LIMA: Less Is More for Alignment
假设:模型的知识和能力几乎完全在预训练阶段学习,SFT 只是激发模型能力
数据
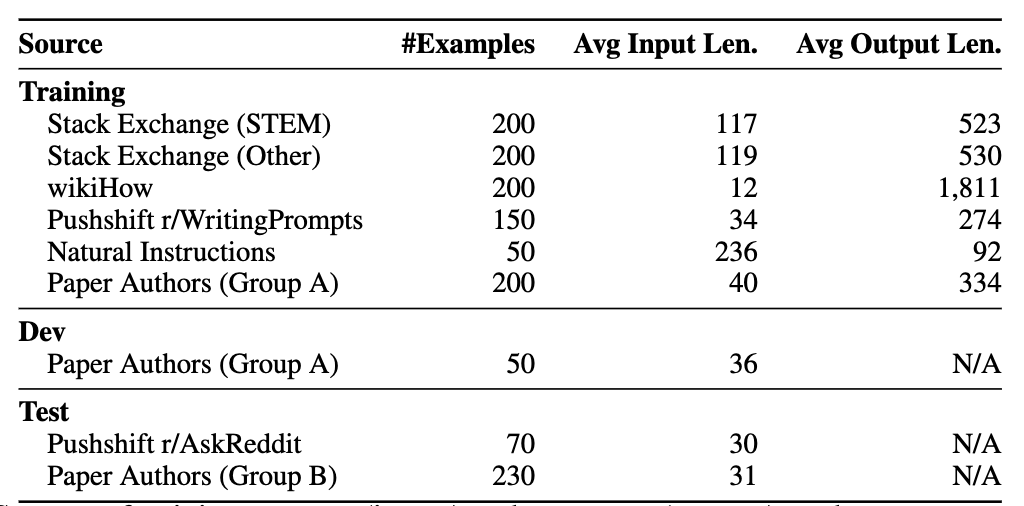
- 多样性:不同来源
- 高质量:手动撰写了 200 条 高质量回复 + 人工挑选 800 条数据
基于 LLaMa 65B 进行训练
评测
Q & A
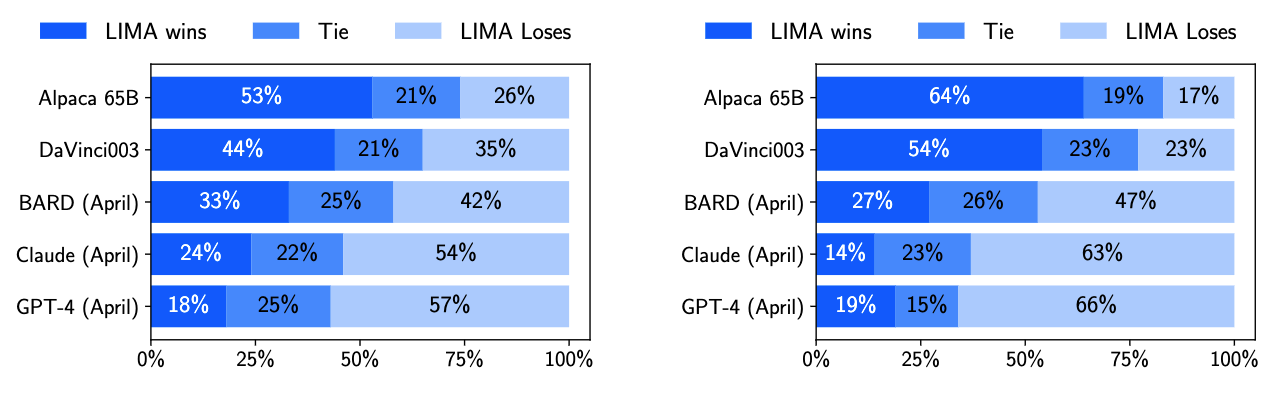
- 300 条测试数据
- 左图是人工打分,右图是 GPT-4 打分
表现可以堪比 GPT-4(Win+Tie = 43%)
Multi-Turn Dialogue
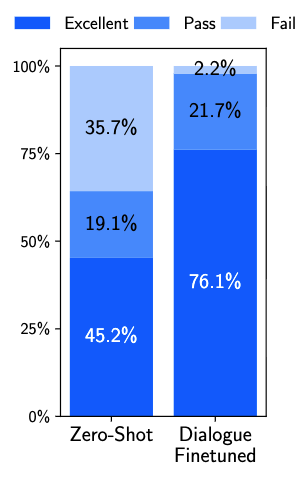
- Zero-Shot:在 1k QA 数据上训练的模型评测
- Dialogue-Finetuned:1k + 30 条多轮对话数据训练的模型评测
所以,QA 数据训练的模型是具备对话能力的;加入 30 条对话数据可以“强化” 模型的对话能力