auto m = a.size(0); auto n = b.size(1); auto p = a.size(1);
torch::Tensor result = torch::zeros({m, n}, torch::dtype(torch::kFloat32)); for (int i = 0; i < m; i++) { for (int j = 0; j < n; j++) { float sum = 0.0; for (int k = 0; k < p; k++) { sum += a[i][k].item<float>() * b[k][j].item<float>(); } result[i][j] = sum; } } return result; }
auto m = a.size(0); auto n = b.size(1); auto p = a.size(1);
torch::Tensor result = torch::zeros({m, n}, torch::dtype(torch::kFloat32)); for (int i = 0; i < m; i++) { for (int j = 0; j < n; j++) { float sum = 0.0; for (int k = 0; k < p; k++) { sum += a[i][k].item<float>() * b[k][j].item<float>(); } result[i][j] = sum; } } return result; }
// 参数:queries(Q),keys(K),values(V) std::vector<torch::Tensor> attention_forward( torch::Tensor &q, torch::Tensor &k, torch::Tensor &v){ if (!(q.device().type() == k.device().type() && q.device().type() == v.device().type())) { throwstd::runtime_error("Input tensors q, k, and v must be on the same device"); }
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) { m.def("forward", &attention_forward, "Attention forward (CUDA)"); }
Cu 部分
在同级目录下,创建 attention_kernel.cu文件。首先实现 attention_cuda_forward函数的主要逻辑。其中,主要对矩阵乘法进行了优化,使用了 CUDA 的并行计算。然后,使用 AT_DISPATCH_FLOATING_TYPES宏来实现对不同类型的支持,这样就可以支持 float和 double类型了。
对于 matrix_multiply函数,与一般写法不同的是,需要提前创建好输出的 Tensor,然后再传入到 CUDA 的函数中。并且需要创建好 blocks和 threads,然后再调用 CUDA 的函数。这里指定了每个 CUDA 是有 16 x 16 线程的块,而这些块是可以并行计算的,所以能够加速计算。可参考 An Even Easier Introduction to CUDA
而在传递参数的时候,需要使用 packed_accessor。这里的 packed_accessor的第一个参数是 Tensor的类型,第二个参数是 Tensor的维度,第三个参数是 Tensor的类型,第四个参数是 Tensor的维度。这里的 packed_accessor的第三个参数和第四个参数,是为了支持 CUDA 的。
if (row < input1.size(0) && col < input2.size(1)) { scalar_t value = 0.0; for (int k = 0; k < input1.size(1); ++k) { value += input1[row][k] * input2[k][col]; } output[row][col] = value; } }
torch::Tensor matrix_multiply(torch::Tensor input1, torch::Tensor input2){ int rows1 = input1.size(0); int cols1 = input1.size(1); int cols2 = input2.size(1);
auto options = torch::TensorOptions().device(input1.device()); torch::Tensor output = torch::zeros({rows1, cols2}, options);
block_size = 2# 方便起见,这里设置为 N,M,K 的公约数。同时也拆成了 2x2 的 block block_M, block_N, block_K = M // block_size, N // block_size, K // block_size
defmatmul(sub_A1, sub_A2): output = torch.zeros(size=(sub_A1.shape[0], sub_A2.shape[1])) for i inrange(sub_A1.shape[0]): for j inrange(sub_A2.shape[1]): for k inrange(sub_A2.shape[0]): output[i][j] += sub_A1[i][k] * sub_A2[k][j] return output
block_size_M, block_size_N, block_size_K = 2, 3, 4 block_M, block_N, block_K = M // block_size_M, N // block_size_N, K // block_size_K
defblock_matmul(sub_A1, sub_A2): output = torch.zeros(size=(sub_A1.shape[0], sub_A2.shape[1])) for i inrange(sub_A1.shape[0]): for j inrange(sub_A2.shape[1]): for k inrange(sub_A2.shape[0]): output[i][j] += sub_A1[i][k] * sub_A2[k][j] return output
defmatmul(A1, A2): output = torch.zeros(size=(A1.shape[0], A2.shape[1])) for i inrange(0, A1.shape[0], block_M): start_i, end_i = i, i + block_M for j inrange(0, A2.shape[1], block_N): start_j, end_j = j, j + block_N for k inrange(0, A2.shape[0], block_K): start_k, end_k = k, k + block_K # 计算每个 block 的矩阵乘法 sub_A1 = A1[start_i:end_i, start_k:end_k] sub_A2 = A2[start_k:end_k, start_j:end_j] # 把每个 block 的结果放到对应的位置 output[start_i:end_i, start_j:end_j] += block_matmul(sub_A1, sub_A2) return output print(matmul(A1, A2)) print(A1 @ A2) assert torch.allclose(matmul(A1, A2), A1 @ A2)
From https://penny-xu.github.io/blog/tiled-matrix-multiplication
With or without tiling, the same number of accesses into global memory occur. The difference is that, without tiling, each thread must sequentially (one after the other) access global memory 8 times.
With tiling, we can parallelize the access to global memory so that each thread only sequentially accesses global memory 4 times.
To summarize, the point is not to reduce the number of multiplications or even the total number of global memory accesses, but rather to reduce the number of sequential global memory accesses per thread. In other words, we better share the heavy load of memory access across threads.
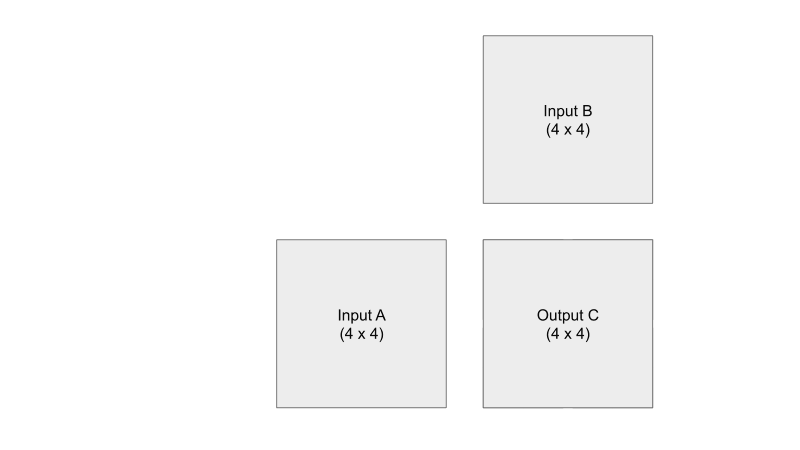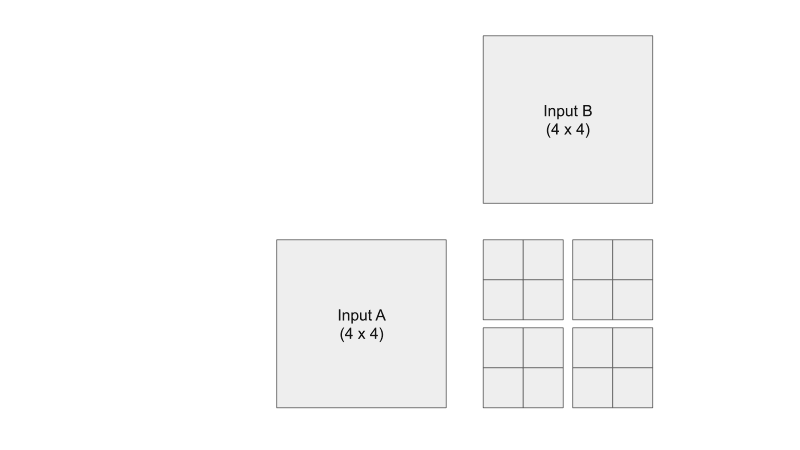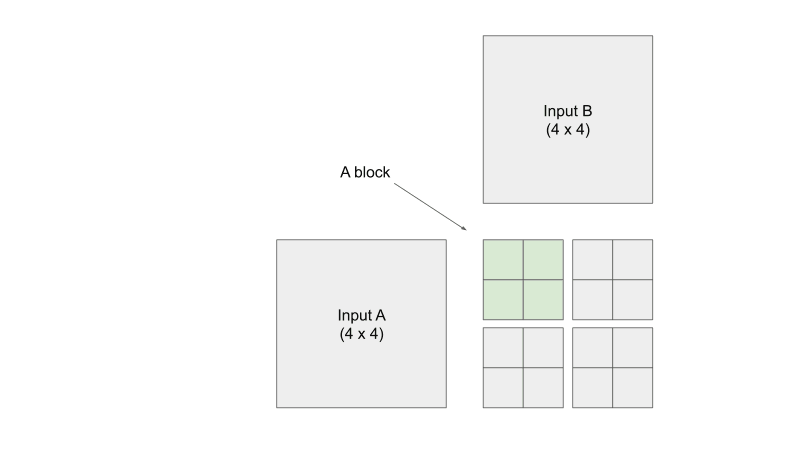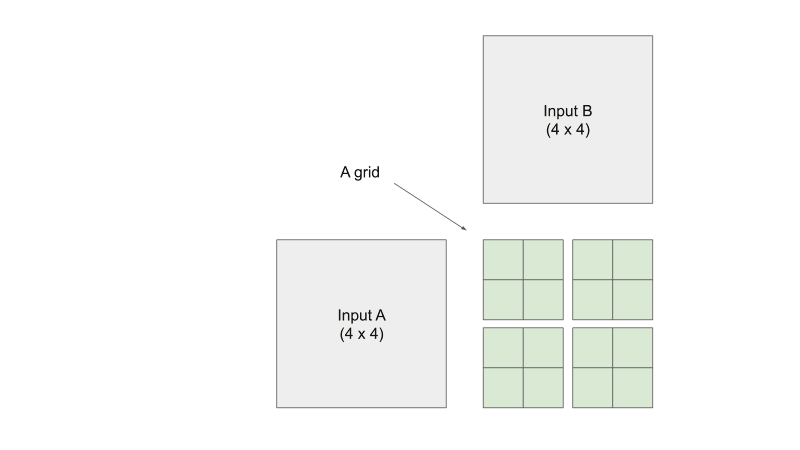 From https://penny-xu.github.io/blog/tiled-matrix-multiplication
From https://penny-xu.github.io/blog/tiled-matrix-multiplication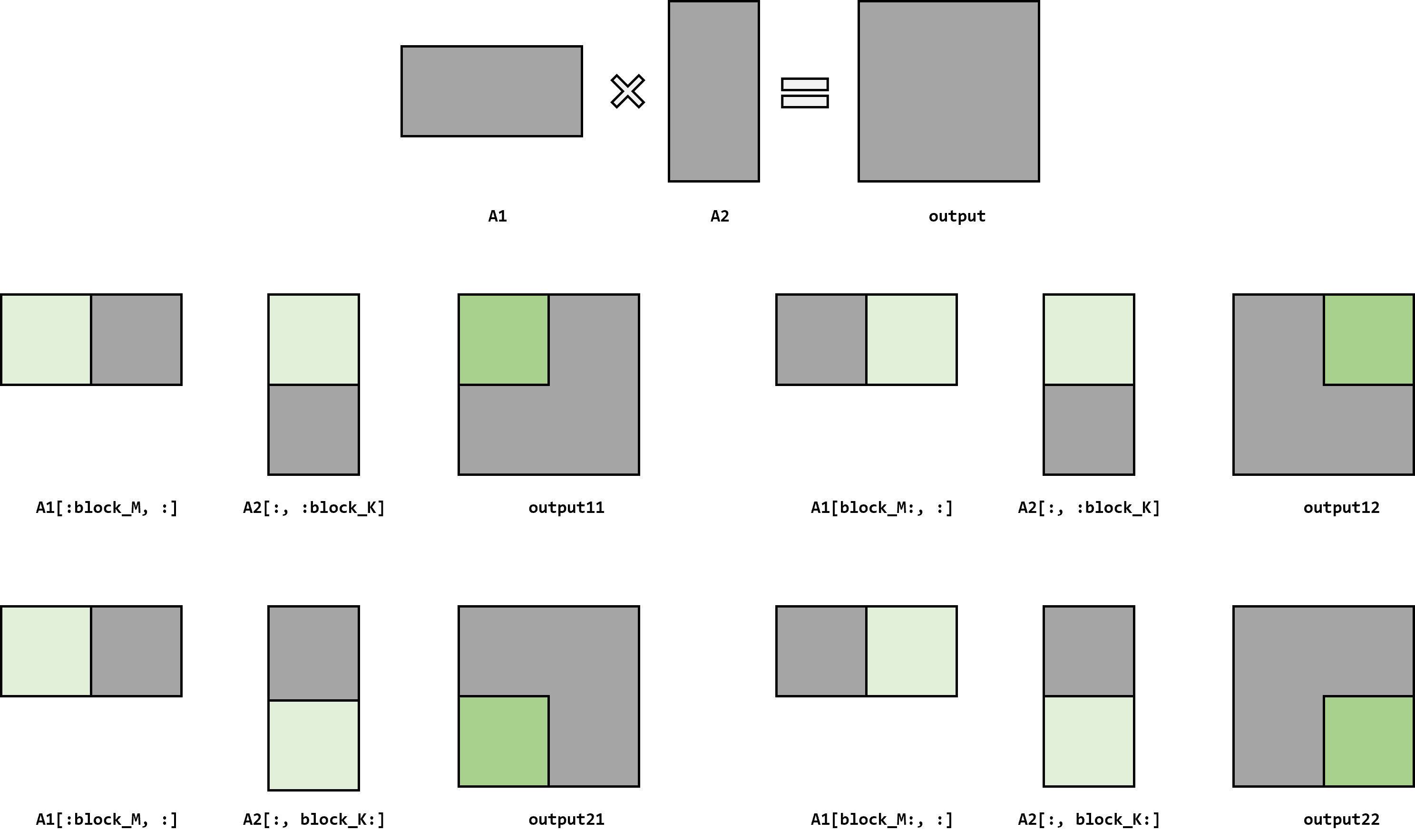
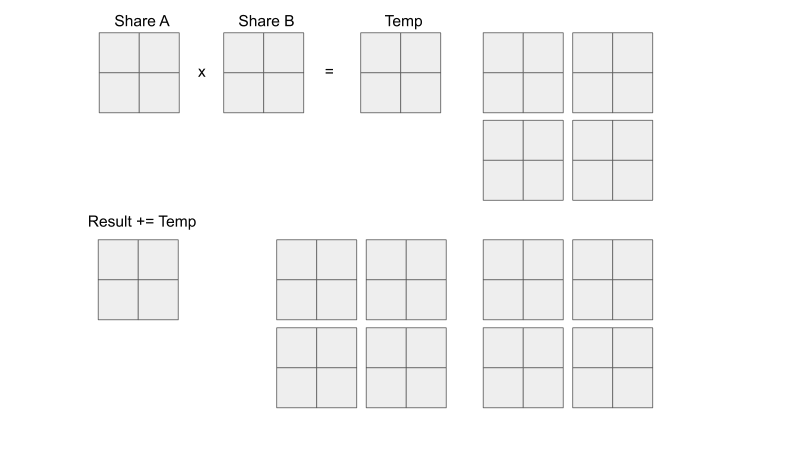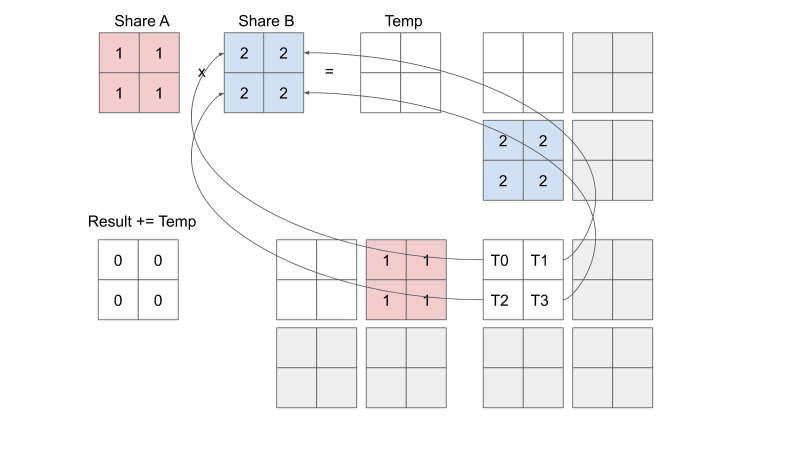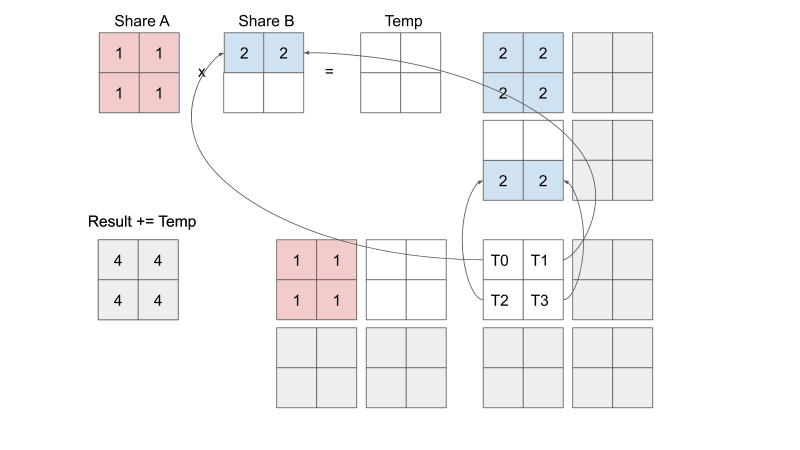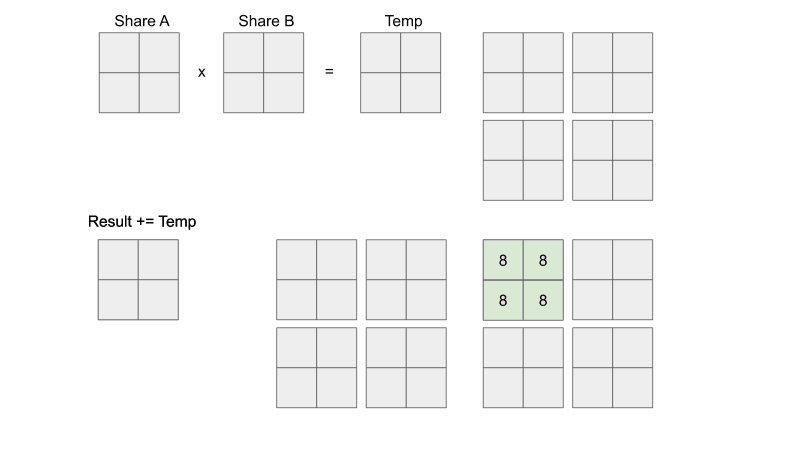 From https://penny-xu.github.io/blog/tiled-matrix-multiplication
From https://penny-xu.github.io/blog/tiled-matrix-multiplication