读研期间,短时 paper reading
What does the gradient represent?
2020.10.16
Motivation
The communication in distributed gradient descent. Dense << Sparse
Method
Gradient Dropping: removing the R% smallest gradients by absolute value
Result
Reduce 50x communication size,speed up 22%
Inspirer
Gradient value could show the importance of client/model
作者发现分布式机器学习中,梯度大多为稀疏的(大部分接近0),即意味着大部分客户端对梯度更新贡献很小,故可以通过剔除这部分梯度来提升通信效率。
对R%小的梯度值不进行通信,换而言之,只有满足条件的梯度才会进行通信。
实验结果证明,该方法能够在精度不变的前提下,减少50倍的通信规模,并且提升了22%的速度
这篇文章可以间接为受控共享学习中,之前的实验结果做一个解释,只接受梯度值较大的客户端,即表明该客户端的贡献较大。
问题:分布式机器学习的任务,数据可能都是来源同一个域内的,甚至就是相同的数据;从该文中的图来看,不能证明之前实验收敛速度加快的原因
Alham Fikri Aji and Kenneth Heafield. Sparse communication for distributed gradient descent. In Empirical Methods in Natural Language Processing (EMNLP), 2017.
Knowledge Distillation with SVD
2020.10.23
Knowledge Distillation (KD): Fully Connected Layers->L2 loss
KD-FSP: Feature Map->L2 loss
KD-SVD: Feature Map->SVD
KD-EID: KD-SVD(Adaptively)
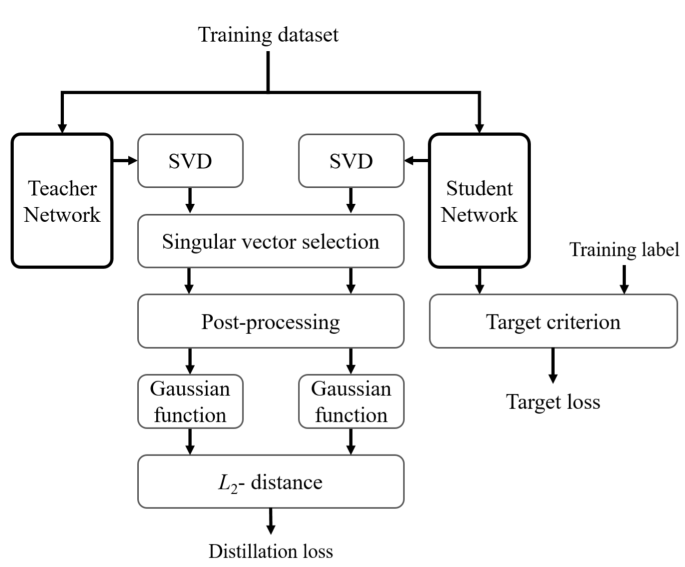
基于SVD对模型进行压缩的新改进。
首先对知识蒸馏进行简单的回顾,知识蒸馏是利用教师模型与学生模型在最后输出的全连接层上计算L2损失,以此来达到知识迁移、模型压缩、模型防御等目的。基于KD的改进之一,就是对教师与学生模型中的网络中间层的Feature Map进行损失计算。作者基于FSP此类思想,提出对Feature Map进行SVD,这样可以有效提取教师模型中的知识,更准确地传递给学生信息。
新发表的文章,则是对这种方法进行了改进,无需人工干预参数设计。实验证明该方法也是有效的(在TinyImageNet对比原始的学生模型提高了2.89%)。文章大部分内容都还是ECCV那篇文章的内容,增加的自适应部分是判断教师与学生模型的Feature Map大小差异,来决定使用SVD还是特征分解。
Lee S, Song B C. Knowledge Transfer via Decomposing Essential Information in Convolutional Neural Networks[J]. IEEE transactions on neural networks and learning systems.
Knowledge Distillation in Federated Learning
2020.10.30
Contributions
distillation framework for robust federated model fusion
CV/NLP datasets
heterogeneous models and/or data
Understanding
Generalization bound.
Source, diversity and size of the distillation dataset.
Distillation steps.
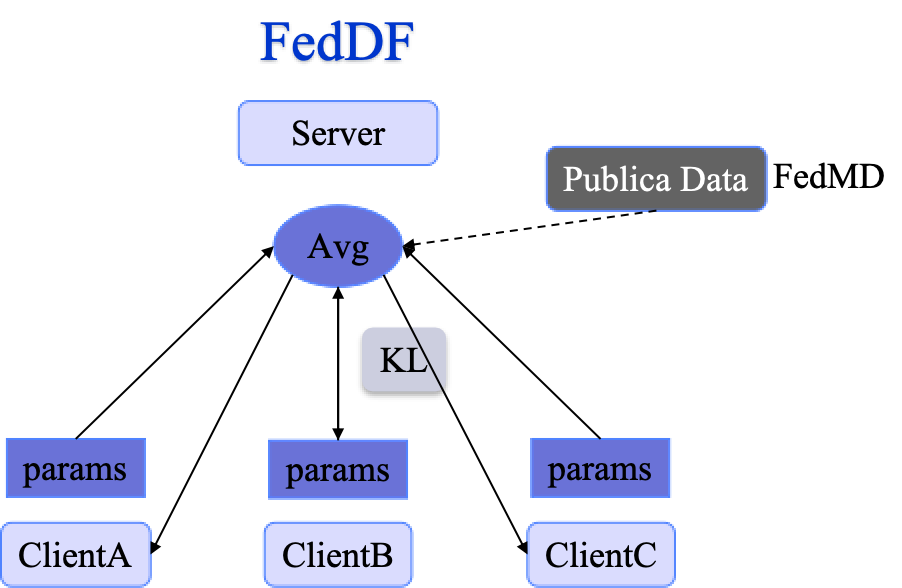
这篇文章是NIPS2020的工作,主要是基于知识蒸馏聚合的联邦学习。作者是来自洛桑联邦理工学院
主要贡献是提出了鲁棒性的联邦蒸馏框架,并且在CV和NLP任务上都得到了验证,还对异质模型,无标签数据等进行了大量实验。
右图是文章提出的算法(图是自己画的,原文并没有给方法图),首先是根据不同的客户端在本地训练得到梯度值后,上传至服务端进行聚合,后发回给客户端进行作为教师模型进行KL散度计算,对比于之前的FedMD的方法是不加入公开数据集部分。FedDF这个方法跟之前三室的一位师姐介绍在物联网中的应用,框架基本一致。
FedDF is designed for effective model fusion on the server, considering the accuracy of the global model on the test dataset.
FedDF是为了有效融合模型,考虑了全局模型在测试集上的准确性,所以未对一些实验进行比较(比如FedMD)。我觉得在找借口,FedMD是有这部分实验的。
文章为了辅助理解这个框架,还加入了泛化边界,数据集的分布与大小,蒸馏的实验(类似于消融实验)
Lin T, Kong L, Stich S U, et al. Ensemble Distillation for Robust Model Fusion in Federated Learning[J]. arXiv preprint arXiv:2006.07242, 2020.
洛桑联邦理工学院
FedDF Experiments
2020.12.04
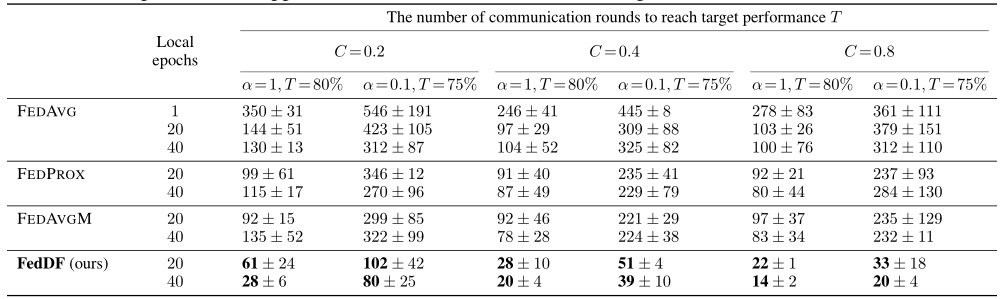
- 基本设置
- Local epochs(1、20、40)
- C(0.2、0.4、0.8)
- 达到目标性能T(0.8、0.75)
- 数据异质程度alpha(1、0.1)
- 固定设置
- 客户端数目:20
- 模型架构:Resnet-8
- 数据集:CIFAR-10
- 对比方法:FEDAVG、FEDPROX、FEDAVGM、FEDDF
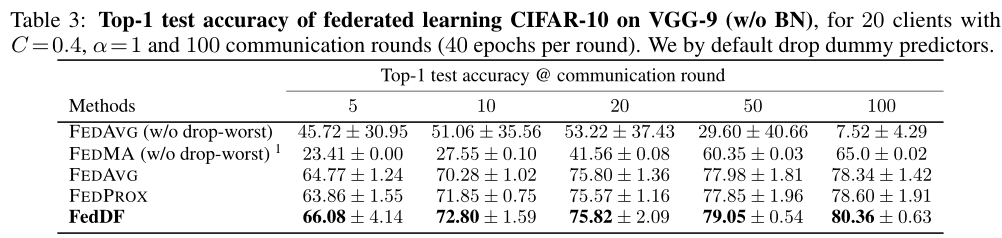

Lin T, Kong L, Stich S U, et al. Ensemble Distillation for Robust Model Fusion in Federated Learning[J]. arXiv preprint arXiv:2006.07242, 2020.
Ensemble Distillation for Robust Model Fusion in Federated Learning
2021.01.15
联邦学习——知识蒸馏
Zero-Shot(无标签): 利用公开数据集,训练GAN生成无标签的数据
常规迁移学习: 利用客户端模型分类层权重生成数据(Dirichlet分布)
噪声迁移学习: 差分隐私+联邦学习
SWA迁移学习: 在一般的优化器上增加SWA,可以提高性能
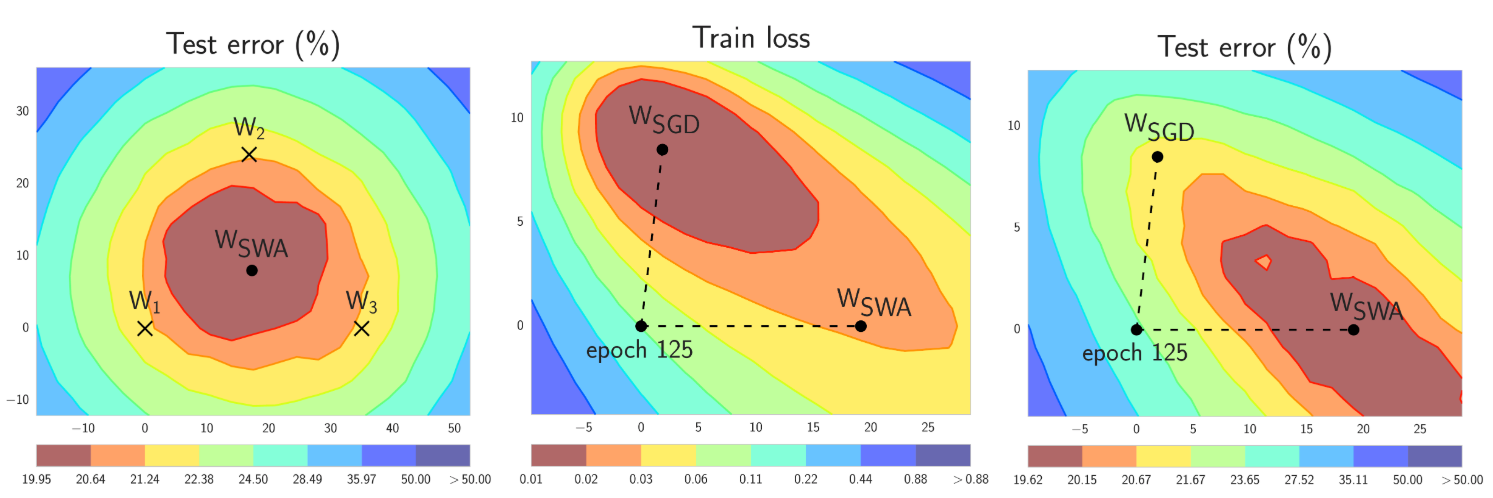
Dirichlet分布是Beta分布的多元推广。Beta分布是二项式分布的共轭分布,Dirichlet分布是多项式分布的共轭分布。通常情况下,我们说的分布都是关于某个参数的函数,把对应的参数换成一个函数(函数也可以理解成某分布的概率密度)就变成了关于函数的函数。于是,把Dirichlet分布里面的参数换成一个基分布就变成了一个关于分布的分布了。那么它就是Dirichlet过程了。
延伸阅读:Dirichlet分布;差分隐私+联邦学习;SWA
Lin T, Kong L, Stich S U, et al. Ensemble distillation for robust model fusion in federated learning[J]. arXiv preprint arXiv:2006.07242, 2020.
Group Knowledge Transfer:Federated Learning of Large CNNs at the Edge
2021.04.09
Background(Split Learning)
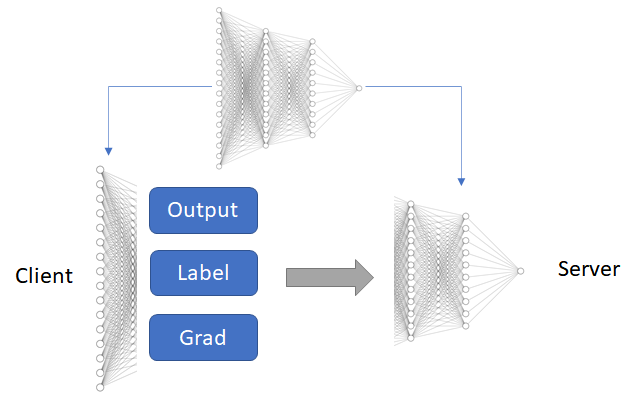
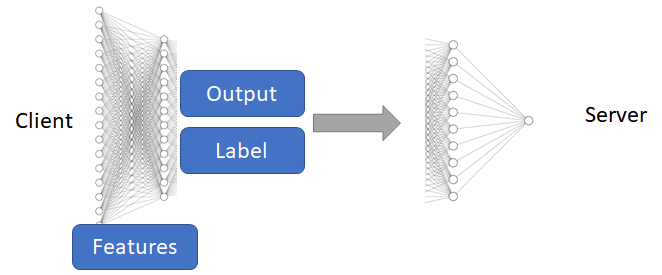
Method(Group Knowledge Transfer)
Performance Optimization for Federated Person Re-identification via Benchmark Analysis
2021.04.16
FedAVG不满足需求(不同分类),性能上也达不到(比本地训练精度低)
FedPAV满足了需求,但是对于性能上不能完成满足(小数据提升,大数据集下降,训练过程振荡)
FedPAV+KD满足需求,提升了性能,但是不稳定(性能不稳定,训练过程稳定)
- Trick:正则化
- Trick:Cosing Distance Weight
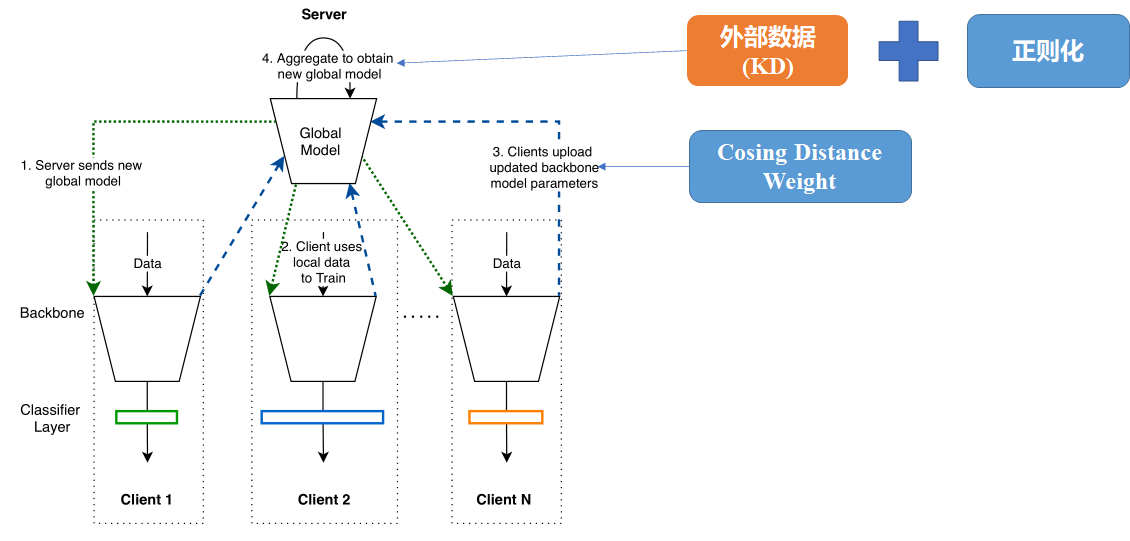
FedBN: Federated Learning on Non-IID Features via Local Batch Normalization
2021.04.23
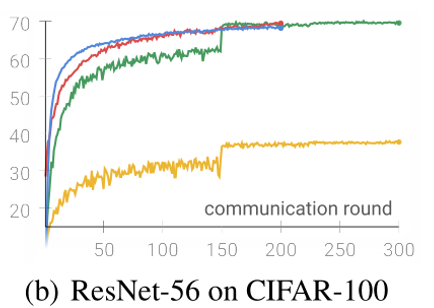
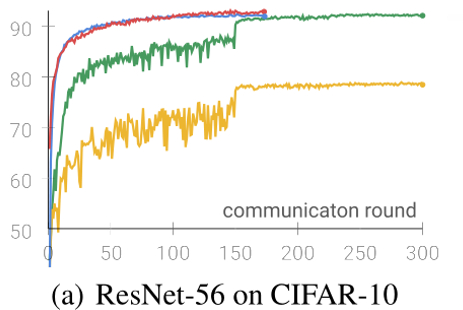
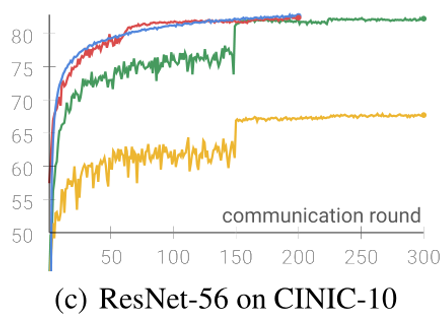
实验设计分析
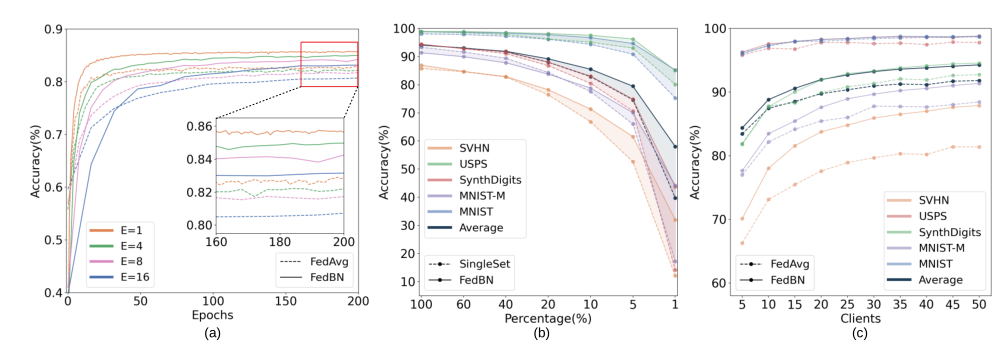
- 选定一个数据集,比较:本地训练轮数E,本地数据集大小,客户端数目(切割数据集数量)(左上角三张图)
- 可说明:收敛速度、E的影响,数据集大小影响,异质性影响
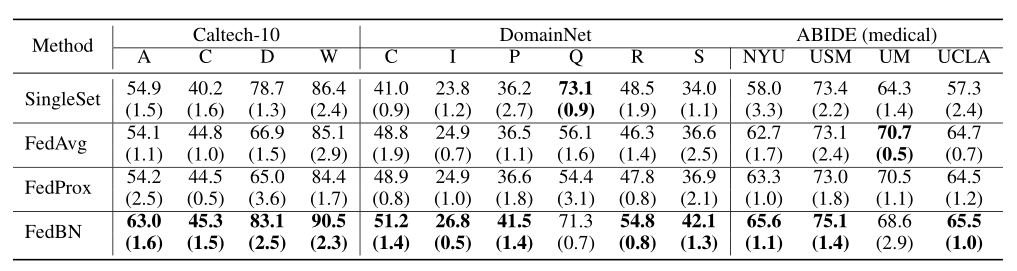
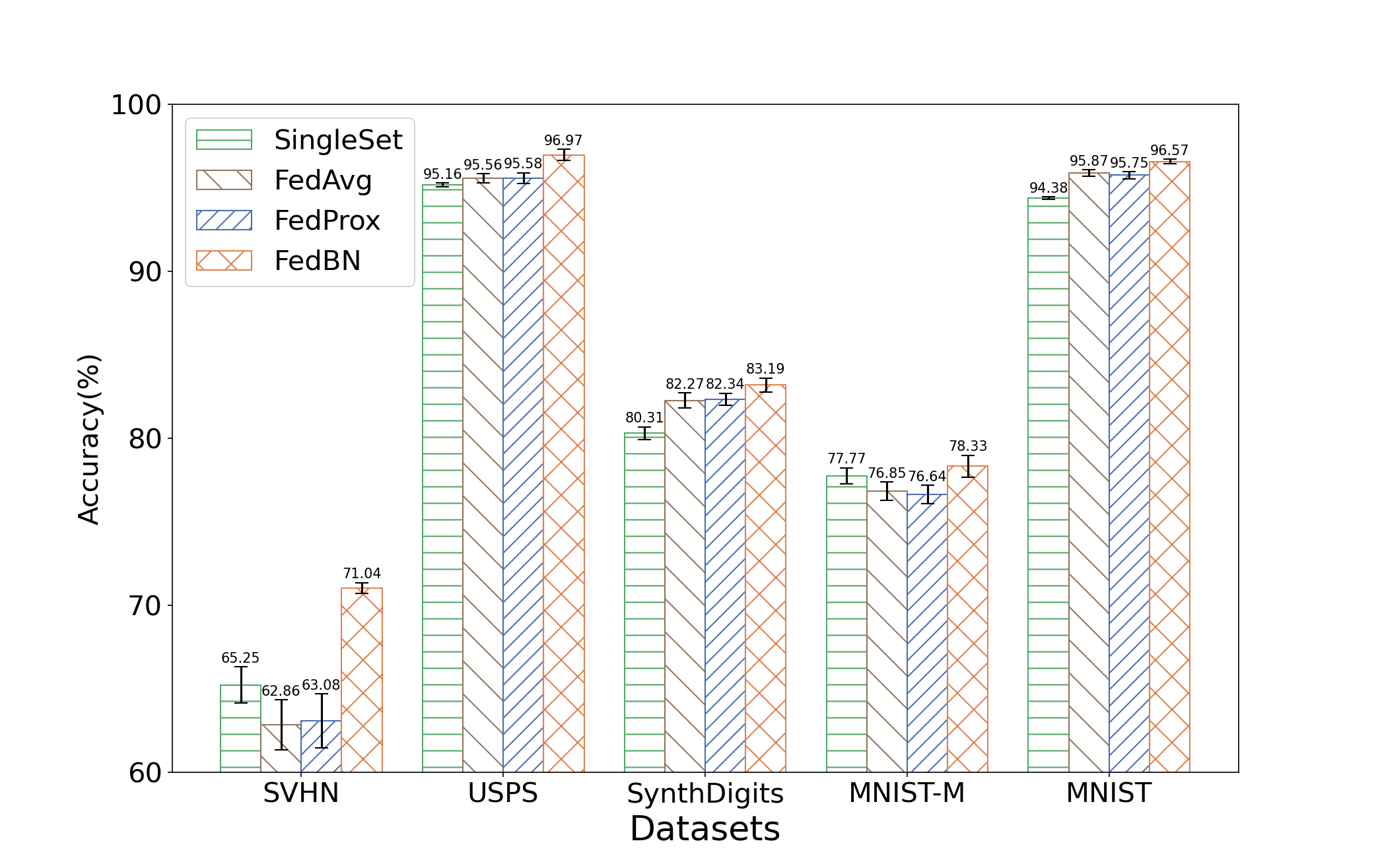
- 不同数据集进行比较。说明有效果(右上角一张图)
- 基于2,有效果再比较其他三种不同领域的任务。实验设置+实验分析(简要)
Adaptive Federated Optimization
2021.05.14
Problem
Standard federated optimization methods such as Federated Averaging (FedAvg) are often difficult to tune and exhibit unfavorable convergence behavior.
Inspired
In non-federated settings, adaptive optimization methods have had notable success in combating such issues.
Work
In this work, we propose federated versions of adaptive optimizers, including Adagrad, Adam, and Yogi, and analyze their convergence in the presence of heterogeneous data for general nonconvex settings.

Google: 2020 Feb-2020 Dec
Preservation of the Global Knowledge by Not-True Self Knowledge Distillation in Federated Learning
2021.06.18
动机
Catastrophic Forgetting: feature shifting induced fitting on biased local
研究
训练方式: 本地自蒸馏(LSD)
\[ \tilde{q}_{\tau}(c)=\frac{\exp(z_{c}/\tau)}{\sum_{i=1,i\neq y}^{C}\exp(z_{i}/\tau)} \]
\[ \tilde{q}^g_{\tau}(c)=\frac{\exp(z^g_{c}/\tau)}{\sum_{i=1,i\neq y}^{C}\exp(z^g_{i}/\tau)} \]
\[ (\forall c\neq y) \]
二次改进: Not-True Distillation
\[\mathcal{L}_{\mathrm{NTD}}(\tilde{q}_{\tau},\tilde{q}_{\tau}^{g})=-\sum_{c=1,c\neq y}^{C}\tilde{q}_{\tau}^{g}(c)\log\left(\frac{\tilde{q}_{\tau}(c)}{\tilde{q}_{\tau}^{g}(c)}\right)\]
有偏局部特征转移诱导拟合
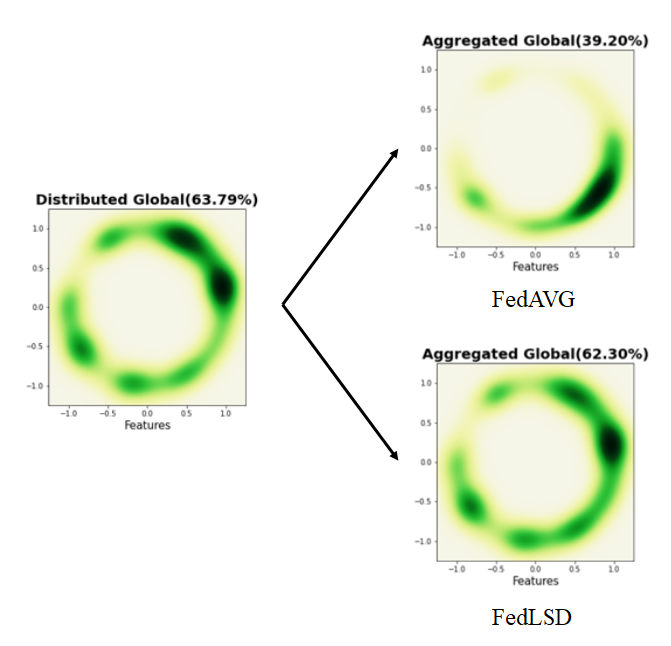
遗忘灾难:把CIFAR10输入拉成二维,在进行100轮联邦学习后,估计数据的概率密度函数,上图这个分布存在明显偏差;提出的方法基本无偏差
研究方法:将传统的训练,改成了蒸馏的方式(由于是模型架构相同,所以可以叫做自蒸馏),也在本地进行蒸馏;另外,基于IJCAJ2021知识蒸馏的工作,对教师模型预测正确的标签剔除,再KL散度计算,以进行改进。
Taehyeon Kim, Jaehoon Oh, NakYil Kim, Sangwook Cho, and Se-Young Yun. Comparingkullback-leibler divergence and mean squared error loss in knowledge distillation.arXiv preprintarXiv:2105.08919, 2021.
Preservation of the Global Knowledge by Not-TrueSelf Knowledge Distillation in Federated Learning
2021.06.25
利用知识蒸馏保留旧任务的知识
\[{\mathcal{L}}_{\mathrm{FedLSD}}=(1-\beta)\cdot{\mathcal{L}}_{\mathrm{CE}}(q,\;p_{y})+\beta\cdot{\mathcal{L}}_{\mathrm{LSD}}(q_{\tau},\;q_{\tau}^{y})\quad(0<\beta<1)\;\]
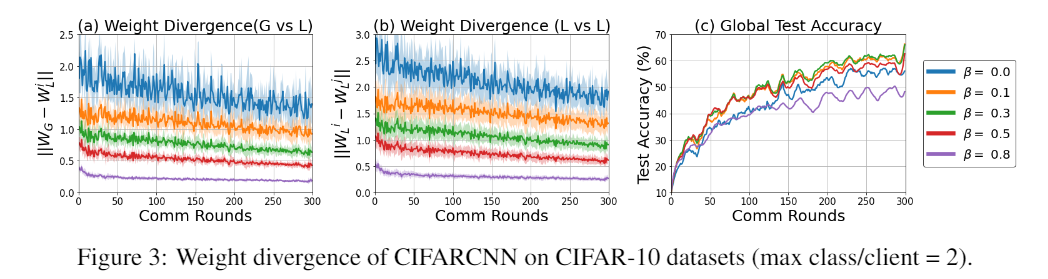
Weight divergence
\[\rm{weight\,divergence}=||w^{F e d A v g}-w^{S G D}||/||w^{S G D}||\]
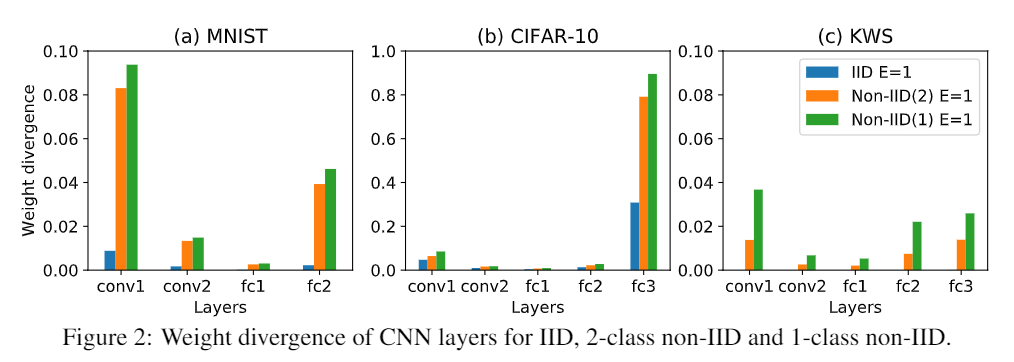
全局模型的预测可以作为先前数据分布的参考,从而产生类似于在CL中使用情景记忆的效果。
beta是指KL散度损失的权重
结果表明,数据分布的正确性,即数据分布的偏态性,可能影响数据的准确性。
Zhao Y, Li M, Lai L, et al. Federated learning with non-iid data[J]. arXiv preprint arXiv:1806.00582, 2018.
Learn distributed GAN with Temporary Discriminators
2021.07.02
研究动机:医疗领域,利用本地的隐私数据进行数据增强
https://github.com/huiqu18/TDGAN-PyTorch
Personalized Federated Learning with Theoretical Guarantees: A Model-Agnostic Meta-Learning Approach
2021.07.16
动机
联邦学习+元学习->个性化联邦学习(Per-FedAVG) 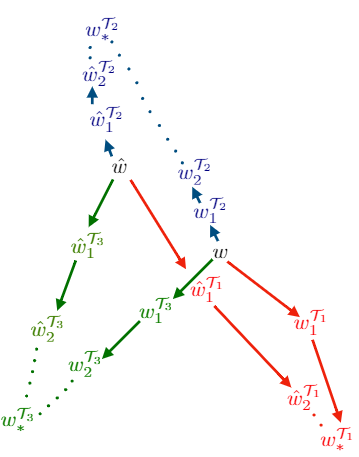
元学习——MAML
\[w_{k+1}\leftarrow w_{k}-(\beta_{k}/B)\sum_{i\in B_{k}}\bar{\nabla}f_{i}(w_{k+1}^{i},\mathcal{D}_{o}^{i})\]
First-Order
\[w_{k+1}=w_{k}-{\frac{\beta_{k}}{\mathcal{B}}}\sum_{i\in{B_{k}}}\left[\tilde{\nabla}f_{i}\Bigl(w_{k}-\alpha\tilde{\nabla}f_{i}(w_{k},D_{i n}^{i}),D_{o}^{i}\right)-\alpha d_{k}^{i}]\]
Hessian-Free
\[w_{k+1}=w_{k}-\beta_{k}{\frac{1}{B}}\sum_{i\in{\mathcal{B}_{k}}}\left(I-\alpha\tilde{\nabla}^{2}f_{i}(w_{k},\mathcal{D}_{h}^{i})\right)\tilde{\nabla}f_{i}(w_{k+1}^{i},D_{o}^{i})\]
这篇论文是发表在NIPS2020,是关于个性化联邦学习的文章。作者来自于MIT的LIDS团队。文章主要是通过统计优化角度的层面对问题进行分析,并给予理论分析与实验结果证明方法的有效性。
从元学习的角度来分析这篇文章,作者是同一批人。他们首先提出了MAML这种元学习的方法,右侧图,w 的hat,是提出的问题建模。从w hat开始训练,更容易适用于大部分任务。即原始公式
根据原始公式,得到两种近似,一阶形式,与海森形式(二阶)。
Alireza Fallah, Aryan Mokhtari, Asuman Ozdaglar. Personalized Federated Learning with Theoretical Guarantees: A Model-Agnostic Meta-Learning Approach. In Advances in Neural Information Processing Systems (NIPS), 2020(33): 3557–3568.
Distilled One-Shot Federated Learning
2021.08.20
动机
Solve the communication challenges of FL
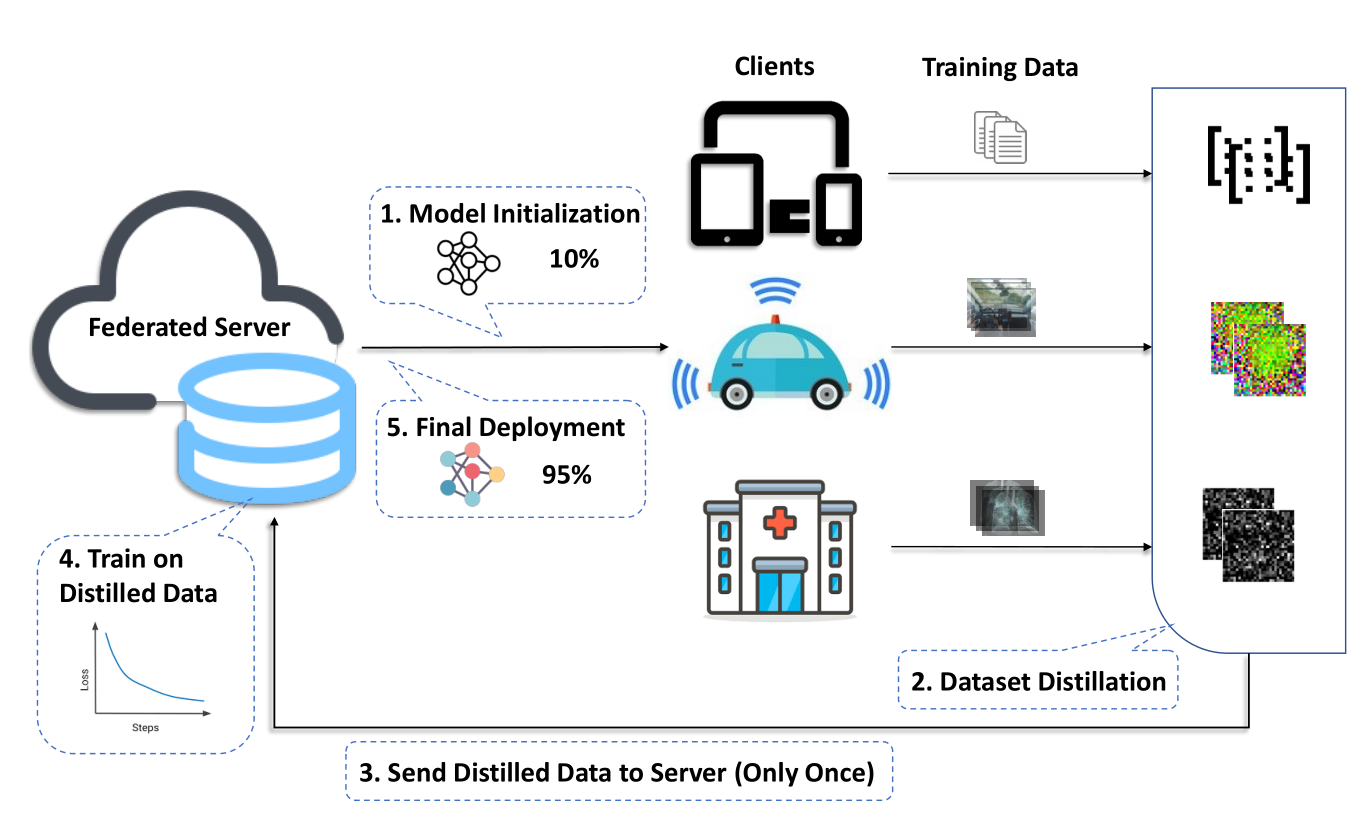
方法
- Clients: datasets distillation
- Send distilled data
- Server train
- Parallel: hard resets + randomly adjusts (slow)
- Serial: one by one distillated
实验
- Image Classification
- MNIST: LeNet
- Text Classification
- IMDB: TextCNN
- TREC-6: Bi-LSTM
- SENT140: TextCNN
由于有大量蒸馏的数据,不能直接进行聚合。所以有串行与并行两种解决方案。
数据蒸馏:不能在没有resets的模型中直接训练,否则无法达到较好的精度
hard resets: 强制初始化模型参数
randomly adjusts: 在每次学习过程中,进行随机的调整
Random masking randomly selects a fraction p_{rm} of the distilled data at each training iteration andreplaces it with a random tensor.
NSF Center for Big Learning University of Florida
Zhou Y, Pu G, Ma X, et al. Distilled one-shot federated learning[J]. arXiv preprint arXiv:2009.07999, 2020.
Does Knowledge Distillation Really Work?
2021.08.27
Agreement and Fidelity
\[{\mathrm{Average~Predictive~KL}}:=\frac{1}{n}\sum_{i=1}^{n}{\mathrm{KL}}\left(\hat{p}_{t}({\bf y}|{\bf x}_{i})\mid\right|\hat{p}_{s}({\bf y}|{\bf x}_{i}))\]
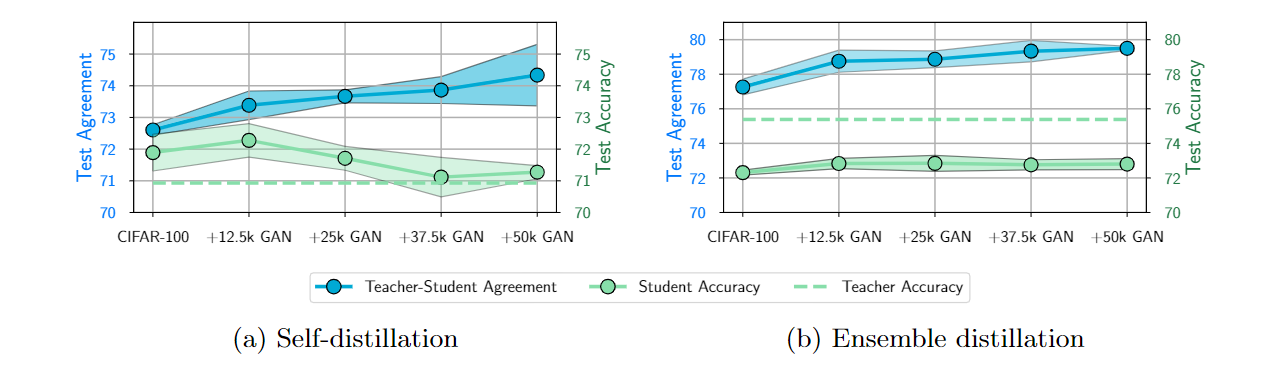
Generalization vs Fidelity
- SD: Data ⬆ Fidelity ⬆, Accuracy ⬇
- ED: Data ⬆ Fidelity ⬆, Accuracy ⬆
Why Low Fidelity
- Architecture: ResNet \(\sqrt{}\) ; VGG \(\times\)
- Student Capacity: \(\times\)
- Identifiability:distillation dataset \(\neq\) test dataset
- Optimization:\(\sqrt{}\)
知识蒸馏在深度学习中被广泛应用,但其是否真的有效?简单来说,KD确实有效,能够提升学生网络模型的性能;然而教师往往只能传递有限的知识给学生。 文章提出了一个新的名词Agreement,或者说Fidelity,即教师与学生对于数据的预测相似度。
为什么要提出一个新的概念,根据图1中的实验结果
为什么会有更低的保真度
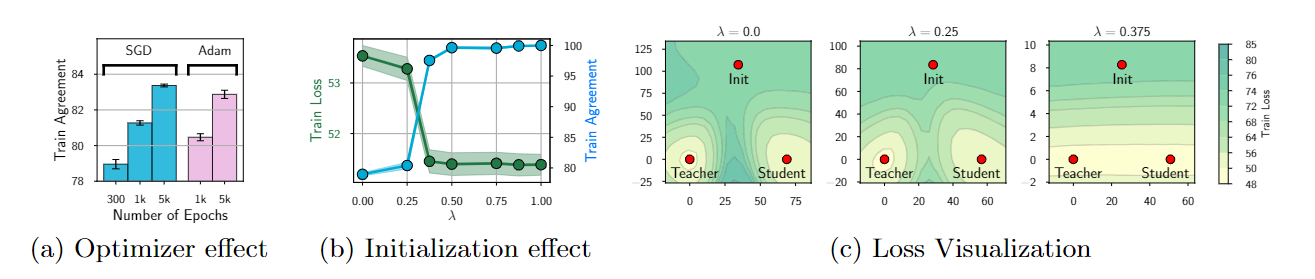
优化器。随着epoch的增加,一致性增加
初始化。教师权重+随机权重,lambda比值,越大表示趋近于教师
我们发现,如果学生的初始化距离教师很远(λ≤0.25),优化器会收敛到蒸馏损失的次优值,从而产生与教师明显不同的学生。然而在λ= 0.375 处有一个突然的变化。最终的训练损失下降到最优值并且一致性急剧增加,并且行为继续 λ >0.375。为了进一步研究,在图 6 (c) 中,我们将 λ∈ {0,0.25,0.375} 的蒸馏损失表面可视化,投影在与 θt 相交的二维子空间、初始学生权重和最终学生权重上。如果学生初始化离老师很远(λ∈{0,0.25}),它会收敛到损失表面的一个不同的、次优的盆地。另一方面,当初始化接近于老师(λ= 0.375)时,学生收敛到与老师相同的盆地,达到接近 100% 的一致性
我们终于确定了之前所有干预措施无效的根本原因。知识蒸馏无法收敛到最佳学生参数,即使我们知道一个解决方案并在优化方向上给初始化一个小的开端。事实上,虽然可识别性可能是一个问题,但为了在所有输入上匹配教师,学生有 至少在用于蒸馏的数据上匹配老师,并实现蒸馏损失的接近最优值。在实践中,优化收敛到次优解,导致蒸馏保真度不佳
Google Research
Stanton S, Izmailov P, Kirichenko P, et al. Does Knowledge Distillation Really Work?[J]. arXiv preprint arXiv:2106.05945, 2021.
Model-Contrastive Federated Learning
2021.09.18
Motivation
A key challenge in federated learning is to handle the heterogeneity of local data distribution across parties Method
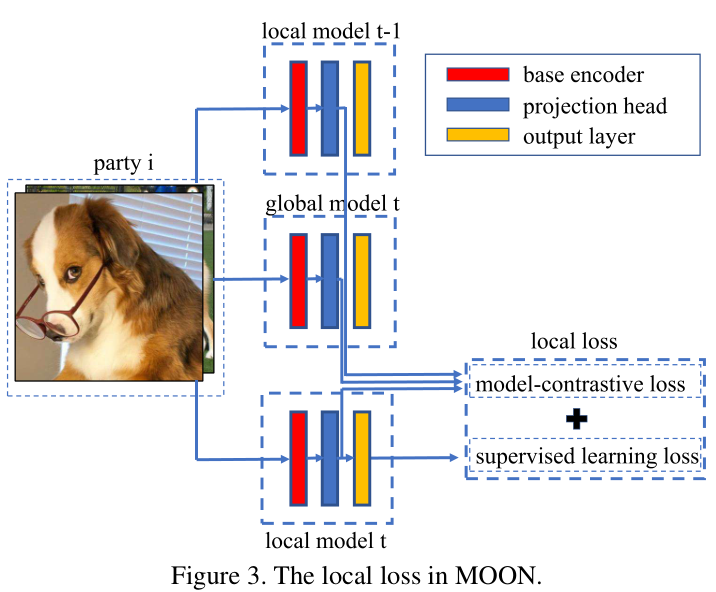
Method
\[\ell_{c o n}=-\log\frac{\exp(\mathrm{sim}(z,z_{g l o b})/\tau)}{\exp(\mathrm{sim}(z,z_{g l o b})/\tau)+\exp(\mathrm{sim}(z,z_{p r e e v})/\tau)}\]
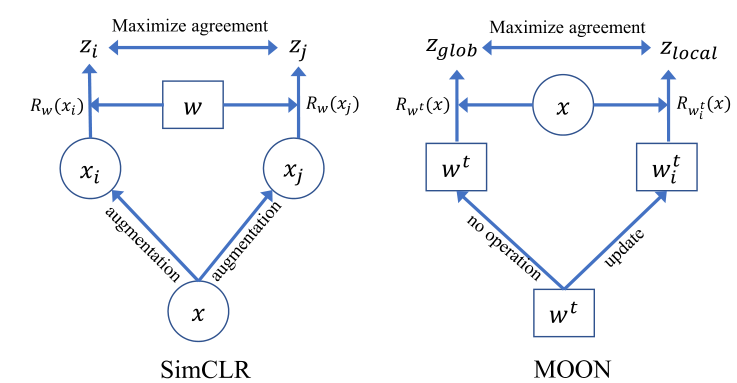
UC Berkeley
Li Q, He B, Song D. Model-Contrastive Federated Learning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 10713-10722.
Data-Free Knowledge Distillation for Heterogeneous Federated Learning
2021.09.27
Motivation
The ensemble knowledge is not fully utilized to guide local model learning, which mayin turn affect the quality of the aggregated model.
Method
\[\operatorname*{min}_{\theta}\operatorname*{lim}_{x\rightarrow\hat{\mathcal{D}}_{\mathrm{p}}}\left[D_{\mathrm{KL}}[\sigma(\frac{1}{K}\sum_{k=1}^{K}g(f(x;\theta_{k}^{f});\theta_{k}^{p})]|\sigma(g(f(x;\theta^{f});\theta^{p})]\right].\]
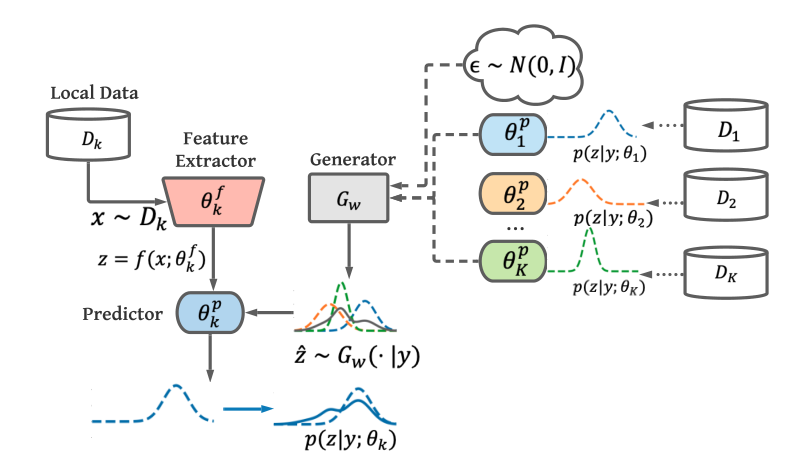

Michigan State University
Zhuangdi Zhu and Junyuan Hong and Jiayu Zhou. 2021. Data-Free Knowledge Distillation for Heterogeneous Federated Learning. In ICML, 139:12878-12889.
Beyond Sharing Weights for Deep Domain Adaptation
2021.10.18
Motivation
Learn features that are invariant to the domain shift.
Method
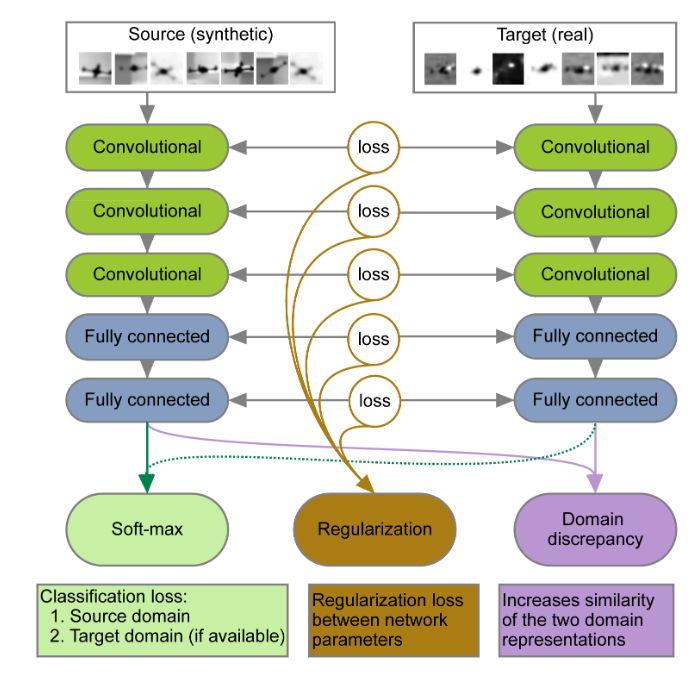
\[L(\theta^{s},\theta^{t}|{\bf X}^{s},{Y}^{s},{\bf X}^{t},{Y}^{t})=L_{s}+L_{t}+L_{w}+L_{M M D}\]
\[{\cal L}_{s}\,=\,{\frac{1}{N^{s}}}\,\sum_{i=1}^{N^{\circ}}c(\theta^{s}|{\bf x}_{i}^{s},y_{i}^{s})\]
\[{\cal L}_{t}=\frac{1}{N_{l}^{t}}\sum_{i=1}^{N_{l}^{t}}c(\theta^{t}|{\bf x}_{i}^{t},y_{i}^{t})\]
\[{\cal L}_{w}=\lambda_{w}\sum_{j\in\Omega}r_{w}(\theta_{j}^{s},\theta_{j}^{t})\]
\[{\cal L}_{M M D}=\lambda_{u}r_{u}(\theta^{s},\theta^{t}|{\bf X}^{s},{\bf X}^{t})\]
Discussion
It therefore seems reasonable that thehigher layers of the network, which encode higher-level in-formation, should be domain-specific.
Rozantsev, A., Salzmann, M., & Fua, P. (2019). Beyond Sharing Weights for Deep Domain Adaptation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 41(4), 801-814.
FedDG: Federated Domain Generalization on Medical Image Segmentation via Episodic Learning in Continuous Frequency Space
2021.10.25
Motivation
Aims to learn a federated model from multiple distributed source domains such that it can directly generalize to unseen target domains.
Method
- 傅立叶:Amplitude Spectrum + Phase Spectrum
\[ \begin{array}{l} {\cal F}(x_{i}^{k})(u,v,c)=\sum\limits_{h=0}^{H-1}\sum\limits_{w=0}^{W-1}x_{i}^{k}(h,w,c)e^{-j2\pi({\frac{h}{H}}u+{\frac{v}{W}}v)} \end{array} \]
- InfoNCE
\[ \ell(h_{m},h_{p})=-l o g\frac{e x p(h_{m} \odot h_{p}/\tau)}{\sum_{q=1,q\neq m}^{2K}\mathbb{F}(h_{m},h_{q})\cdot e x p(h_{m}\ \odot h_{q}/\tau)} \]
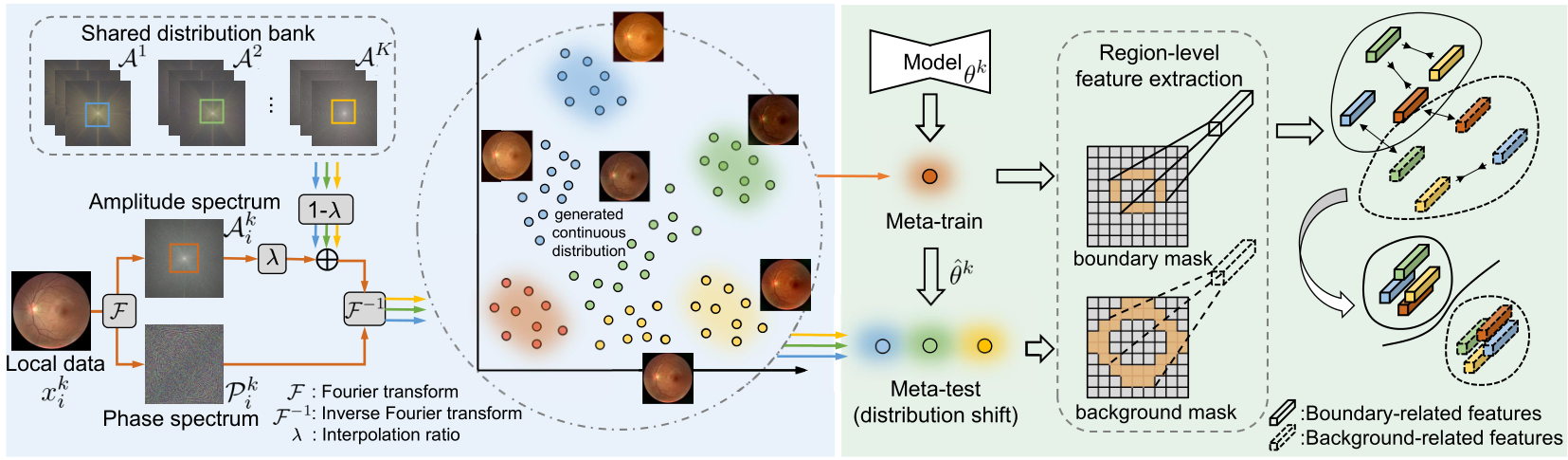
Method
- Data
- Step 1:对每个客户端的数据都做如右处理
- Step
2:客户端k的图像X,与傅里叶变换后的数据A(联合任意两个客户端的A)
- 对X进行傅里叶变换
- 把X的振幅分量中的低频分量换为A的低频分量, low_freq_mutate
- 最后结合A,做逆傅里叶变换,得到新的图像X’
- Train
- Loss1: 根据原始图像X做训练。先利用这里的梯度计算梯度下降后的模型参数F’
- Loss2: 根据F’对X’的输出计算
- Loss3: F与F’ 分别提取mask的边界与背景 (ndimage.binary_erosion)做对比学习NTXentLoss,loss3*0.1
解决从多个分布域中学习的问题->数据异质问题
一般的深度学习中,数据是共享的,所以可以直接进行跨域学习。然而在联邦学习中,数据并不支持直接共享,所以从数据分布角度入手。从原始图像中抽取中分布(风格)信息,并把这个信息共享出来。这里假设通过这个分布信息无法还原真实数据。How?
通过傅里叶变换,把数据转换为:振幅谱+相位谱。下图的蓝色背景部分,通过公式进行转换后,再把各个客户端的信息数据进行汇总学习。
由于训练背景是医学图像处理,涉及到语义分割,所以需要使用常规的分割损失函数。再考虑图形的边界与背景,对应右边的绿色部分,采用InfoNCE损失函数 对边界与背景做提取处理,计算InfoNCE损失。hm,hp表示同一类的正面特征,表示边界与背景。
所以整个训练过程就是利用傅里叶变换提取分布信息,结合一般的分割与InfoNCE损失进行训练。主要的创新点在傅里叶变换提取了可共享的信息。下一次再进行具体的方法介绍。
CUHK, 香港中文大学
Liu Q, Chen C, Qin J, et al. Feddg: Federated domain generalization on medical image segmentation via episodic learning in continuous frequency space. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 1013-1023.
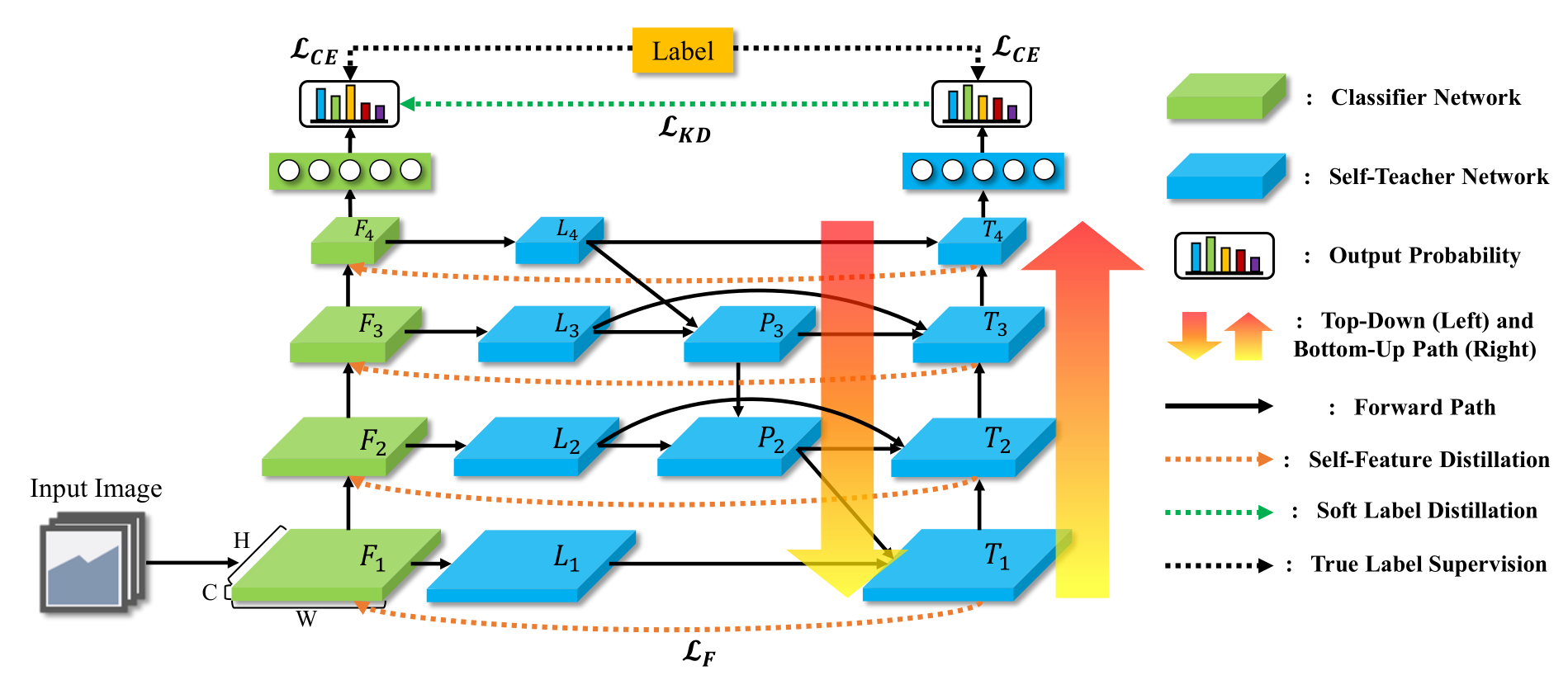
Refine Myself by Teaching Myself : Feature Refinement via Self-Knowledge Distillation
2021.11.11
Method
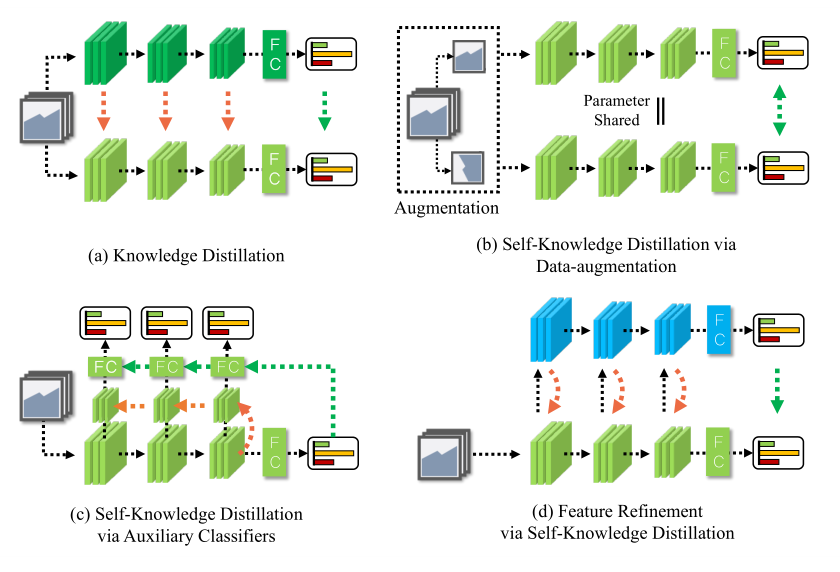
\[ \begin{array}{l} \mathcal{L}_{FRSKD}(\textbf{x},y;\theta_{c},\theta_{t},K) = \mathcal{L}_{CE}(\textbf{x},y;\theta_{c})+\mathcal{L}_{C E}(\textbf{x},y;\theta_{t}) +\alpha\cdot\mathcal{L}_{KD}(\textbf{x};\theta_{c},\theta_{t},K)+\beta\cdot\mathcal{L}_{F}(T,F;\theta_{c},\theta_{t}) \end{array} \]
\[\mathcal{L}_{F}(T,F;\theta_{c},\theta_{t})=\Sigma_{i=1}^{n}\vert\vert\phi(T_{i})-\phi(F_{i})\vert\vert_2\]
Result
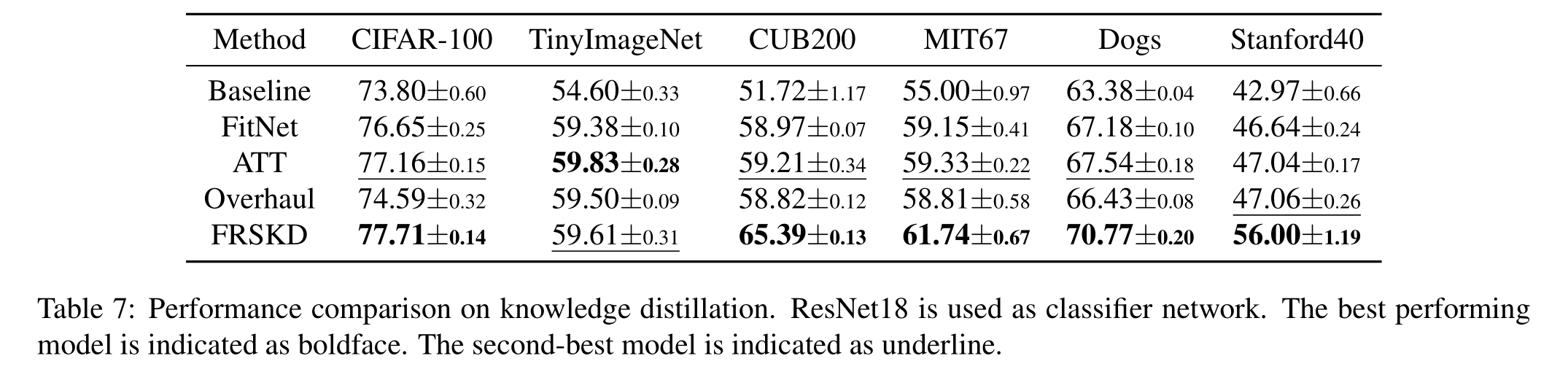
https://github.com/MingiJi/FRSKD
Ji M, Shin S, Hwang S, et al. Refine Myself by Teaching Myself: Feature Refinement via Self-Knowledge Distillation. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 10664-10673.
No Fear of Heterogeneity: Classifier Calibration for Federated Learning with Non-IID Data
2021.11.25
Motivation
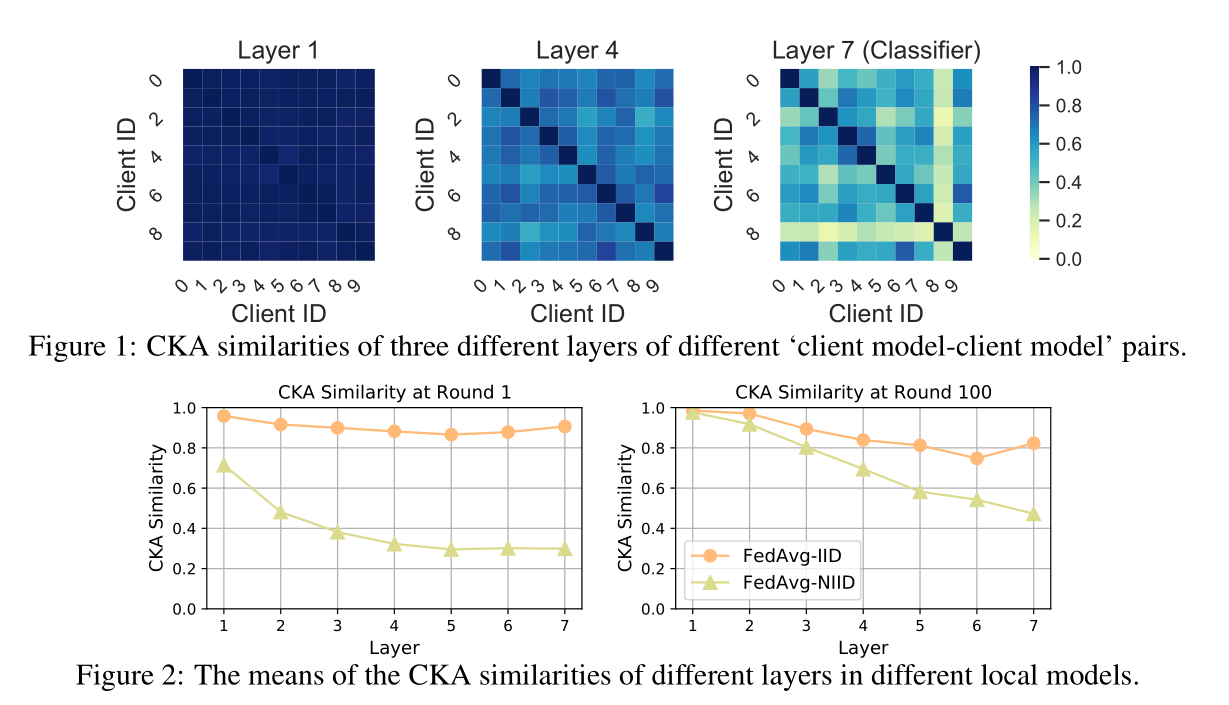
Method
\[\mu_{c,k}=\frac{1}{N_{c,k}}\sum_{j=1}^{N_{c,k}}z_{c,k,j},\quad\Sigma_{c,k}=\frac{1}{N_{c,k}-1}\sum_{j=1}^{N_{c,k}}\left(z_{c,k,j}-\mu_{c,k}\right)\left(z_{c,k,j}-\mu_{c,k}\right)^{T}\]

Result
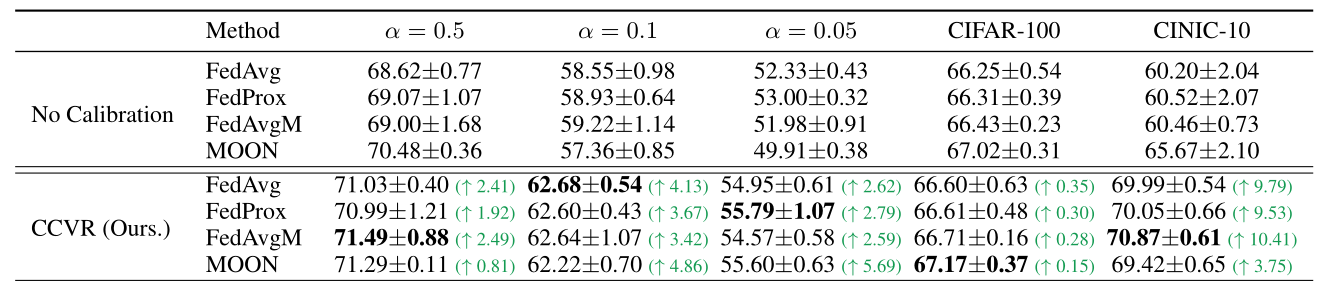
Luo M, Chen F, Hu D, et al. No Fear of Heterogeneity: Classifier Calibration for Federated Learning with Non-IID Data[J]. arXiv preprint arXiv:2106.05001, 2021.
Federated Learning with Personalization Layers
2021.12.02
Method
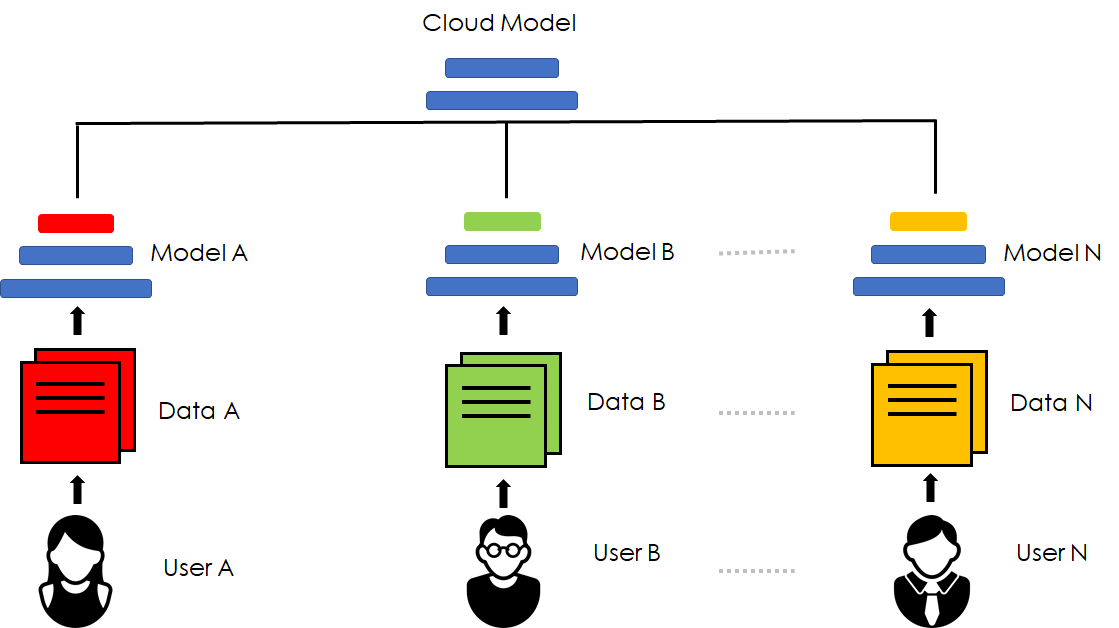
Personalized population risk
\[ \begin{array}{l} L^{PR}({\bf W}_{B},{\bf W}_{P_{1}},...,{\bf W}_{P_{N}})=\frac{1}{N}\sum\limits_{j=1}^{N}\mathbb{E}_{({\bf x},y)\sim P_{j}} [l(y,f({\bf x};{\bf W}_B,{\bf W}_{P_j}))] \end{array} \]
Empirical risk
\[L_{j}^{E R}\big(\displaystyle\mathrm{W}_B,\displaystyle\mathrm{W}_{P}\big)\triangleq\frac{1}{n_{j}}\sum_{i=1}^{n_{j}}l(y_{j,i},f\big(x_{j,i};\displaystyle\mathrm{W}_B,\displaystyle\mathrm{W}_{P}\big)\big)\]

Manoj Ghuhan Arivazhagan, Vinay Aggarwal, Aaditya Kumar Singh, and Sunav Choudhary. 2019. Federated learning with personalization layers. arXiv preprint arXiv:1912.00818 (2019).
Federated Split Vision Transformer for COVID-19 CXR Diagnosis using Task-Agnostic Training
2021.12.09
Motivation
融合联邦学习与分割学习尽可能发挥他们的独特优势
Method

Park S, Kim G, Kim J, et al. Federated Split Vision Transformer for COVID-19 CXR Diagnosis using Task-Agnostic Training[J]. arXiv preprint arXiv:2111.01338, 2021.
Local Learning Matters: Rethinking Data Heterogeneity in Federated Learning
2022.03.18
Contribution
Focus on local learning generality rather than proximal restriction
Method
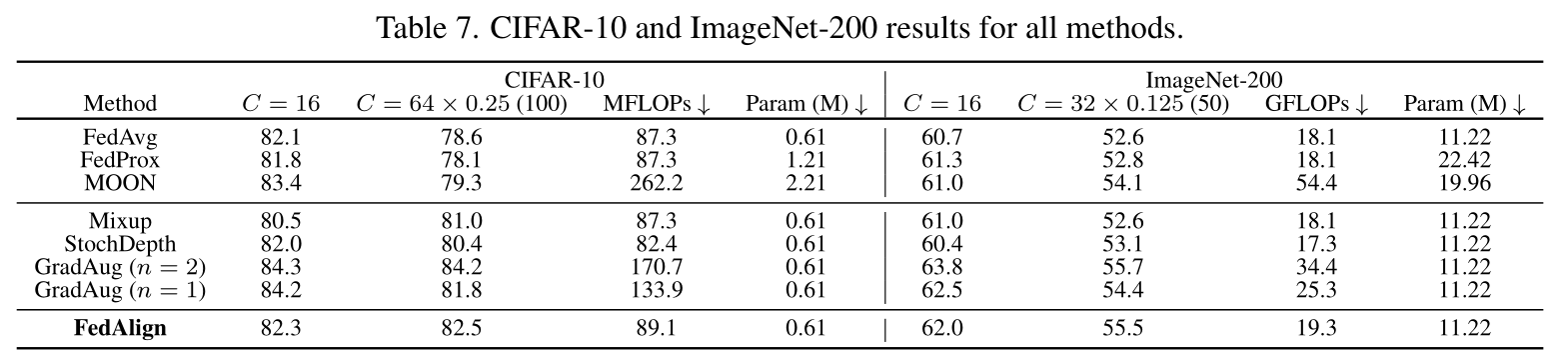
Stochastic Depth (2016)
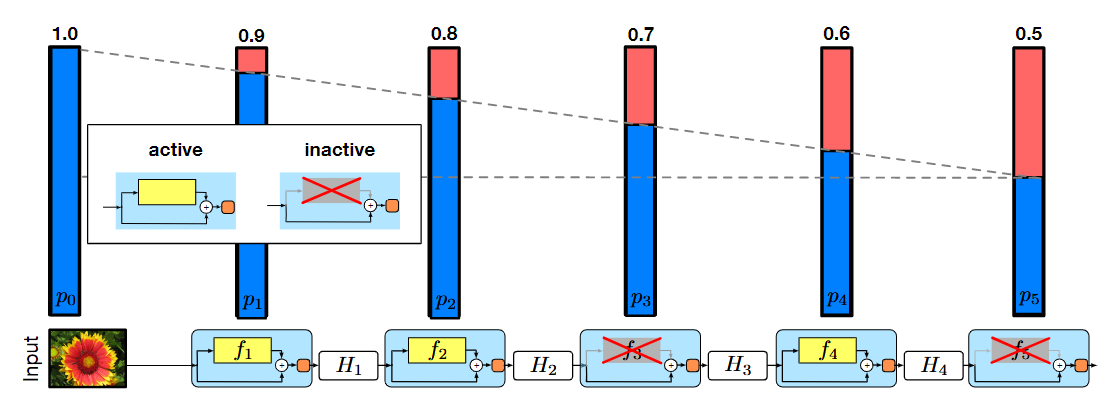
1 | if not self.training or torch.rand(1)[0] >= self.death_rate: |
Mixup (2018)
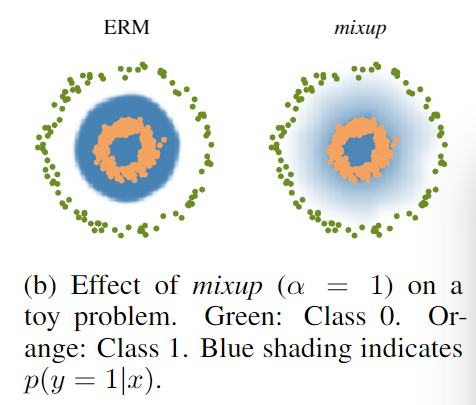
1 | index = torch.randperm(batch_size) |
GradAug (2020)

Random number of channels in each layer
University of Central Florida
Mendieta M, Yang T, Wang P, et al. Local Learning Matters: Rethinking Data Heterogeneity in Federated Learning[J]. arXiv preprint arXiv:2111.14213, 2021.
Local Learning Matters: Rethinking Data Heterogeneity in Federated Learning
2022.03.25
Motivation
Promote smooth optimization and consistency within the model
Reduce computation in a purposeful manner
Method
Untrained network in place of the traditional logit-based loss
Reuse the intermediate features of the full network
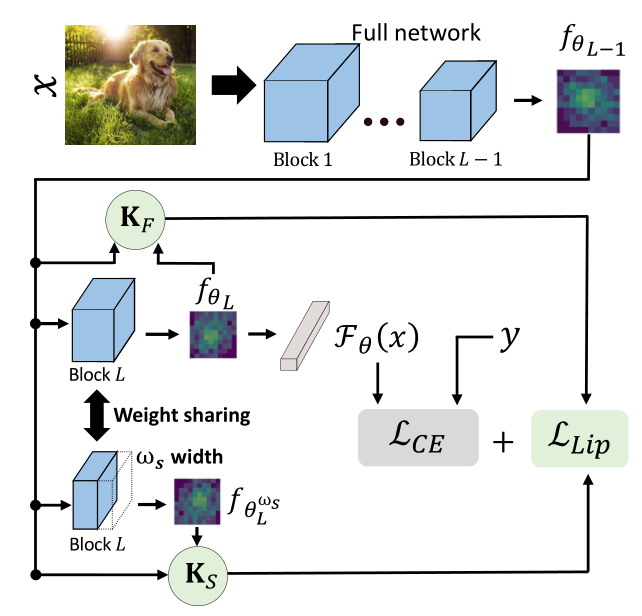
Result
University of Central Florida
Mendieta M, Yang T, Wang P, et al. Local Learning Matters: Rethinking Data Heterogeneity in Federated Learning[J]. arXiv preprint arXiv:2111.14213, 2021.
Motion Representations for Articulated Animation
2022.04.15
问题
- 输入:图片与视频
- 目标:图片中的目标“动”起来
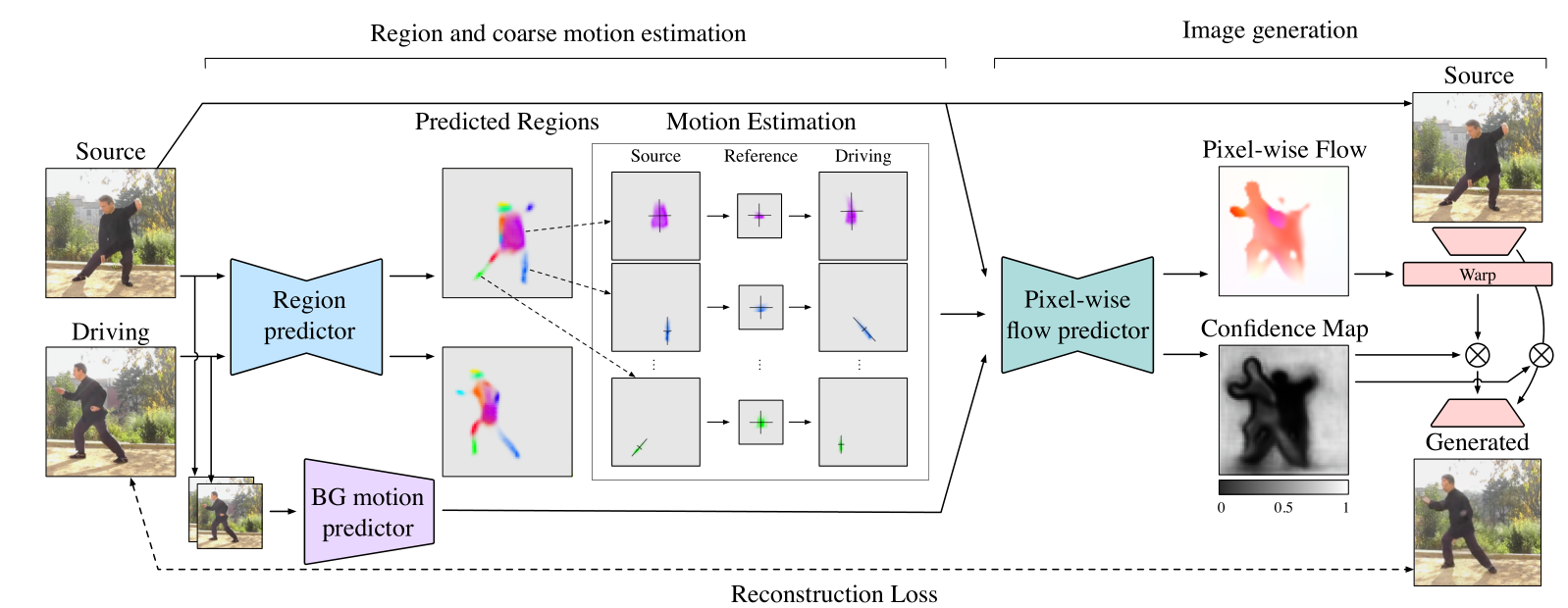
- 挑战:目标与背景提取;视频帧与帧之间的关联 ## 建模:
- 对图片与每帧视频进行粗估计,提取驱动的目标
- AutoEncoder(AE):提取图片的feature map(FM)
- 单层卷积:根据FM提取驱动的目标区域(限定好区域大小),R_p, V_p
- 计算仿射参数(PCA 或 Jacobian)
- 若干层下采样+单层全连接(特征点数)(拼接后输入)
- 图片生成(细粒度)
- 原图:Block(卷积+下采样)+ResBlock
- AE+卷积(区域数)
- 上采样+卷积
结果

University of Trento, Italy
Siarohin, Aliaksandr, Oliver, Woodford, Jian, Ren, Menglei, Chai, and Sergey, Tulyakov. "Motion Representations for Articulated Animation." . In CVPR.2021.
Communication-efficient federated learning via knowledge distillation
2022.05.06
Method
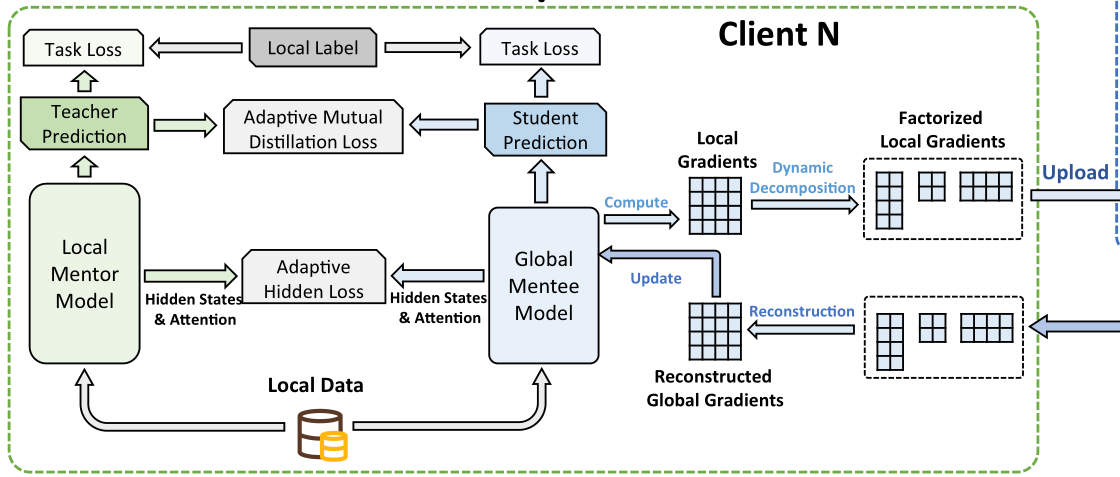
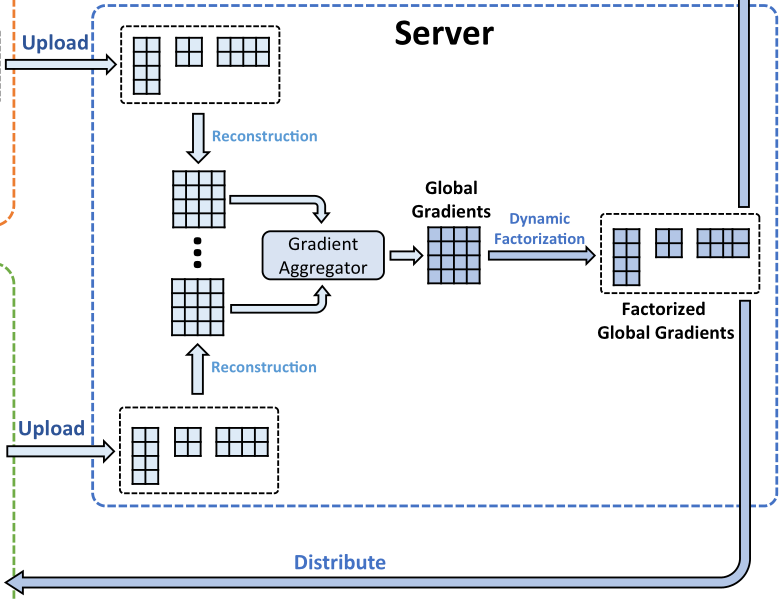
SVD energy 随着轮数增加,阈值需要增大,即重要的知识越来越多
\[{\mathcal L}_{t,i}^{d}=\frac{\mathrm{KL}({\bf y}_{i}^{s}{\bf y}_{i}^{t})}{\mathcal{L}_{t,i}^{t}+\mathcal{L}_{s,i}^{t}}\]
\[\mathcal{L}_{t,i}^{t}=\mathrm{CE}(\mathrm{y}_{i},\mathrm{y}_{i}^{t})\]
\[\mathcal{L}_{t,i}^{h}=\mathcal{L}_{s,i}^{h}=\frac{\mathrm{MSE}({\mathbf H}_i^t,{\mathbf W}_{i}^{h}H^{s})+\mathrm{MSE}({\bf A}_{i}^{t},{\bf A}^{s})}{\mathcal{L}_{t,i}^{t}+\mathcal{L}_{s,i}^{t}}\]
\[T(t)=T_{\mathrm{start}}+(T_{\mathrm{end}}-T_{\mathrm{start}})t,t\in[0,1]\]
Client: Layer SVD->u*sigma*v
Server: mean(u*sigma*v)-> u*sigma*v
Client Revice: replace u*sigma*v
Tsinghua University
Wu, C., Wu, F., Lyu, L. et al. Communication-efficient federated learning via knowledge distillation. Nat Commun 13, 2032 (2022)
Personalized Federated Learning using Hypernetworks
2022.06.24
Method
Using a single joint hypernetwork to generate all separate models allows us to perform smart parameter sharing.
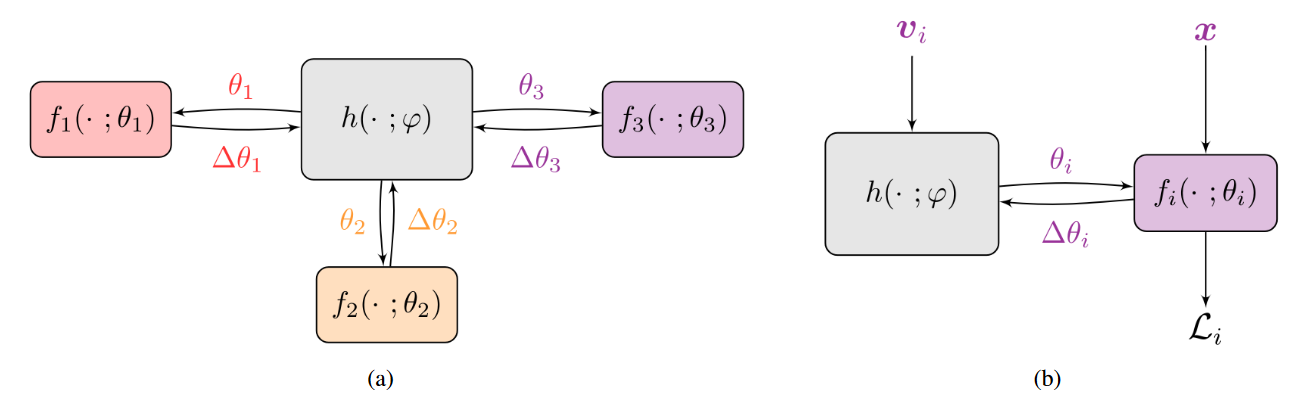

- 个性化联邦学习目标
\[\operatorname{arg\,min}\limits_{\Theta}\frac{1}{n}\sum_{i=1}^{n}\mathcal{L}_{i}(\theta_{i})=\argmin\limits_{\Theta}\frac{1}{n}\sum_{i=1}^{n}{\frac{1}{m_{i}}}\sum_{j=1}^{m_{i}}\ell_{i}(x_{j},y_{j};\theta_{i})\]
- 加入 HyperNetwork
\[\operatorname{arg\,min}\limits_{\varphi,v_{1},\ldots,v_{n}}\frac{1}{n}\sum_{i=1}^{n}\mathcal{L}_{i}(h(\mathbb{v}_{i},\phi_{i}))\]
- Personal Classifier
\[\operatorname{arg\,min}_{\varphi,v_{1},\ldots,v_{n},\omega_{1},\ldots,\omega_{n}}\frac{1}{n}\sum_{i=1}^{n}\mathcal{L}_{i}(\theta_{i},\omega_{i})\]
Results
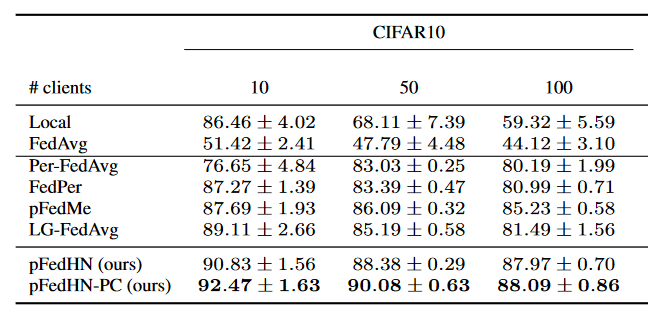
Shamsian A, Navon A, Fetaya E, et al. Personalized federated learning using hypernetworks[C]//International Conference on Machine Learning. PMLR, 2021: 9489-9502.
The Power of Scale for Parameter-Efficient Prompt Tuning
2023.04.04
Motivation
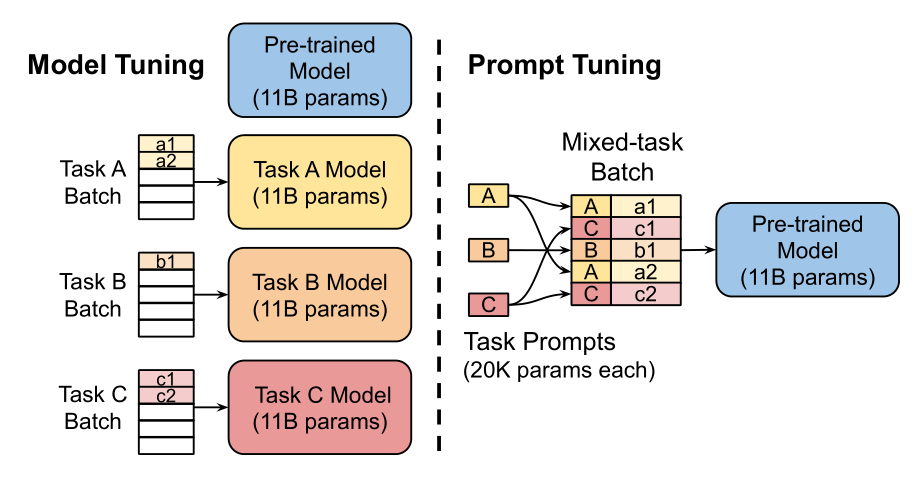
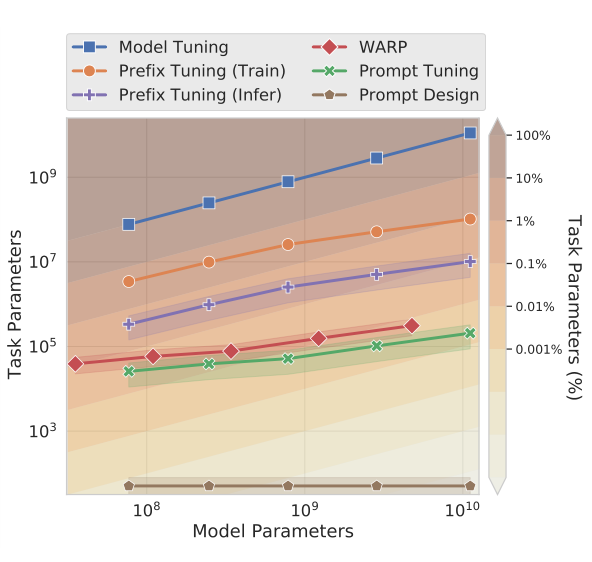
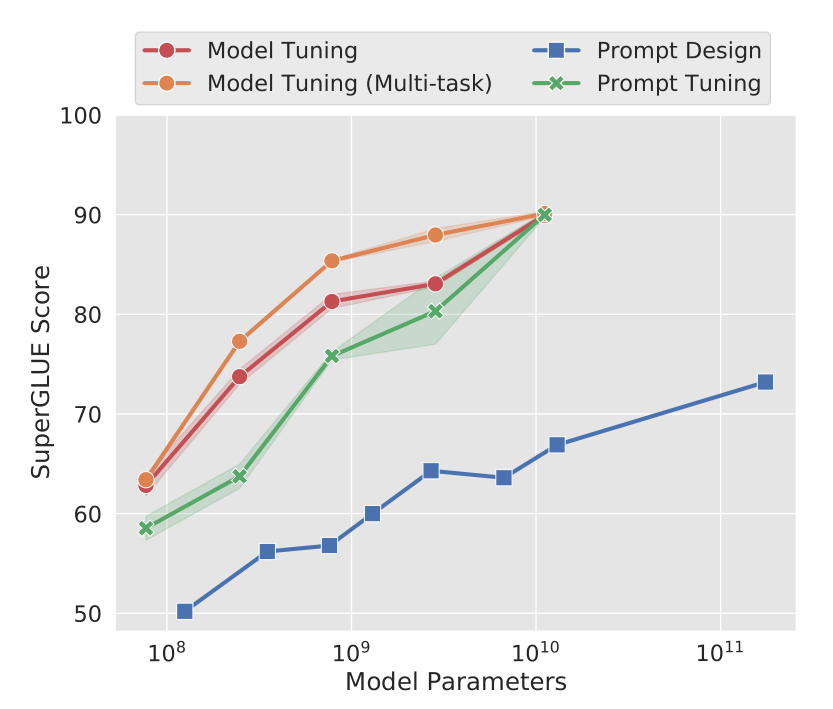
Method
模型输入层额外加入一层Embedding,其他部分冻结
额外的数据输入处理
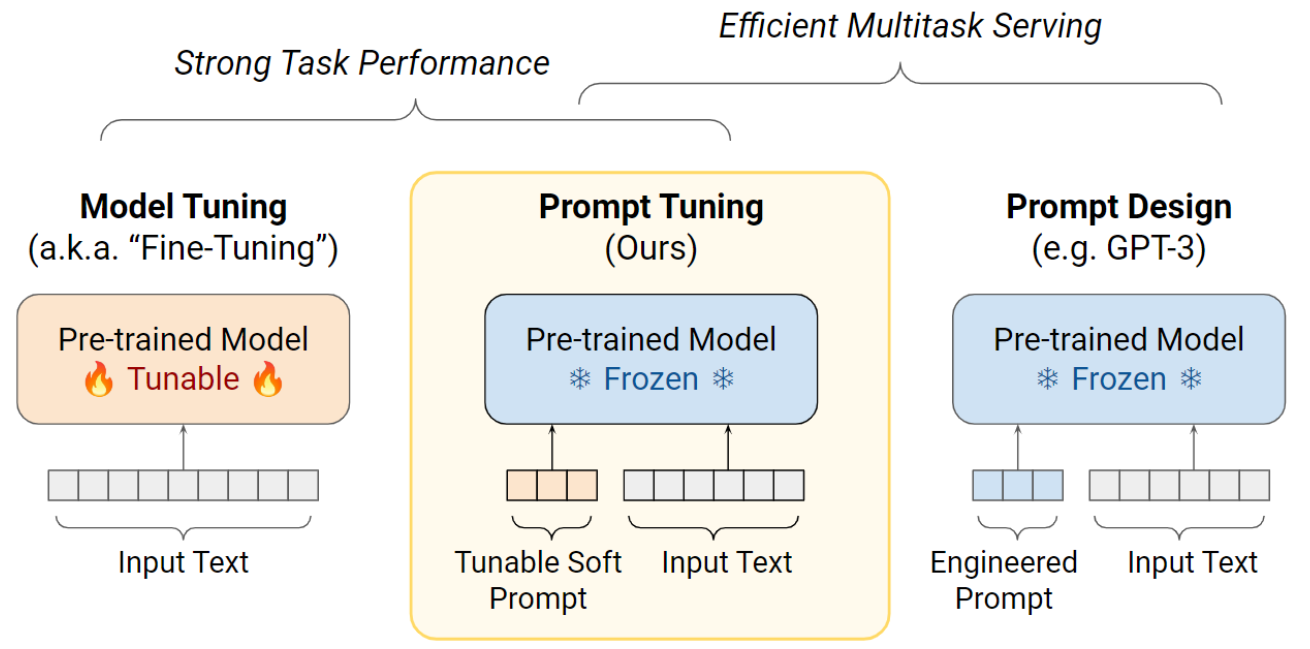
Result
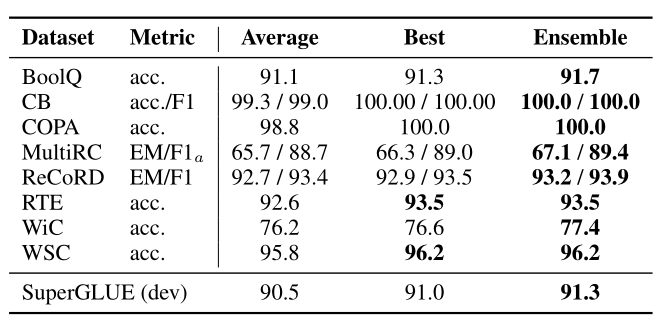
Lester B , et al. The Power of Scale for Parameter-Efficient Prompt Tuning. In EMNLP. 2021:3045–3059