对于两种场景下介绍 LLM 的 推理加速方法
长输入,短输出
长输出但输出 token 有限
大语言模型在进行推理时是非常耗时的,因为需要对每个 token 进行计算。对于推理加速这个话题,在工程上可以从很多方面考虑:
- 模型进行量化/剪枝,降低模型浮点计算成本
- Continuous Batch,批量计算 Next Token
- KV Cache:LLM 推理的是 Token by Token 生成,每次生成的时候会计算所有输入 Token 的 Attention,故可以缓存已计算的 Attention,减少计算量
- 对显存进行管理,如 PageAttention
- KV Cache 量化
- ...
而其他在工程上的优化,往往是针对特定场景的,下面介绍两种场景下的优化方法。
Prefix Cache:长输入,短输出
注:优化显存并不会减少计算量,只是减少了显存占用,从而提升了吞吐。
KV cache 显存计算公式
\(4\times b\times l\times num\_heads\times embed\_size\_per\_head \times (s+n)\)
参数说明
- b: 句子条数
- l:层数
- num_heads:隐层大小 (num_key_value_heads)
- embed_size_per_head:每个头的大小 (hidden_size / num_attention_heads)
- s:输入长度
- n:输出长度
- 4:k cache+v cache,均为 float16,所以是(1+1)*2
如果只有1条句子,输入+输出 token 长度由 512 -> 1024,则会增加 \(4\times 512 \times l\times h\):
Llama3-8B:$4 / 1024 / 1024 = 64 $ M
Llama3-70B:\(4\times 512\times 1024\times 80 / 1024 / 1024 = 160\) M
简单来说,每增加一个 token
8B 就会增加 0.125 M 的显存
70B 就会增加 0.3125 M 的显存
这个显存占有直到整个句子生成完成之后才会释放,所以对于长句子,KV Cache 的显存占用是非常大的。
显存决定了整体的吞吐量。对于 70B,假设有 1k 个请求,每个请求的总 token 为 1k,那么显存占用为 0.3125M * 1000 * 1000 = 0.3G。
方法
在 LLM 推理时,往往是用对话的方式进行推理,而每次对话的开头可能是相同(System),这一部分的 Attention 是不变的,所以可以缓存这部分 Attention。
加速的原因:
- prefix 的 kv cache 不需要计算
- prefix 的 kv cache 复用节约了显存,提升吞吐(主要收益)
所以适用场景的一个明显特点就是必须要有长的 system prefix,而且这个 prefix 是不变的。另外,如果模型输出过长的话,这个优化的收益就会变小。因为它并不会加速在生成过程中的计算,只是减少了显存占用。
收益
https://github.com/vllm-project/vllm/issues/227
For each request, the prefix length is 200, the input length is 30, and the output length is 50.
| Load (QPS) | Method | Requests/s | Average Latency per Req | First Token Time |
|---|---|---|---|---|
| 10 QPS | Prefix Cache | 9.83 requests/s | 1.97 s | 0.29 s |
| 10 QPS | Base | 9.80 requests/s | 2.87 s | 0.45 s |
| 15 QPS | Prefix Cache | 14.30 requests/s | 2.98 s | 0.39 s |
| 15 QPS | Base | 13.24 requests/s | 8.65 s | 1.02 s |
| 25 QPS | Prefix Cache | 19.81 requests/s | 6.46 s | 0.84 s |
| 25 QPS | Base | 14.08 requests/s | 13.67 s | 4.74 s |
并行解码:长输出但输出 token 有限
LLM 的推理是 Token by Token 生成的,如果有一种方式可以每次生成多个 token,那么就可以提升推理速度。
方法
以下图为例,对 LLM 的模型结构进行一定的修改,使每次可以同时生成 3 个 token。
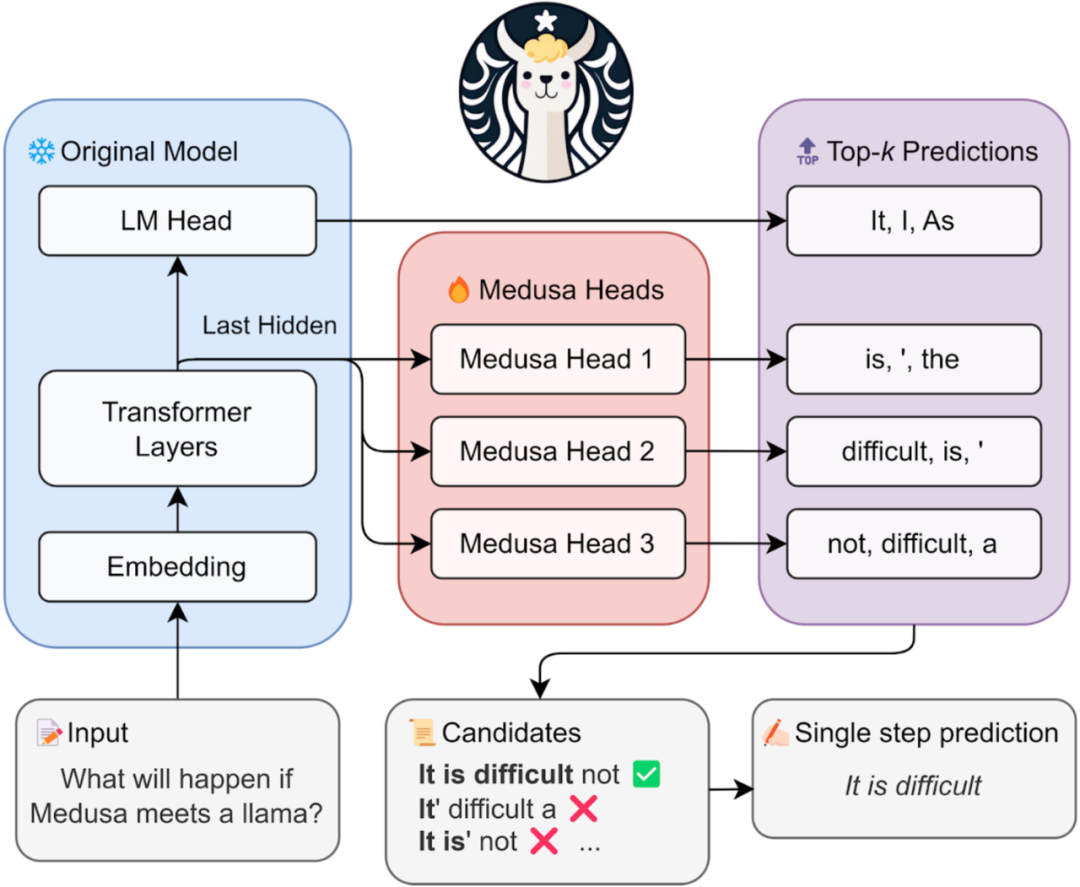
并行解码的方式不一定要对结构进行修改,这里只是一种实现方式。
具体实现方式: - 训练:修改结构后对模型的新增部分进行常规的训练,其他部分冻结,减少训练成本 - 推理:模型生成的时候会把连续 3 个 token 的 top-K 的可能均生成,交由原模型进行打分,然后选择最优的一个。
问题
并行生成的 Token 的可靠性是取决于具体场景的。如果生成的 Token 可能性只有 20 个,那么并行生成的 Token 的可靠性就会相对较高,这种对于模型而言是更容易学习的。但如果生成的 Token 可能有 10000 个,那么并行生成的 Token 的可靠性就会相对较低。
换而言之,Token 可能性越少越容易猜中,越多越难猜中。所以,这种方法适用于输出 token 可能性有限的场景。
并且,如果输出 token 数量较短,那么相较于 token by token 的生成,这种方法的优势就会变小。