A Survey on In-context Learning
On the Effect of Pretraining Corpora on In-context Learning by a Large-scale Language Model
In-context Learning and Induction Heads
24 年 10 月:A Survey on In-context Learning —— Analysis
预训练数据的多样性
On the Effect of Pretraining Corpora on In-context Learning by a Large-scale Language Model
语料库的来源
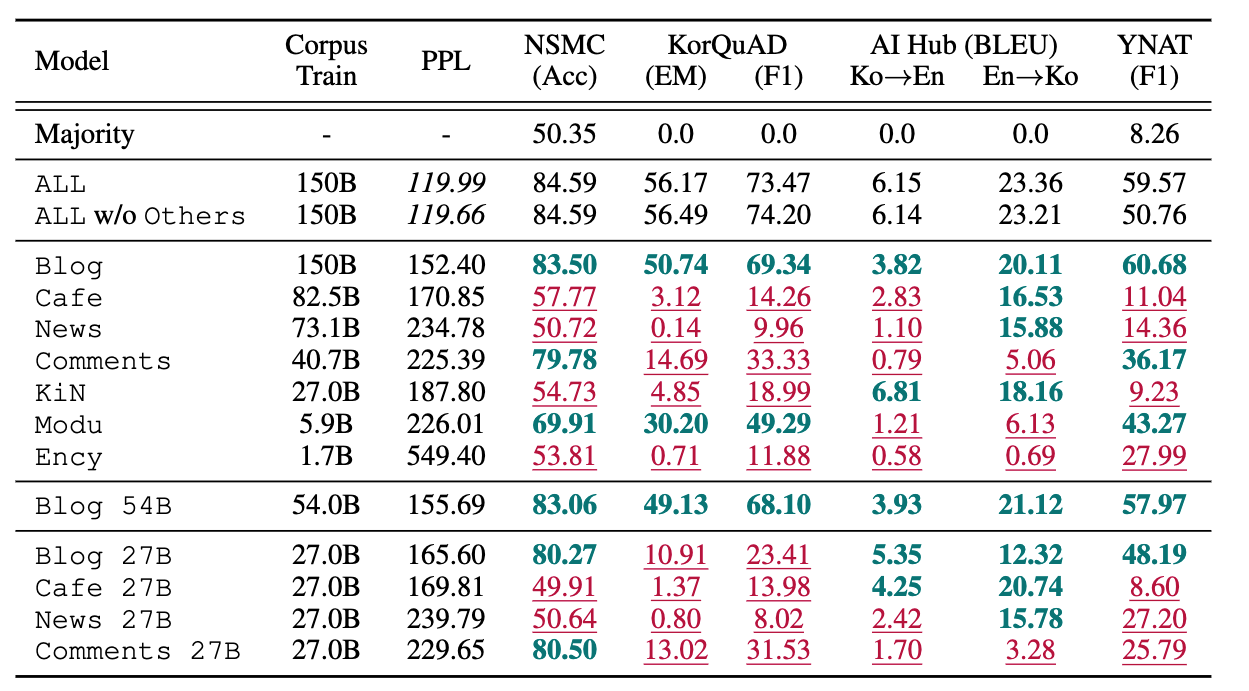
说明
- 左侧列是语料库;最上面一行是指标(用 Few-Shot 评测)
- 下划线表示低于平均值(ALL 和 Majority 的平均值),加粗表示高于平均值
- 1.3B 模型
发现:比较不同单一语料库模型(如Blog、Cafe、News)的性能,上下文学习能力高度依赖于语料库的领域来源。比如,Blog 54B
语料库的多样性
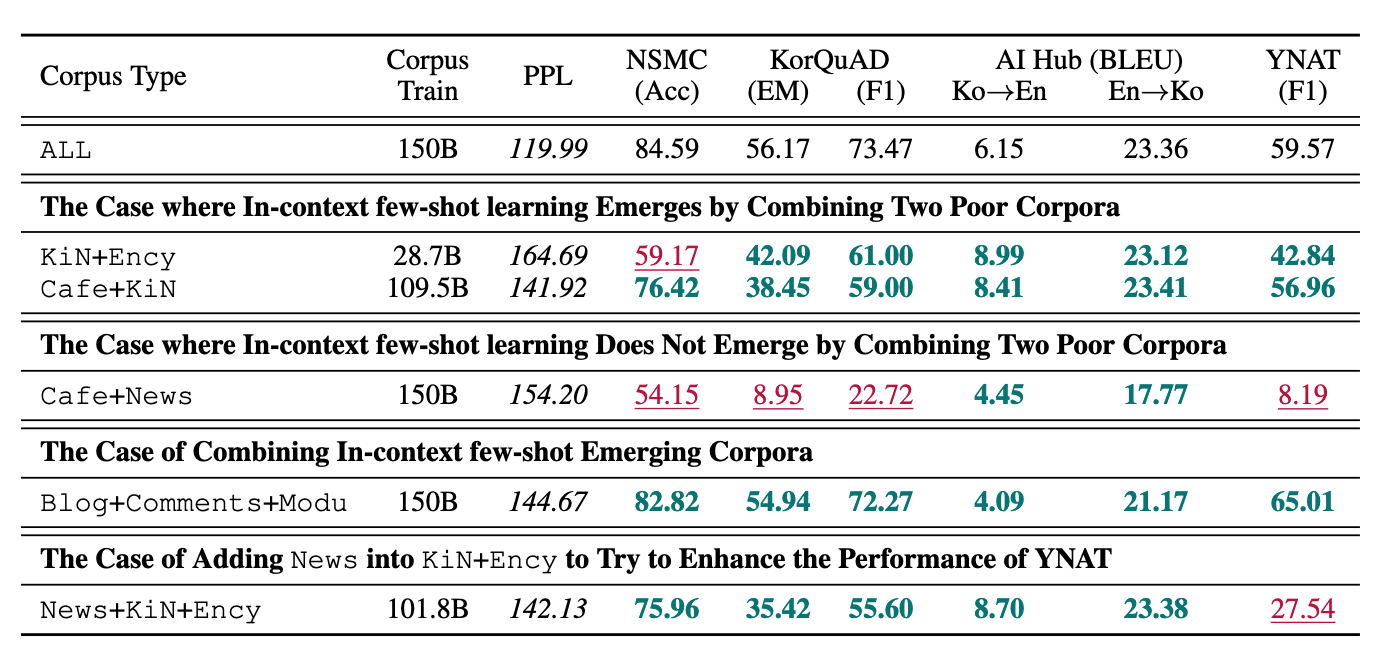
发现:
- 单独使用 Cafe 或 KiN 语料库时未观察到上下文少样本学习能力,但组合训练两者(KiN+Ency)则使这种能力得以出现。
- 但并非所有组合都有效(如Cafe+News组合可能表现不佳甚至下降)
语料库的大小
用单一语料库 HyperCLOVA 训练
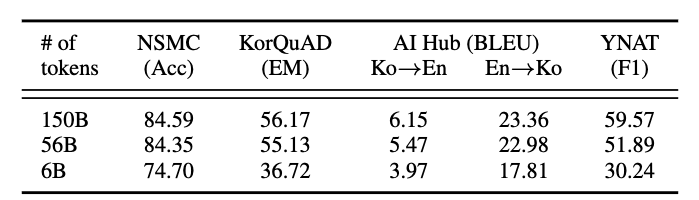
- 数据量很重要:6B → 56B 会有显著提升
- 多样性很重要:56B → 150B 并不会有显著提升
模型架构 —— Attention
In-context Learning and Induction Heads
评测分数:上下文中第 500 个 token 的 loss - 第 50 个 token 的 loss,取平均。
怎么理解这个评测指标
背景知识:现代语言模型中,语境中后面的标记(token)比前面的标记更容易预测,即随着语境变长,损失(loss)会下降。
→ 利用更长的语境信息,从而提高预测能力的现象,就是所谓的上下文学习(In-context learning)
Loss 的下降意味着模型的预测能力得到提高(提高了 ICL 能力),即第 500 个 token 的损失低于第 50 个标记的 token(Loss(500) < Loss(50))。
因此 Loss(500) - Loss(50) 的结果通常为负值。分数越负,表明模型的 ICL 能力越强
一条样本有 512 个 token:
- 选择第 500 个 token 是因为它接近 512 个 token 的末尾
- 选择第 50 个 token 是因为它在语境中足够靠后,足以建立文本的一些基本属性(如语言和文档类型),但又足够靠前,仍接近开头
- 研究表明,选择不同的标记索引并不会改变其结论
10k 条样本,取均值。
Q:为什么是看差值,而不是第 500 个 token 的 loss?第 500 个 token 也是看了前面所有 token,也能说明 ICL?
A:
- 单独看第 500 个 token 的 loss,只能反映模型在该语境长度下的最终预测效果,无法体现语境的增长对预测能力带来了多少提升。
- 如果只看第 500 个 token 的 loss ,大模型无疑会表现出更低的 loss。但这并不能直接说明其上下文学习比小模型更强
结果
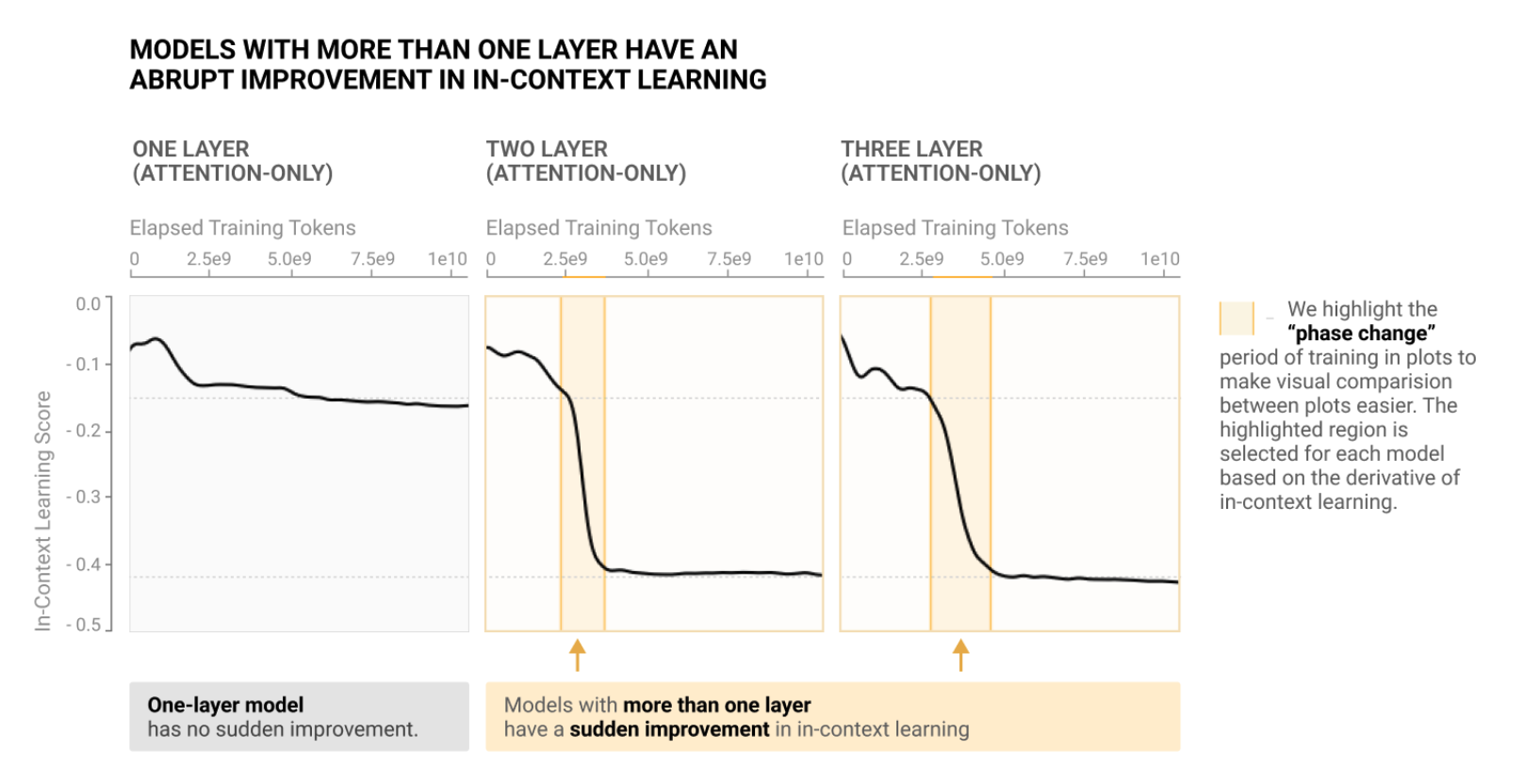
- 如果只有一层,随着训练 token 增加,分数不会显著变化
- 当有 2-3 层 attention 的时候,会在某个时间发生“相变”
Q & A
Q:为什么是 Attention?
A: