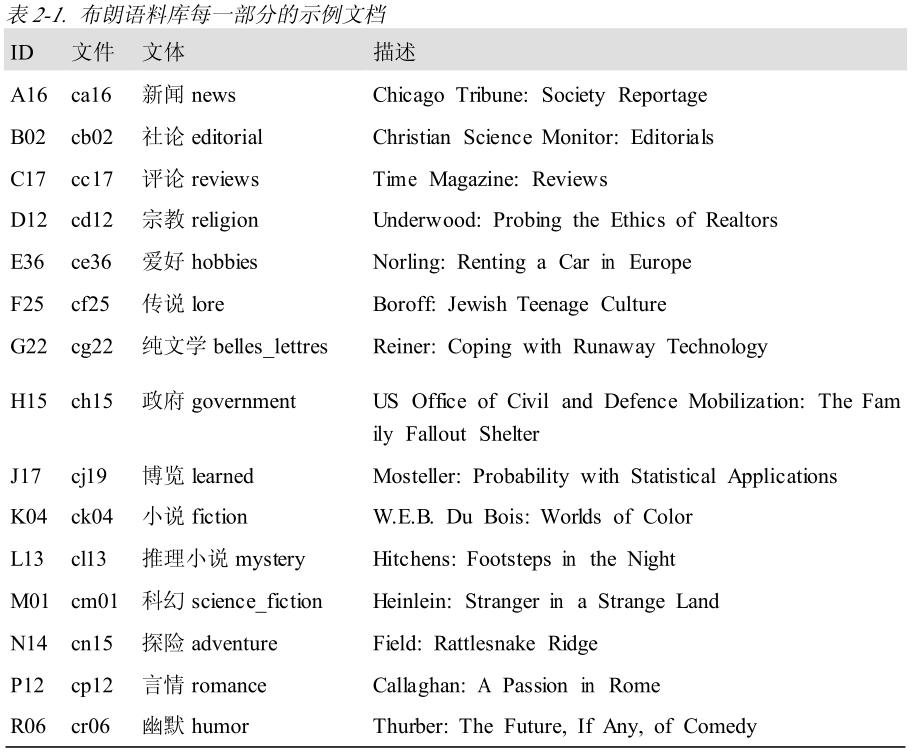
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from nltk.corpus import webtextfrom nltk.corpus import nps_chatfrom nltk.corpus import brownbrown.categories() brown.words(categories='news' ) ['The' , 'Fulton' , 'County' , 'Grand' , 'Jury' , 'said' , ...] brown.words(fileids=['cg22' ]) ['Does' , 'our' , 'society' , 'have' , 'a' , 'runaway' , ',' , ...] brown.sents(categories=['news' , 'editorial' , 'reviews' ])
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import nltkfrom nltk.corpus import browncfd = nltk.ConditionalFreqDist( (genre, word) for genre in brown.categories() for word in brown.words(categories=genre)) genres = ['news' , 'religion' , 'hobbies' , 'science_fiction' , 'romance' , 'humor' ] modals = ['can' , 'could' , 'may' , 'might' , 'must' , 'will' ] cfd.tabulate(conditions=genres, samples=modals) """ can could may might must will news 93 86 66 38 50 389 religion 82 59 78 12 54 71 hobbies 268 58 131 22 83 264 science_fiction 16 49 4 12 8 16 romance 74 193 11 51 45 43 humor 16 30 8 8 9 13 """
通过输出,我们很容易发现,在news类别里面用的最多的情态动词是will。当然,还有一些结论就由读者自行发现了。
关于其他语料库的信息挖掘,在这里就不赘述了。书中也只是浅显的用了之前用过的一些方法。下面展示一些我认为比较有意思的代码及输出。
官网提供了如何访问NLTK语料库的其他例子,链接
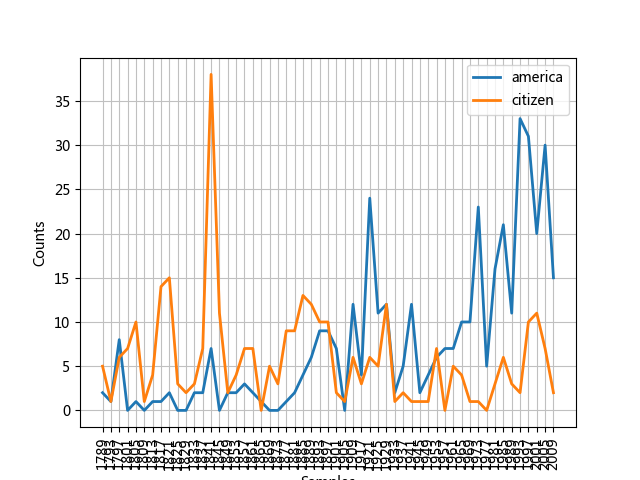
1 2 3 4 5 6 7 8 9 10 11 12 import nltkfrom nltk.corpus import inauguralcfd = nltk.ConditionalFreqDist( (target, fileid[:4 ]) for fileid in inaugural.fileids() for w in inaugural.words(fileid) for target in ['america' , 'citizen' ] if w.lower().startswith(target)) cfd.plot()
以america或citizen开始的词随时间(年份)的演变趋势
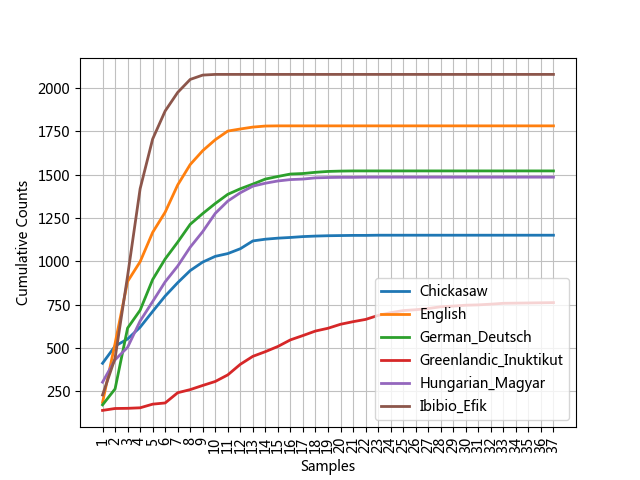
1 2 3 4 5 6 7 8 9 10 11 12 13 import nltkfrom nltk.corpus import udhrlanguages = ['Chickasaw' , 'English' , 'German_Deutsch' , 'Greenlandic_Inuktikut' , 'Hungarian_Magyar' , 'Ibibio_Efik' ] cfd = nltk.ConditionalFreqDist( (lang, len (word)) for lang in languages for word in udhr.words(lang + '-Latin1' )) cfd.plot(cumulative=True )
累积字长分布: “世界人权宣言”的6个翻译版本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from nltk.corpus import PlaintextCorpusReadercorpus_root = '/usr/share/dict' wordlists = PlaintextCorpusReader(corpus_root, '.*' ) wordlists.fileids() wordlists.words('connectives' ) from nltk.corpus import BracketParseCorpusReadercorpus_root = r"C:\corpora\penntreebank\parsed\mrg\wsj" file_pattern = r".*/wsj_.*\.mrg" ptb = BracketParseCorpusReader(corpus_root, file_pattern) ptb.fileids()
双连词运用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 def generate_model (cfdist, word, num=15 ): for _ in range (num): print(word) word = cfdist[word].max () text = nltk.corpus.genesis.words('english-kjv.txt' ) bigrams = nltk.bigrams(text) cfd = nltk.ConditionalFreqDist(bigrams) print(cfd['living' ]) generate_model(cfd, 'living' )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from nltk.corpus import stopwordsstopwords.words('English' ) from nltk.corpus import wordswords.words() from nltk.corpus import namesfrom nltk.corpus import cmudictcmudict.entries() from nltk.corpus import swadeshswadesh.fileids() swadesh.words('en' ) from nltk.corpus import toolboxtoolbox.entries('rotokas.dic' )
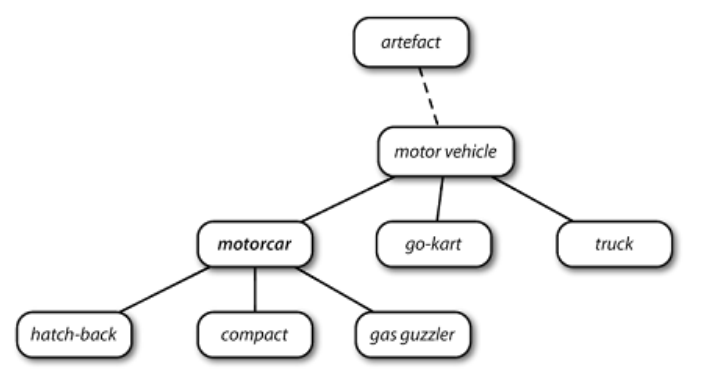
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 from nltk.corpus import wordnet as wnwn.synsets('motorcar' ) wn.synset('car.n.01' ).lemma_names wn.synset('car.n.01' ).definition wn.synset('car.n.01' ).lemmas wn.lemma('car.n.01.automobile' ) wn.lemma('car.n.01.automobile' ).synset wn.lemma('car.n.01.automobile' ).name wn.lemmas('car' ) motorcar = wn.synset('car.n.01' ) types_of_motorcar = motorcar.hyponyms() motorcar.hypernyms() paths = motorcar.hypernym_paths() motorcar.root_hypernyms() nltk.app.wordnet() wn.synset('tree.n.01' ).part_meronyms() wn.synset('tree.n.01' ).substance_meronyms() wn.synset('tree.n.01' ).member_holonyms() wn.synsets('mint' , wn.NOUN) wn.synset('walk.v.01' ).entailments() wn.lemma('supply.n.02.supply' ).antonyms() dir (wn.synset('harmony.n.02' ))right = wn.synset('right_whale.n.01' ) minke = wn.synset('minke_whale.n.01' ) right.lowest_common_hypernyms(minke) wn.synset('baleen_whale.n.01' ).min_depth() right.path_similarity(minke)
概念补充:
文本语料库的结构:
孤立的无特别组织的文本集合
按文体等分类组织结构
分类重叠,主题类别(路透社语料库)
随时间变化语言语言用法的改变(就职演说语料库)
NLTK中定义的基本语料库函数
条件频率分布
条件频率分布是频率分布的集合,每个频率分布有一个不同的“条件”。这个条件通常是文本的类别。
当语料文本被分为几类(文体、主题、作者等)时,我们可以计算每个类别独立的频率分布,研究类别之间的系统性差异。
条件和事件
对于NLP来说,文本出现的词汇就是事件。条件频率分布需要给每个事件关联一个条件,所以处理的是一个配对序列。每对形式是:(条件,事件)。举例就是,(文本类别,文本中的一个词汇)
FreqDist()以一个简单的链表作为输入,ConditionalFreqDist()以一个配对链表作为输入。
停用词: 如the、to这种高频词汇。这种词通常没有什么词汇内容,但是它们又会让文本分析变得困难。所以在需要的情况下,我们就需要从文档中过滤掉他们。
WordNet:面向语义的英语词典,类似与传统辞典,但具有更丰富的结构。每个节点对应一个同义词集 ,边表示上/下位词关系(上下级概念与从属概念的关系)
synset:同义词集,意义想相同的词(或“词条”)的集合。如car.n.01是car的第一个名词的意义,就是同义词集。
词条:同义词集和词的配对。
下一篇:NLTK阅读笔记Ⅱ