从标准的自回归解码开始,介绍 EAGLE 系列(EAGLE、EAGLE-2和EAGLE-3)的演进历程。
LLM 的标准生成过程
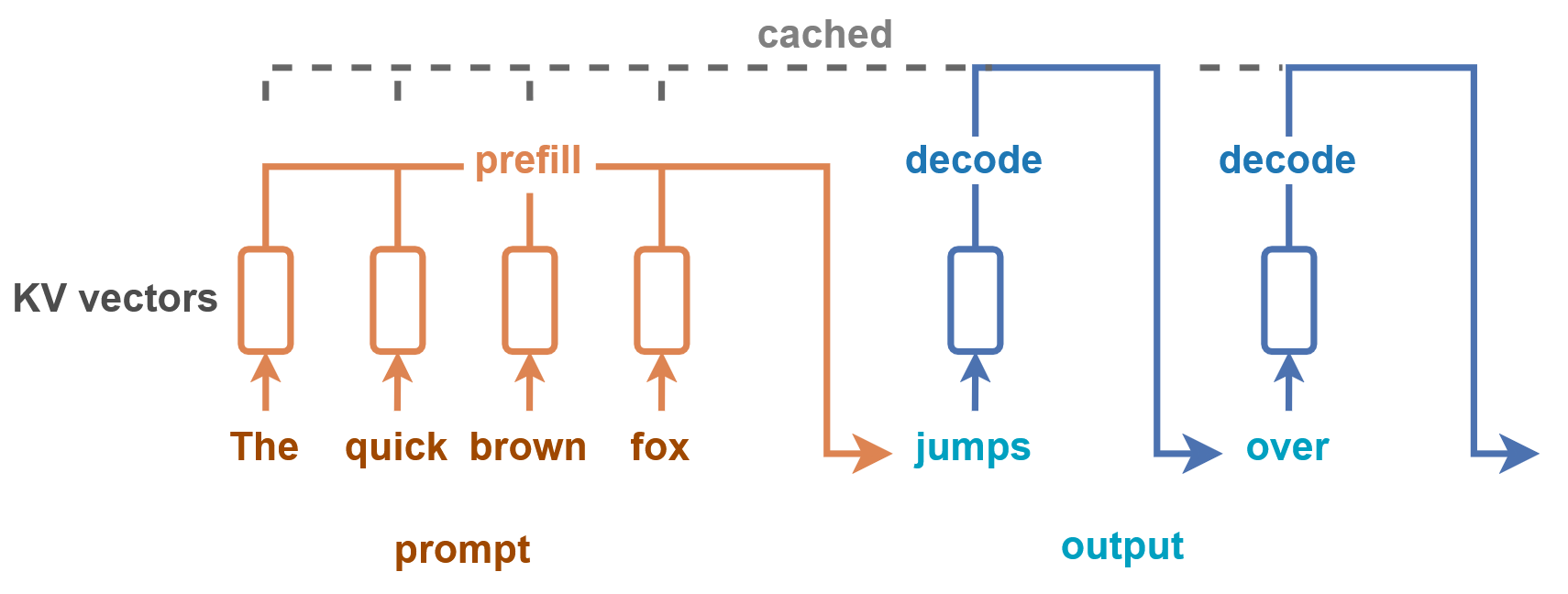
瓶颈:token by token 生成,生成单个 token 的时间很快,但由于要生成多个 token,导致整个句子的生成时间变久。
如果能减少生成 token 的次数,那么就能加速句子的生成。
一种代表性的优化方法是投机解码。
相关引用:https://huggingface.co/blog/tngtech/llm-performance-prefill-decode-concurrent-requests
投机解码
EAGLE-1:特征层面的投机解码
https://arxiv.org/pdf/2401.15077
EAGLE-1 的动机
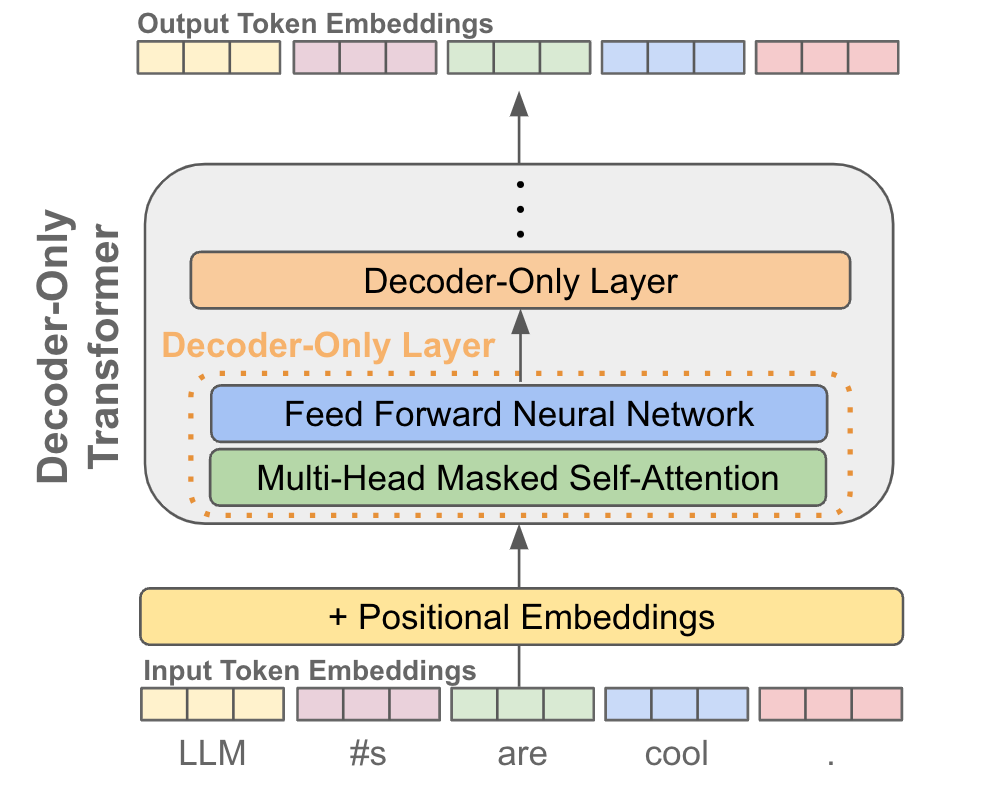
特征(feature) 是指下图中的 Output Token Embeddings,即过完 Decoder-Only Transformer 后的输出
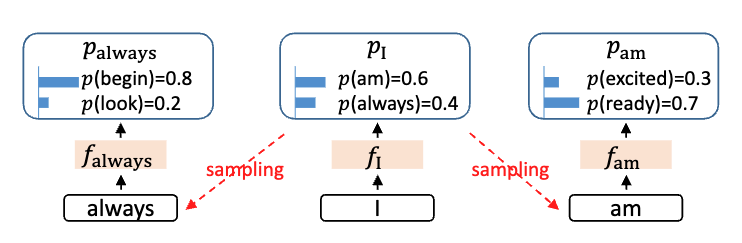
动机一:采样过程中的不确定性
下图中的 $f_I$ 就是上面说的特征,这个特征会再过 LM Head,得到 logits。这个 logtis 再采样生成 token。
I 后面为是 always 和 am 的概率差不多,如果用 token 级别的采样,可能会漏掉被接受的 token。
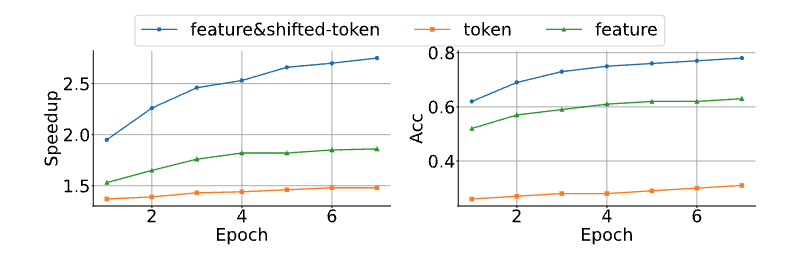
动机二: feature 级别的自回归是比 token 级别的自回归更容易预测
作者是先进行了该项假设,再实现了 EAGLE-1,最后再画了下面这张图。
- feature&shifted-token:使用特征序列和前一个 token 序列(embedding)进行作为输入
prefill 阶段
额外保存变量 + 输出第一个 token
| 示例图 | 说明 |
|---|---|
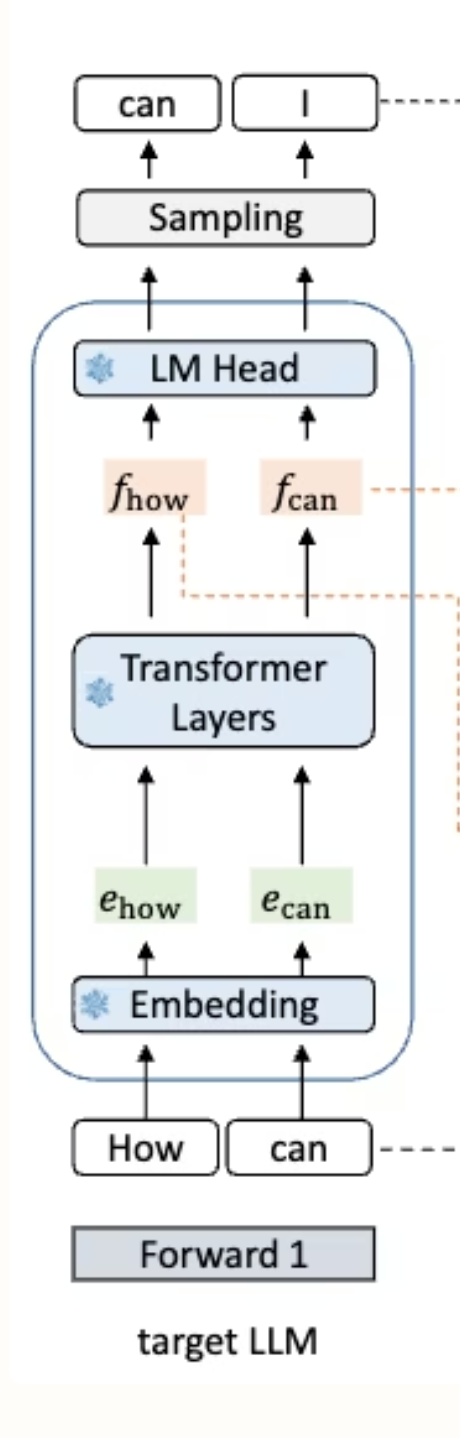 |
从下往上看输入 「how」和「can」 两个 token $e{how}$ 表示「how」这个 token 过完 Embedding 之后的 tensor $f{how}$ 表示 「how」这个 token 进入 LM Head 之前的 tensor 预测的 token 为「I」 |
decode 阶段输出 token
回顾
- 输入的是「how」和「can」,prefill 阶段输出的是「I」
- 现在的目标是预测「I」的下一个 token
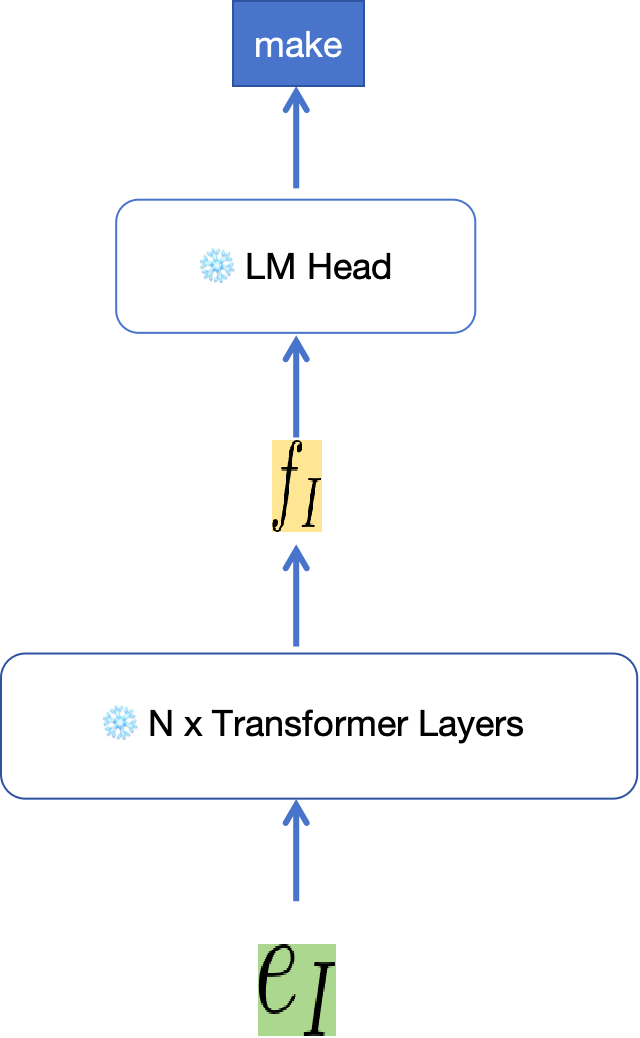
EAGLE 的想法:用训练后的 One Auto-regression Head 代替 N x transformer layers。
| 标准解码 | EAGLE | 说明 |
|---|---|---|
 |
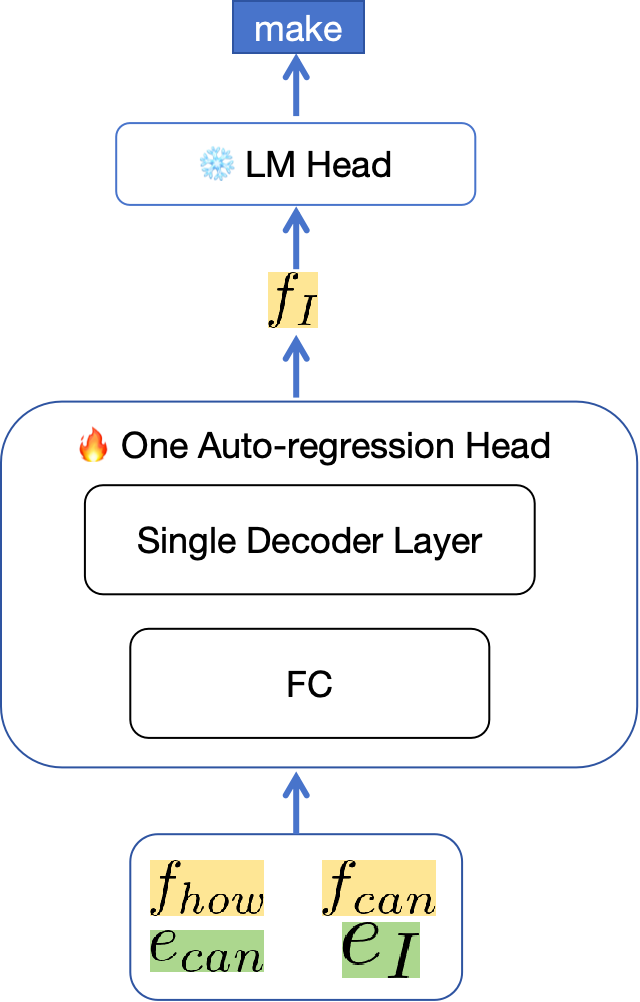 |
Step 1:在 prefill 阶段得到前两个 token 的 feature(黄色)以及最新两个 token 的 embedding(绿色)。把它们组合 Step 2: 输入到训练后的 One Auto-regression Head 中 Step 3: 输出得到新的特征 $f_I$ Step 4: 经过 LM Head,采样得到下一个 token,「make」 |
FC 的作用是降维,将 feature 和 embedding 两个 tensor 降维成一个。
- feature:[2, hidden_size]
- embedding:[2, hidden_size]
- 组合 feature 和 embedding:[2, 2*hidden_size]
- FC 的权重:[2*hidden_size, hidden_size]
- FC 的输出:[2, hidden_size]
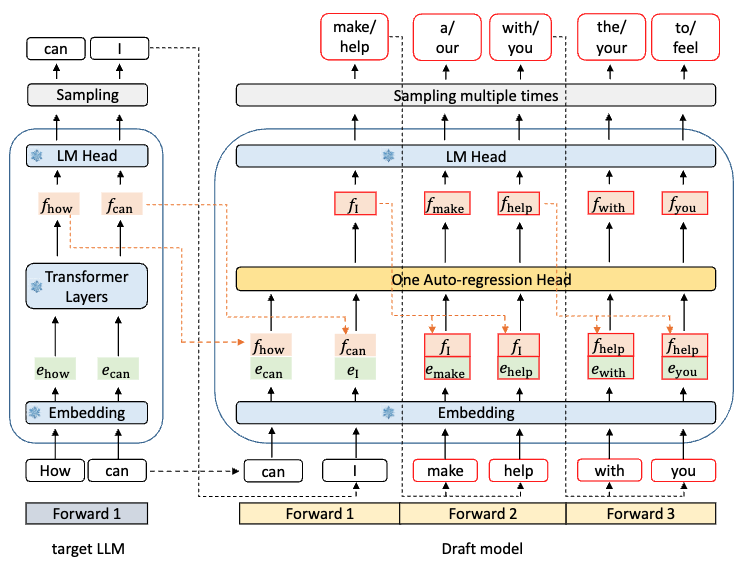
Draft Model——One Auto-regression Head
Pipeline
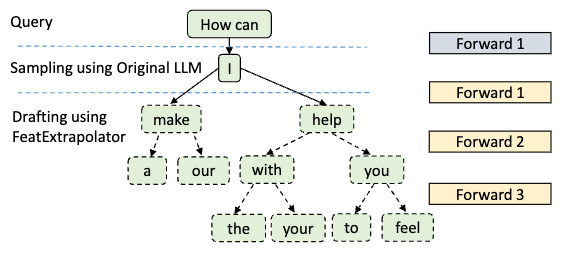
- 在 Forward 1 中,生成的 f_I 过完 LM Head 后可以采样多个 token
- 在 Forward 2 中,用上一轮生成的 token,make 和 help 分别进行下一次循环生成
- 此时,只需要上一次采样生成的 token 信息(Draft Model 信息),而无需 Target Model 的信息
- 在 Forward 3 中,同 Forward 2,这里只展示用 with 和 you 进行推理,实际上 a 和 our 也会继续生成
- Draft Model (One Auto-regression Head)参数量小,生成 token 的速度很快。重复这个步骤
Draft Tree 每次生成多组可能
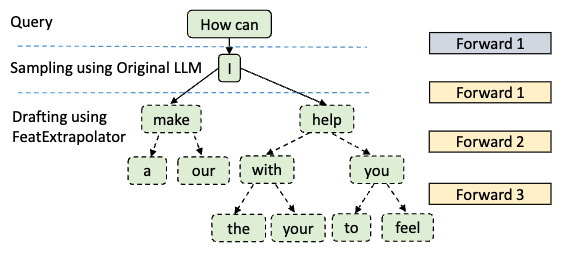
在一次 Draft Model 推理时,会生成 (Forward 次数)^(采样 token 个数) 的方案
- make a
- make our
- help with the
- help with your
- help you to
- help you feel
工程设计:Attention Mask
| 标准 | Draft Tree |
|---|---|
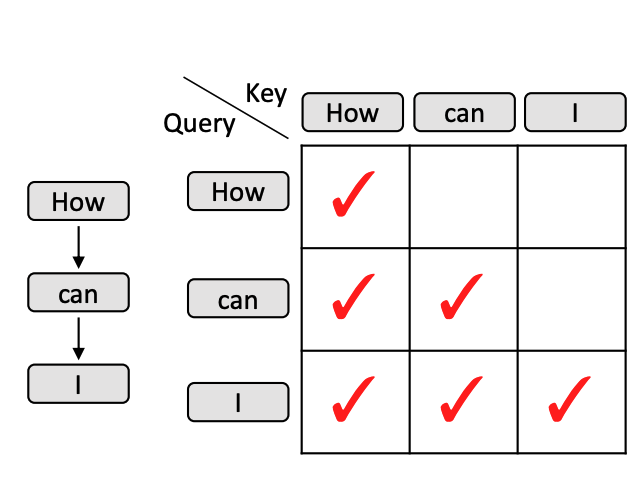 |
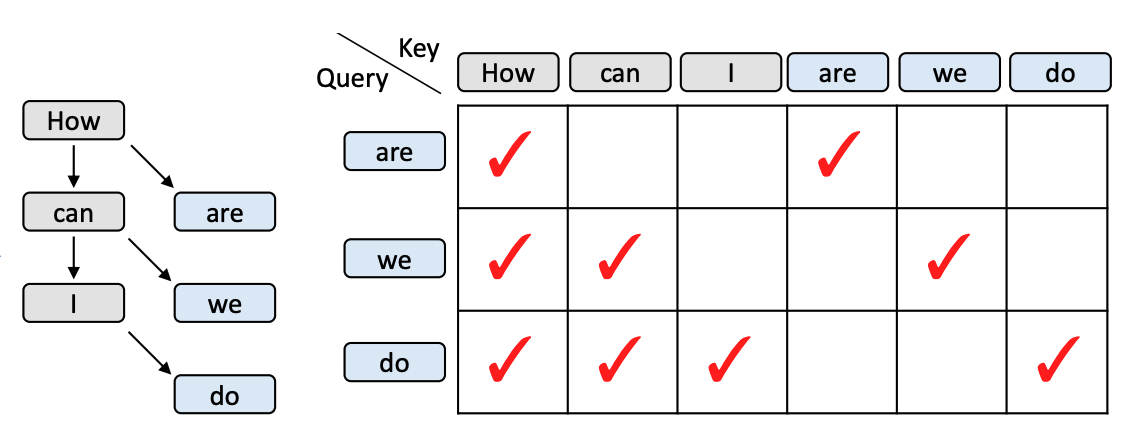 |
- 以「we」为例,这个 token 只能看到「How」和「can」,不能看到「are」
对比经典投机采样
回顾投机采样的收益
- Draft Model 生成的速度 → 模型的参数量
- Draft Model 的平均接受长度
以 72B(Target Model)和 7B(Draft Model)为例
| 生成速度 | 平均接受长度 | |
|---|---|---|
| 经典方法 | 7B 的生成速度 | 只有一组方案,取决于 7B 训练效果 |
| EAGLE | 0.99B = 一层 Decoder + FC | 生成多组方案,并且是基于 Target Model 训练的 |
| 小结 | 参数量上远小于 7B | 可能性更多,接受率更大经过训练,预期效果会比经典方法好 |
注:Decoder Layer 的 hidden size 大小于 Target Model 相同
这篇论文实验结果展现的方式不是特别好,没有对比经典投机解码的速度。
在后文中再对比「平均接受长度」,以及其他投机解码方法。
官方结果
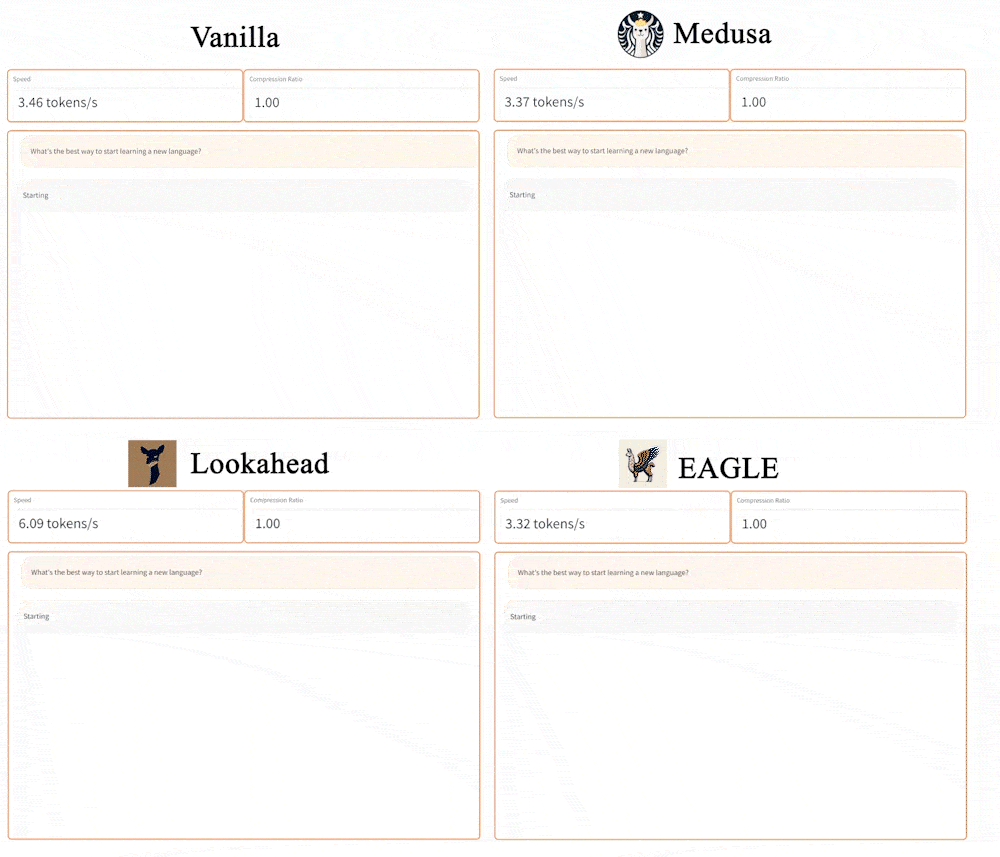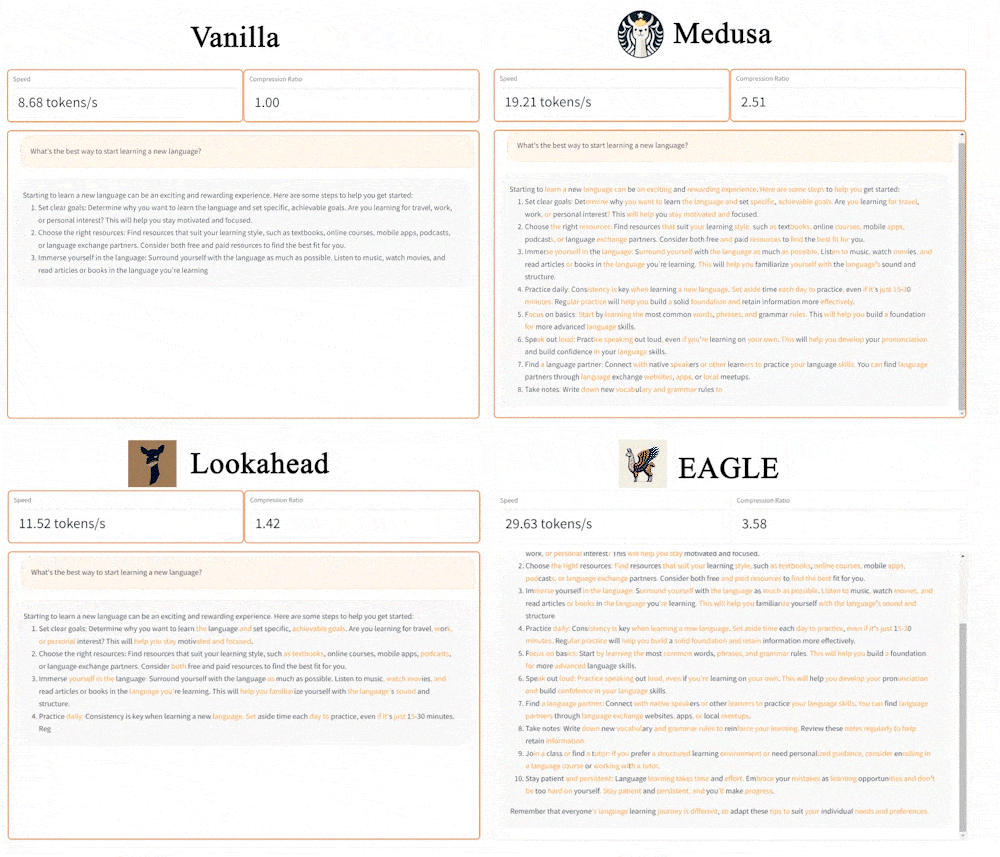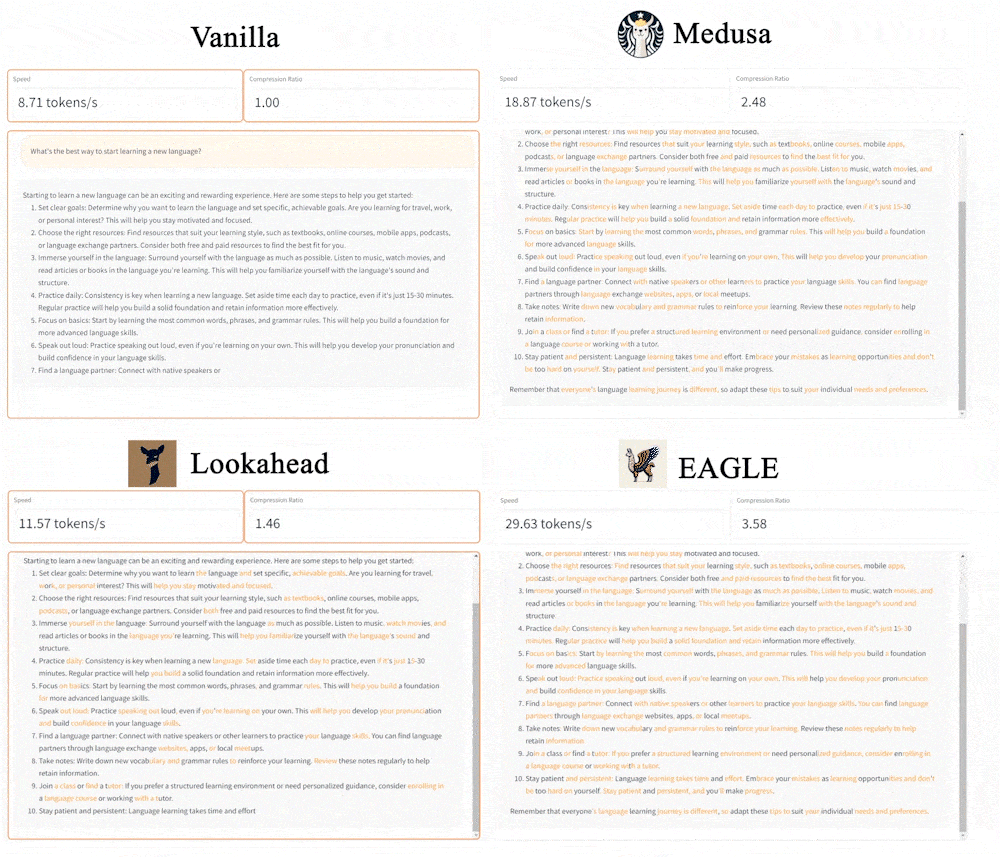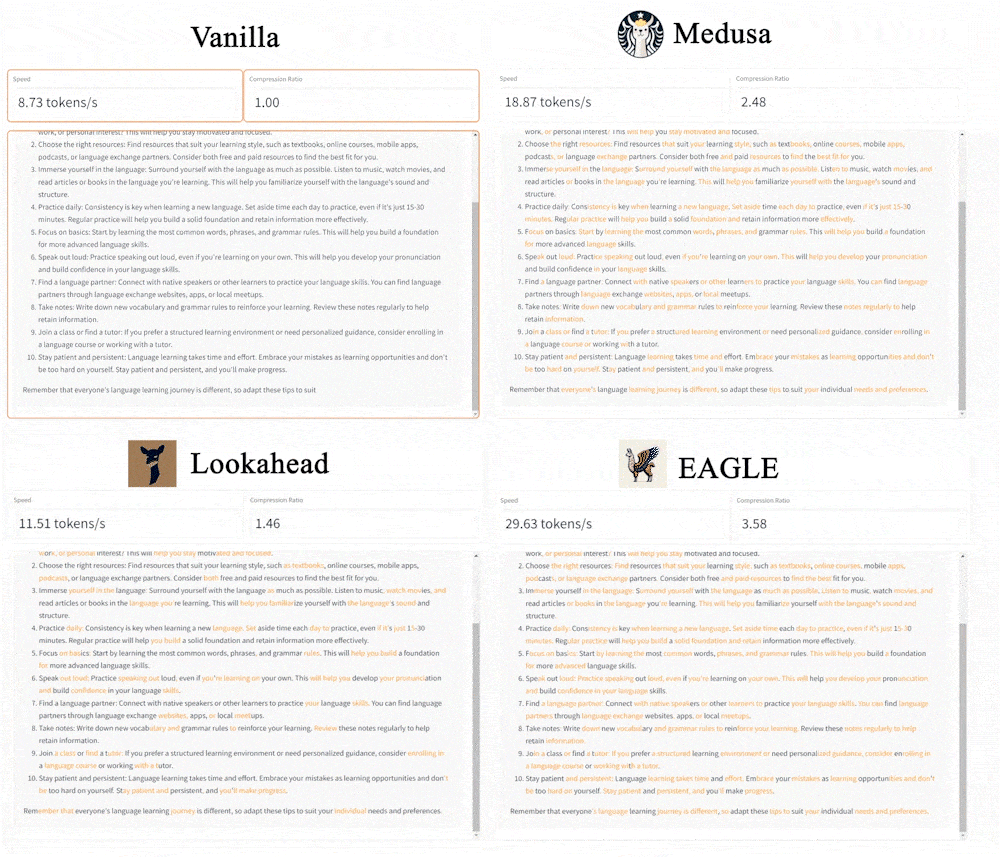
- 3x faster than vanilla decoding (Target Model 13B).
- 投机解码的变种方法
- 2x faster than Lookahead (13B).
- 1.6x faster than Medusa (13B).
EAGLE-2:工程优化——动态草稿树
https://arxiv.org/pdf/2406.16858
个人评价:在 Draft Model 生成时用 Beam Search,始终选分数最高的 N 组方案。
EAGLE-2 的动机
Beam Search
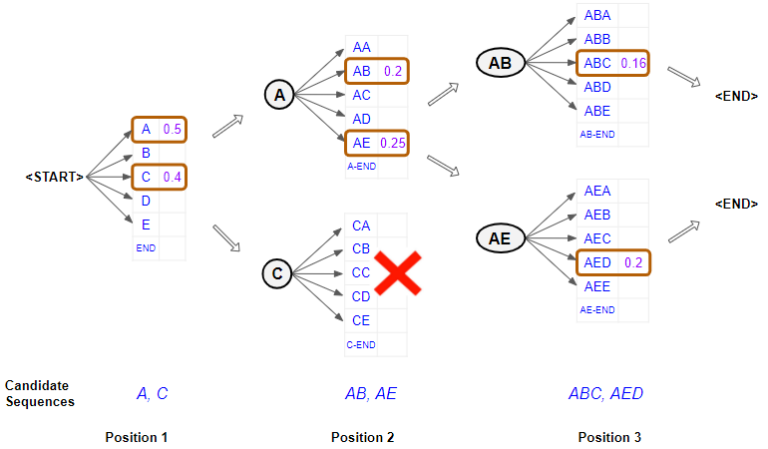
- Pos 1:选择 K 个概率最高的词元(通常是词语或字符)。这里的 K 是设定的 束宽 (Beam Width)。
- Pos 2:从两组概率中,结合第一个位置的概率,选出 K 个最佳的“两词元”序列。并且是从所有可能的组合中,根据它们的累积概率进行排序。
- Pos 3:重复上面过程
在 EAGLE-1 中提到,Draft Model 每次会生成若干组方案(称为 Draft Tree)。
而“若干”是被限定的,如下图所示,每次只采样 2 个 token。
期望更精准地确定 Draft Model 生成的哪些 token 是可靠的(剪枝),降低 Target Model 验证成本。
举个例子
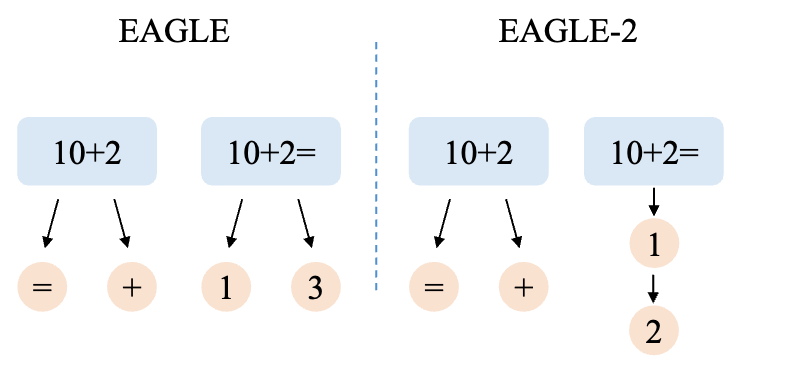
限定最大采样 token 数为 2,在生成第二个 token 时,
- 在 EAGLE-1 中,「10+2=」会采样两个 token,1 和 3
- 在 EAGLE-2 中,「10+2=」只会采样一个 token,1。进而下一个 token 生成 2。
验证/观察现象
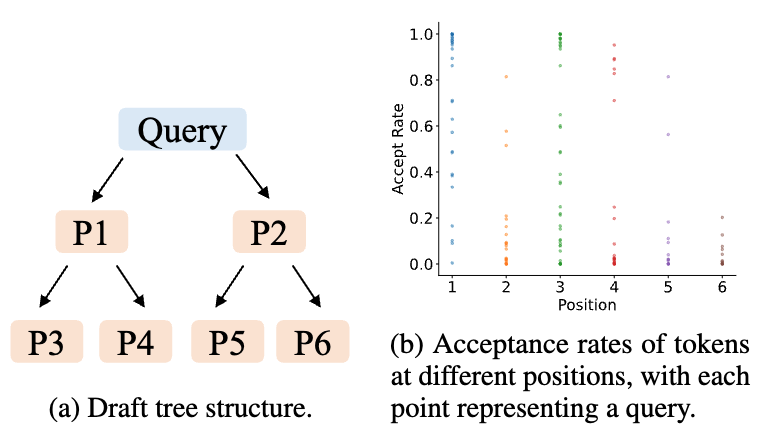
在 Alpaca 数据集上,使用 Vicuna 7B 模型作为 Target Model,测试 Draft Tree 上不同位置的 Token 接受率。
- 横坐标:不同位置,对应左图 P1-P6。
- 纵坐标:每个位置的 Token 接受率
小结:
- 位置依赖性:P1 (左上角)的接受率相对较高,P6(右下角) 的接受率相对低
- 上下文依赖:哪怕都在一个位置,接受率存在显著差异。
- 每次 Target Model 校验完,Draft Model 需要重新生成 Draft Tree
为了低成本估计 Draft Token 的接受率,探究了 Draft Model 的置信度分数(即模型输出 token 的概率)与实际接受率之间的关系
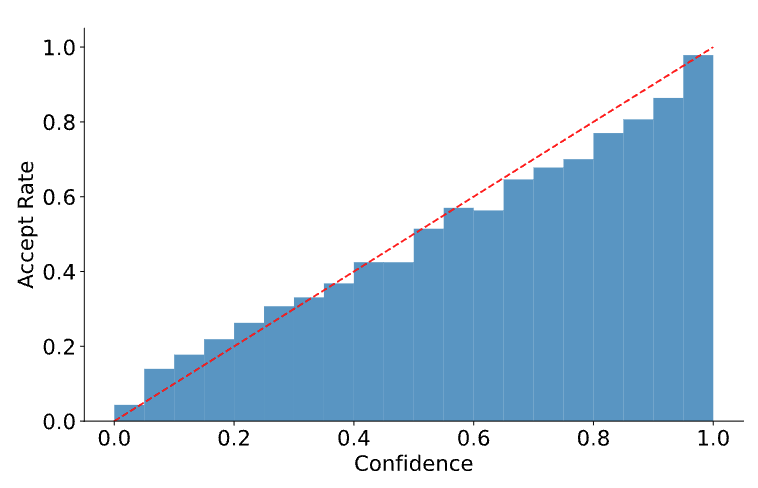
同样是在 Alpaca 数据集上进行了实验(模型大概也是同一个,Vicuna 7B)
如图所示,置信度分数和接受率是强正相关的。
- 置信度分数低于 0.05 的草稿 token 的接受率约为 0.04
- 置信度分数高于 0.95 的 token 的接受率约为 0.98
置信度具体计算
在过完 Model 后得到 hidden_states,再过 LM head,此时得到的 logits 。最后进行 softmax ,得到每个 token 的置信度。
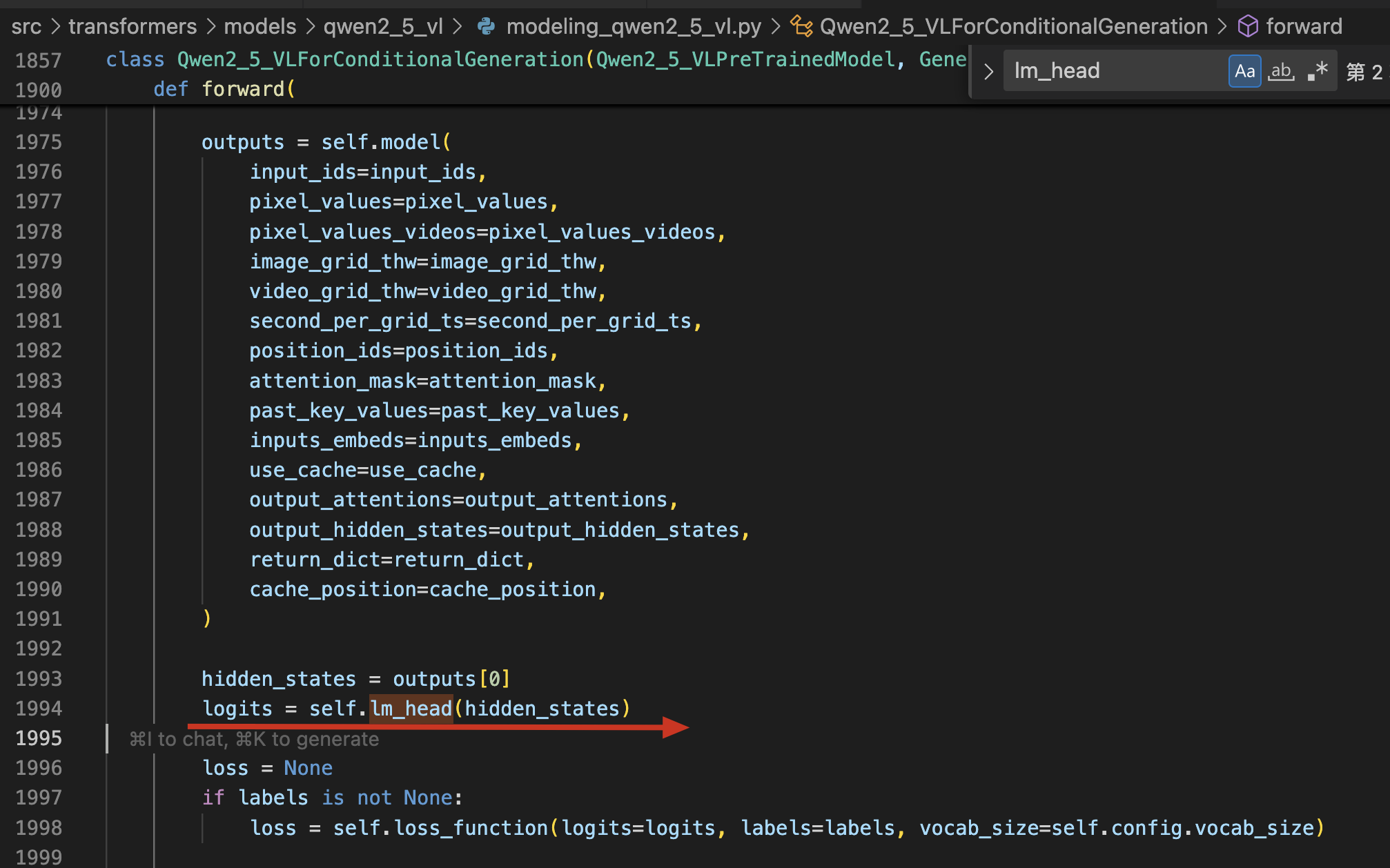
方法
定义两个整型变量 K 和 M
- K 决定每次采样几个 Token(同 EAGLE-1)
- M 决定最后生成的 Token 总数
假设 K = 2,M = 8
Step 1:每次都生成 2 个 Token,保留每次生成 Token 的概率值。直到所有步骤生成的 Token 总数 > 8
Step 2:每个 Token 的概率值 = 生成该 Token 的概率值 * 父节点的价值。比如 good = It is a good → 1×0.6×0.8×0.7 = 0.34。
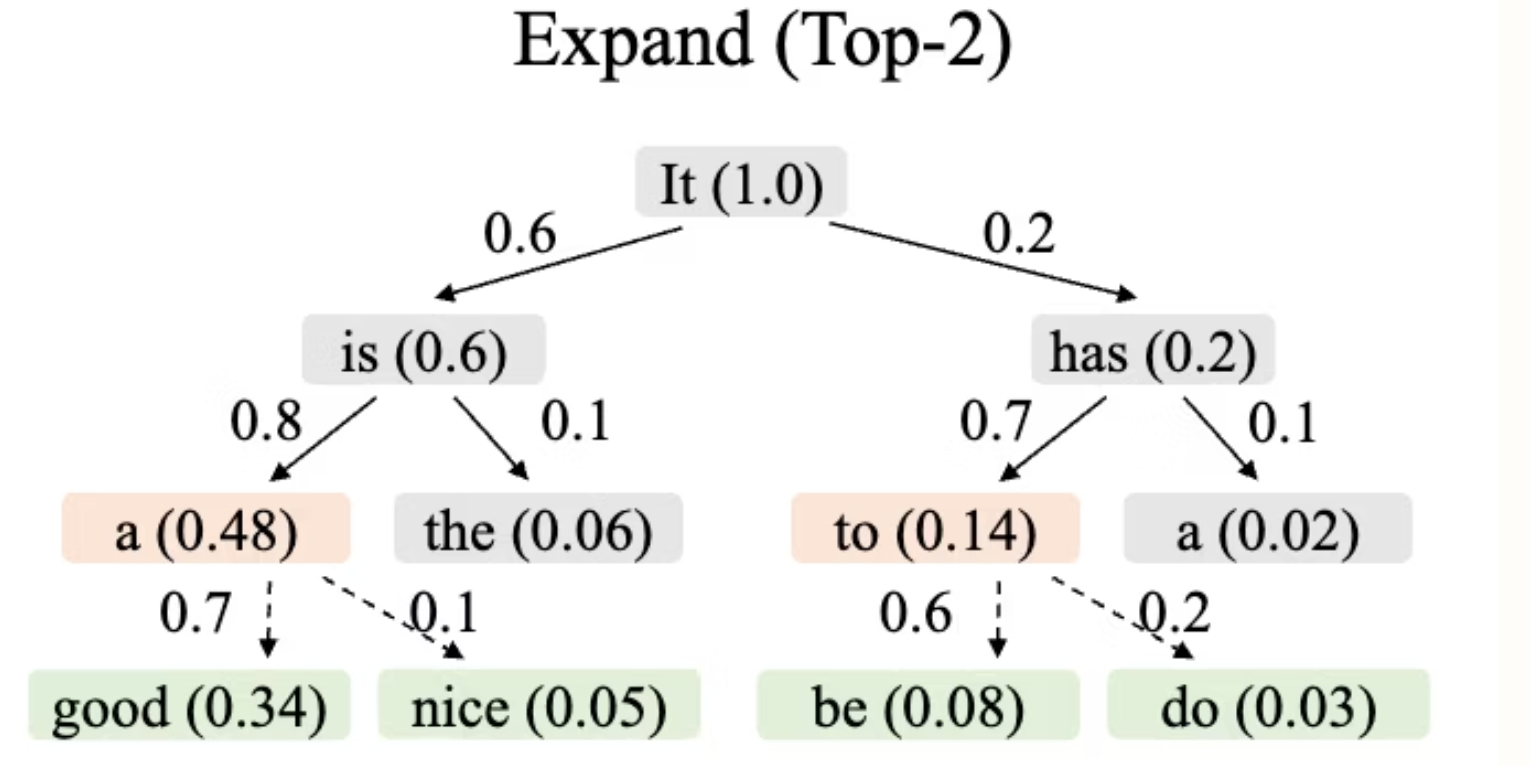
Step 3:排序所有 Token 的概率值,选出最大 M=8 个。剩下的不继续向下扩展

比 EAGLE-1 快在哪?
Draft Model 生成 token 的平均接受长度 τ
V 表示 Vicuna 模型,在不同数据集,不同模型尺寸,相较于标准投机解码方法(SpS)的加速比,以及平均接受长度。
最后两列是均值。
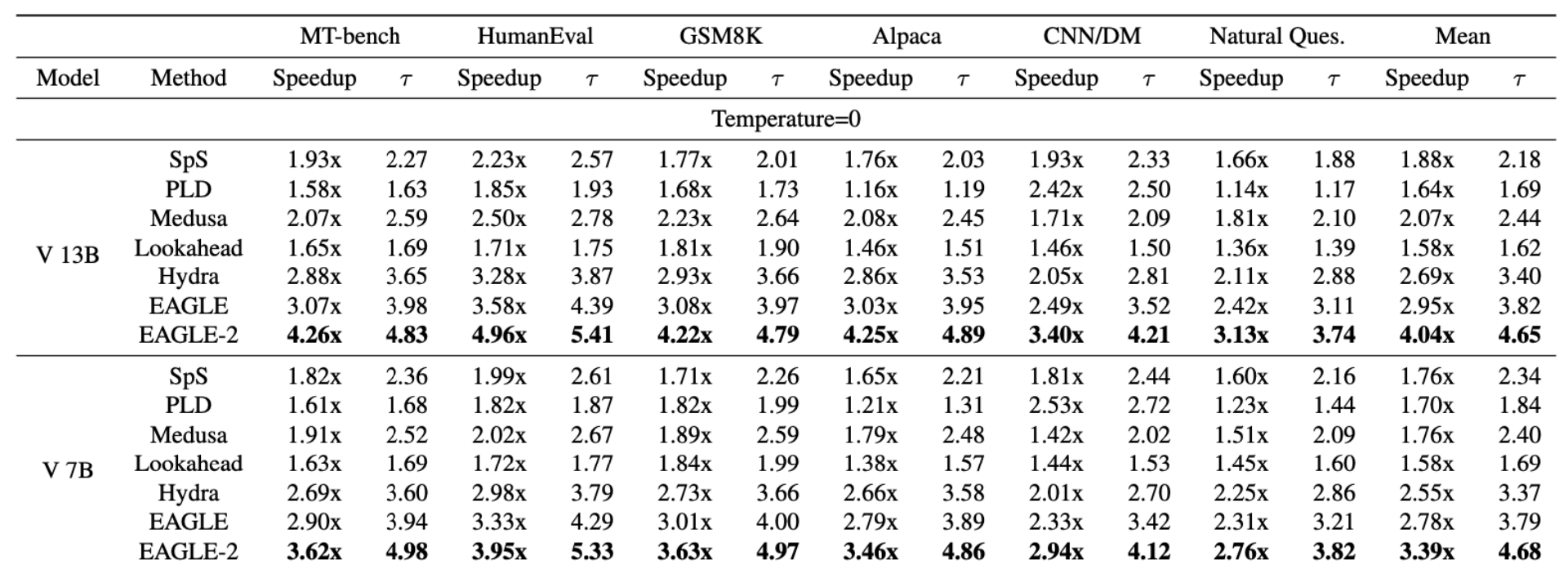
官方结果
- 4x faster than vanilla decoding (13B).
- 1.4x faster than EAGLE-1 (13B).

EAGLE-3:多层特征融合
https://arxiv.org/pdf/2503.01840
个人评价:feature 雕花 + 训推一致 + 让模型学更难的东西(预测 token vs. 预测 feature)。
EAGLE-3 的动机
动机一:基于 EAGLE-2,发现增加训练数据量并不能增加 Draft Model 的平均接受长度。
期望平均接受长度能随着训练数据量的增加而提高。
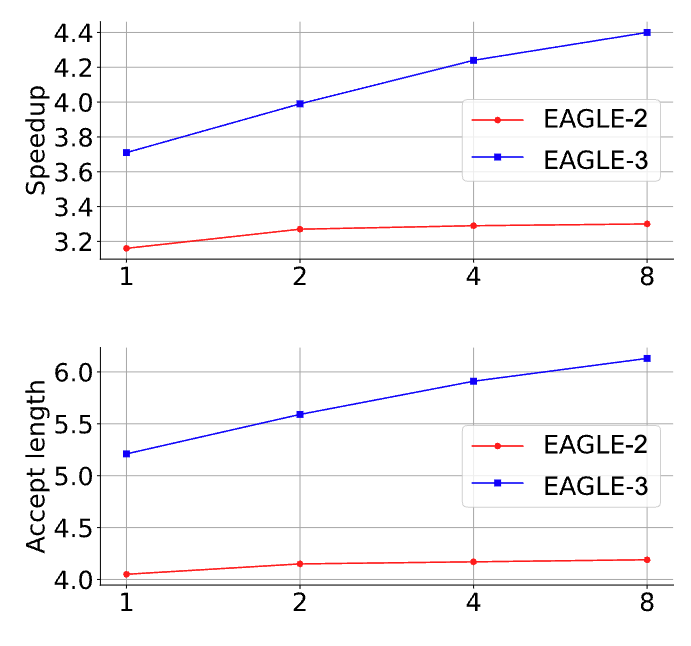
- 横坐标是相对于 ShareGPT 训练数据量,1x、2x、4x、8x
- ShareGPT 是一个数据集
动机二:特征误差会不断累积
EAGLE 的本质是想用 Draft Model 的输出特征来近似 Target Model 的输出特征。
而随着 Draft Model 生成的 token 越多,那么这个近似就会越来越不准(特征误差累积)。
(每次 Target Model 校验后,这个误差会归零)
- $ft$ 后面会不断增加 $\hat{f}{t+1}$ 、 $\hat{f}_{t+2}$ …
推理
Step 1:输入「How can」,Target Model 生成下一个 token,「I」。同时保存低层特征(l)、中层特征(m)和高层特征(h)
Step 2:拼接低层 l、中层 m 和高层 h 特征,输入至 FC 进行降维,得到融合特征 g
Step 3:拼接 Step 2 的融合特征 g 和 embedding 信息,再过 FC + Decoder Layer(EAGLE-1 中的 One Auto-regression Head)
Step 4:采样生成下一个 token「do」,再生成下一个 token 时,会把之前全部信息保留以进行下一次预测。
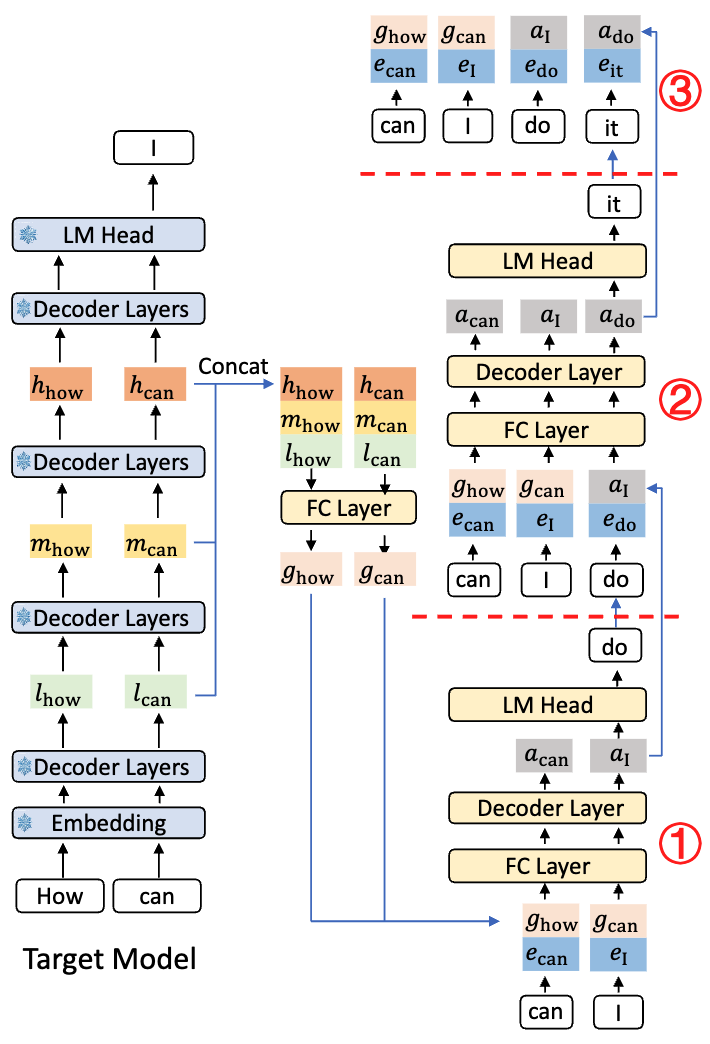
Q:为什么要保留 $g{how}$ 、 $g{can}$ 作为下一次输入,kv cache 已经有了?
A:这里仅做示意,实际代码中无需再输入
EAGLE-1 vs EAGLE-3
架构和输入
| EAGLE-1 | EAGLE-3 | |
|---|---|---|
| 架构 | FC-1:[2*hidden_size, hidden_size]Single Decoder Layer | FC-0:[3hidden_size, hidden_size]FC-1:[2hidden_size, hidden_size]Single Decoder Layer |
| FC-1 的输入 | Target Model 生成的 Feature 和 Embedding | FC-0 生成的 Feature 和 Embedding |
从架构来看,EAGLE-3 中间占用了更多显存(影响并发上限)
训练对比
| EAGLE-1 | EAGLE-3 |
|---|---|
 |
 |
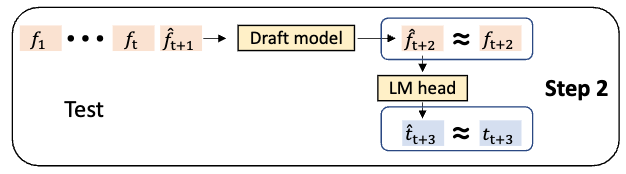
- 在 EAGLE-1 中,这里的 $\hat{f}_{t+1}$ 会随着 Step 的增加而越来越偏(误差累积)
- 而 EAGLE-3 中,移除了这个 feature 的 loss,并且用多步生成的方式训练
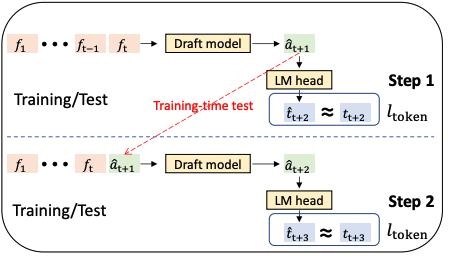
- Draft Model 在第 t 步做出预测 $\hat{a}_t$ 并采样得到令牌 $token_t$ 后,在训练下一步时,它会将自身的预测 $\hat{a}_t$ 和采样得到的 $token_t$ 的嵌入作为输入
- EAGLE-1 会依赖 Target Model 真实的中间特征
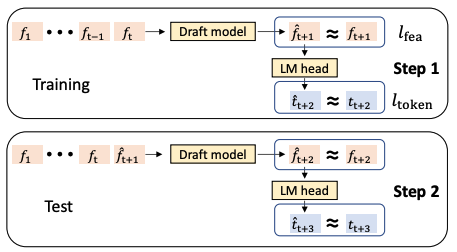
损失函数
- EAGLE-1:特征预测损失 $l{fea}$ + token 预测损失 $l{token}$ = $l{fea}$ + $l{token}$ * 0.1
- EAGLE-3:token 预测损失 $l_{token}$
具体来说
- 特征预测损失 $l_{fea}$ :将下一特征的预测视为回归任务,使用 Smooth L1 损失
- token 预测损失 $l_{token}$ :基于特征预测通过 LM 头计算 token 分布,使用交叉熵损失
比 EAGLE-2 快在哪?
在训练阶段,加大了训练数据。最终提升 Draft Model 的平均接受长度(尽管牺牲了生成 Token 的速度)
模型
- V represents Vicuna
- L31 represents LLaMA-Instruct 3.1
- L33 represents LLaMA-Instruct 3.3
- DSL represents DeepSeek-R1-Distill-LLaMA.
方法
- SpS 标准投机解码,Draft Model 是 Vicuna-68M
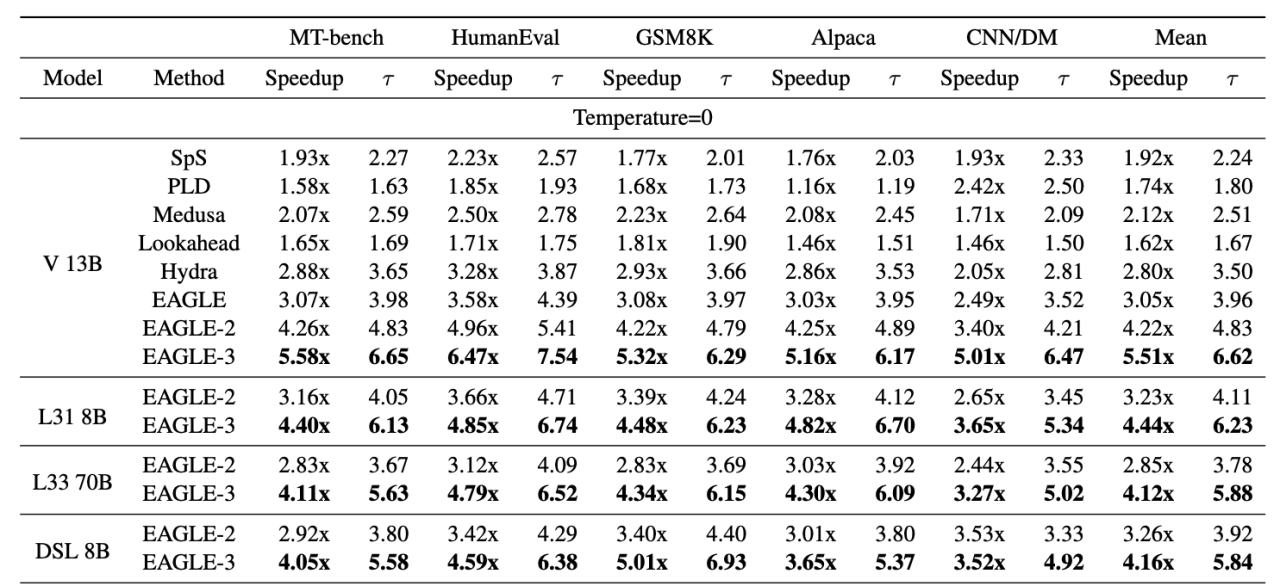
官方结果
- 5.6x faster than vanilla decoding (13B).
- 1.8x faster than EAGLE-1 (13B).
