22 年 12 月:拆解追溯 GPT-3.5 各项能力的起源 | Notion
2022 年 11 月 30 日,ChatGPT 横空出世,它又强又聪明,且跟它说话很好玩,还会写代码。ChatGPT 是怎么变得这么强的?它的各种强大的能力到底从何而来?
GPT-3 的能力
| 能力 | 说明 | 来源 |
|---|---|---|
| 语言生成 | 遵循提示词(prompt),然后生成补全提示词的句子 (completion)。这也是今天人类与语言模型最普遍的交互方式。 | 语言建模的训练目标 |
| 世界知识 | 事实性知识 (factual knowledge) 和常识 (commonsense)。 | 3000 亿单词的训练语料库模型的 1750 亿参数是为了存储知识 |
| 上下文学习 | 遵循给定任务的几个示例,然后为新的测试用例生成解决方案。很重要的一点是,GPT-3虽然是个语言模型,但它的论文几乎没有谈到“语言建模” (language modeling) —— 作者将他们全部的写作精力都投入到了对上下文学习的愿景上,这才是 GPT-3的真正重点。 | 可能来自于同一个任务的数据点在训练时按顺序排列在同一个 batch 中 |
前两项能力的来源是相对明确的。所以,想要讨论 上下文学习 (ICL) 是怎么来的?
ICL 在这里指的是:使用思维链做复杂推理能力 / CoT
复杂推理能力的来源代码数据?
Q & A
Q:怎么理解 Instruction tuning?
A:Instruction tuning 有两个版本,一个是 supervised tuning,另一个是 reinforcement learning from human feedback (RLHF). ChatGPT 就是通过 RLHF 得来的
Q:supervised instruction tuning vs. supervised fine tuning(SFT)
A:
- supervised instruction tuning 使用自然语言作为任务描述,而supervised fine tuning 使用固定格式或标签作为任务描述。
- supervised fine tuning 的数据集包含指令、输入和输出三个部分,而supervised fine tuning 的数据集只包含输入和输出两个部分。
- 我们现在口头表述的 SFT,实际上对应这里的 supervised instruction tuning
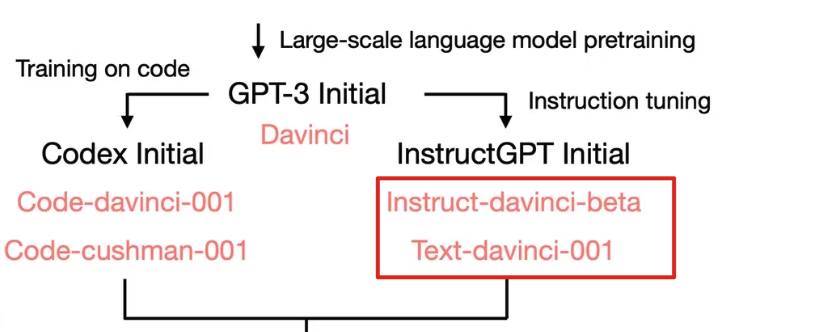
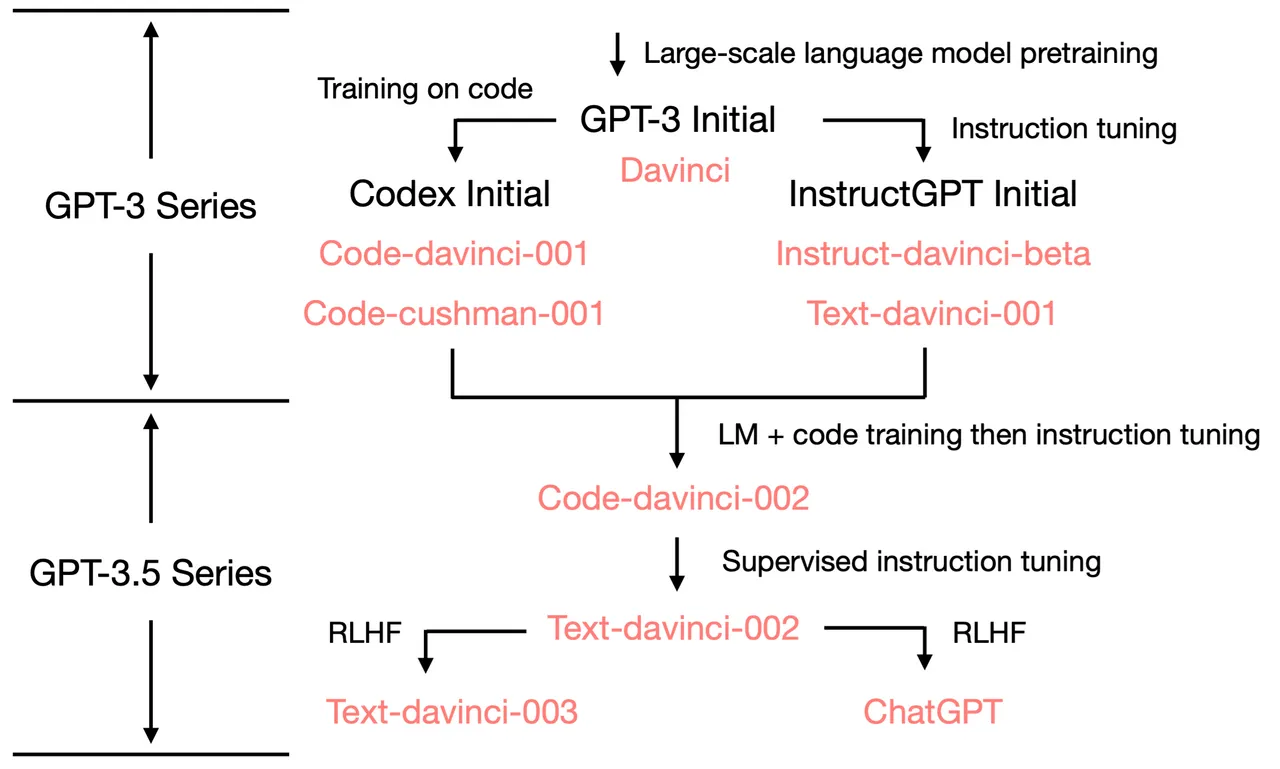
从上往下看,关注 Instruct GPT Initial,发现 davinci-instruct-beta 和 text-davinci-001 效果差 。 → 复杂推理能力不来源这里
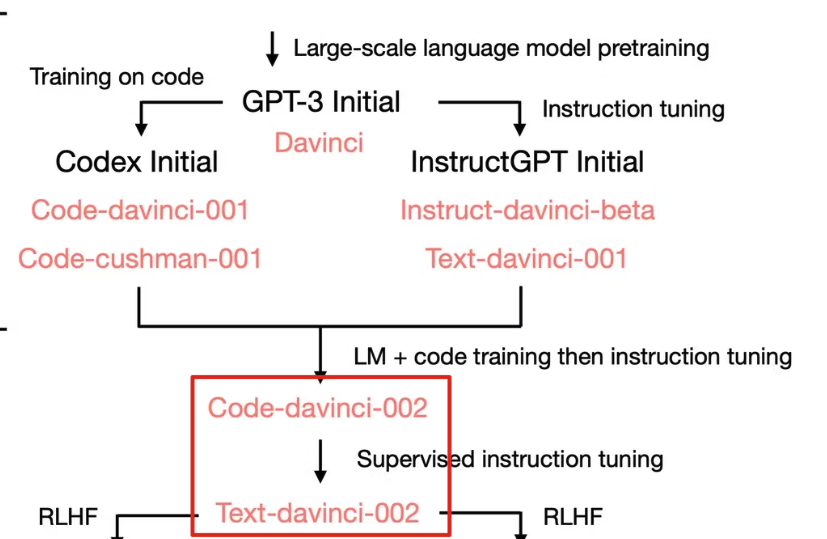
而在 code-davinci-002 和 text-davinci-002 中发现了新的能力,这些能力在 GPT-3 Initial 中没有。
它们的区别在于指令微调(Instruction Tuning)和代码训练(Code Training)。
将能力进行归类
| 指令微调 | 代码训练 |
|---|---|
| 响应人类指令 | 复杂推理能力 |
| 泛化能力 | 长距离依赖 |
进一步解释
| 能力 | 说明 |
|---|---|
| 响应人类指令 | - |
| 指令微调 → 泛化能力 | 指令数量超过一定程度之后自动出现的Sanh. et. al. Oct 2021. Multitask Prompted Training Enables Zero-Shot Task GeneralizationWei et. al. Sep 2021. Finetuned Language Models Are Zero-Shot LearnersChung et. al. Oct 2022. Scaling Instruction-Finetuned Language Models |
| 代码训练 →长距离依赖 | 猜测语言中的下个词语预测通常是非常局部的,而代码通常需要更长的依赖关系来做一些事情,比如前后括号的匹配或引用远处的函数定义由于面向对象编程中的类继承,代码也可能有助于模型建立编码层次结构的能力 |
代码训练 → 复杂推理能力
注意:相关性 Not 因果性
发现下面框出来的模型不能做思维链,共性是都没有经过代码数据训练
- 最初的 GPT-3 没有接受过代码训练
- text-davinci-001 模型,经过了指令微调,但它的思维链推理的能力非常弱
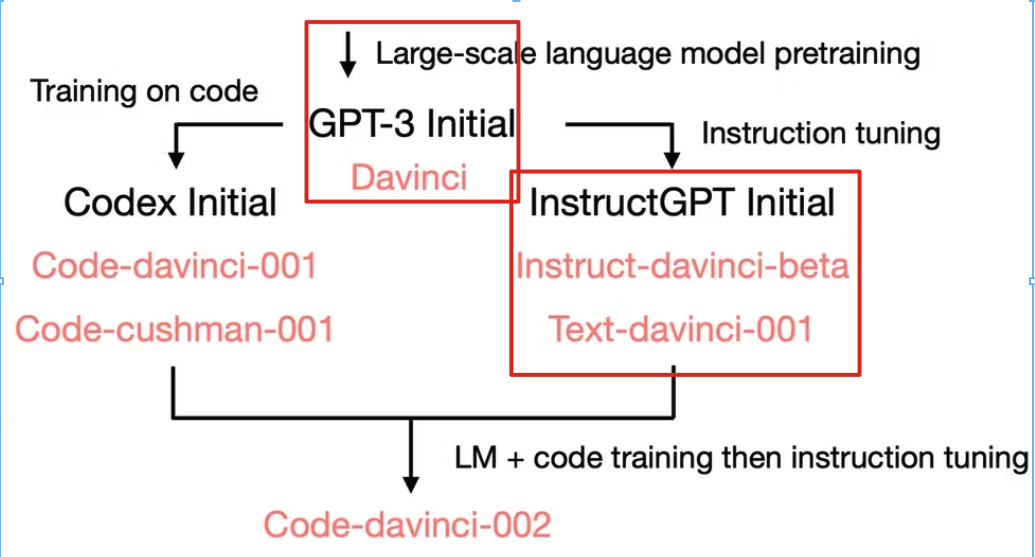
能做思维链的共性:都经过了代码数据训练
- 针对代码训练的模型具有很强的语言推理能力
- code-davinci-002 以及后续变种可以做思维链,并且效果很强
弱解释
- PaLM 有 5% 的代码训练数据,可以做思维链
- 直觉来说,面向过程的编程 (procedure-oriented programming) 跟人类逐步解决任务的过程很类似,面向对象编程 (object-oriented programming) 跟人类将复杂任务分解为多个简单任务的过程很类似
悬而未决
区分代码训练和指令微调效果的最好方法可能是比较 code-cushman-001、T5 和 FlanT5
- 因为它们具有相似的模型大小(110亿 和 120亿),相似的训练数据集 (C4),它们最大的区别就是有没有在代码上训练过 / 有没有做过指令微调。
- 目前还没有这样的比较。我们把这个留给未来的研究。
复杂推理能力是激发还是注入?
能力是否已经存在于 GPT-3 Initial 中,只是通过指令和代码训练激发? 或者是通过指令和代码训练注入能力?
主要猜测是激发,理由如下
数据量
- OpenAI 的论文报告的指令数据量大小只有 77K,比预训练数据少了几个数量级
- Flan-PaLM 的指令微调仅为预训练计算的 0.4%
基座模型
- code-davinci-002 的基座可能不是 GPT-3 Initial(初代 GPT-3)
猜测原因
| 训练数据集的时间 | 上下文长度(绝对位置编码) | |
|---|---|---|
| 初代 GPT-3 | 在数据集 C4 的 2016 - 2019 上训练 | 2048 |
| code-davinci-002 | 21 年才结束,有可能在 C4 的 2019-2021 上训练 | 8192 |
用绝对位置编码无法直接扩充上下文长度,所以猜测是训练了新模型。
- text-davinci-001 有时甚至比参数量更小的 code-cushman-001 还差。
利好 Code 预训练数据
(因为大家看好激发 + 代码预训练数据),所以会有利好 Code 预训练数据的相关研究 :
ICL ⇋ 对话能力
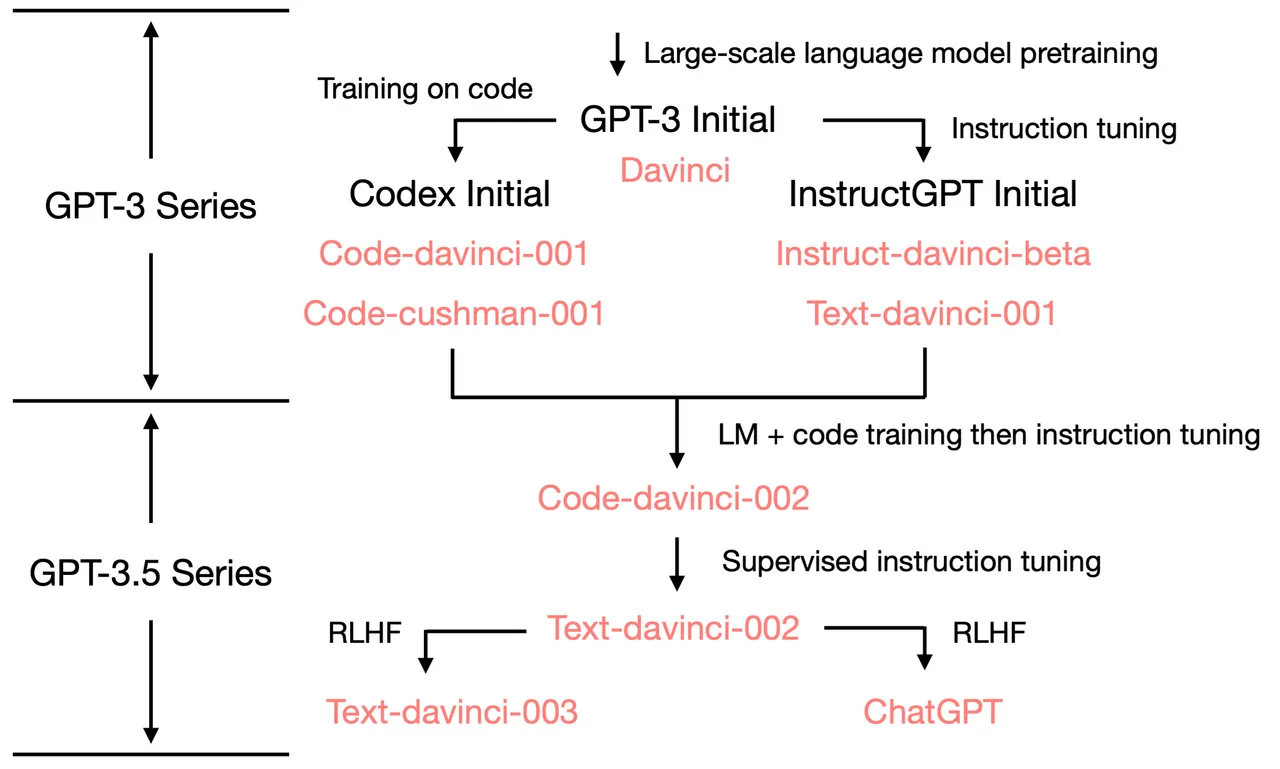
分化了两个模型
- ChatGPT:基于经验的观测结果,ChatGPT 似乎不像 text-davinci-003 那样受到 in-context demonstrations 的强烈影响。(?)
- text-davinci-003:恢复了 text-davinci-002 所牺牲的上下文学习能力,根据 InstructGPT的论文,这是来自于强化学习调整阶段混入了语言建模的目标(而不是 RLHF 本身)。
下一篇:LLM 复杂推理的来源分析II