Accelerated Test-Time Scaling with Model-Free Speculative Sampling
STAND(STochastic Adaptive N-gram Drafting),无模型投机解码
动机
Prompt Lookup 背景见:LLM的推理加速-Prompt Lookup
文章对 Prompt Lookup 进行了优化。达到了更好的加速效果。
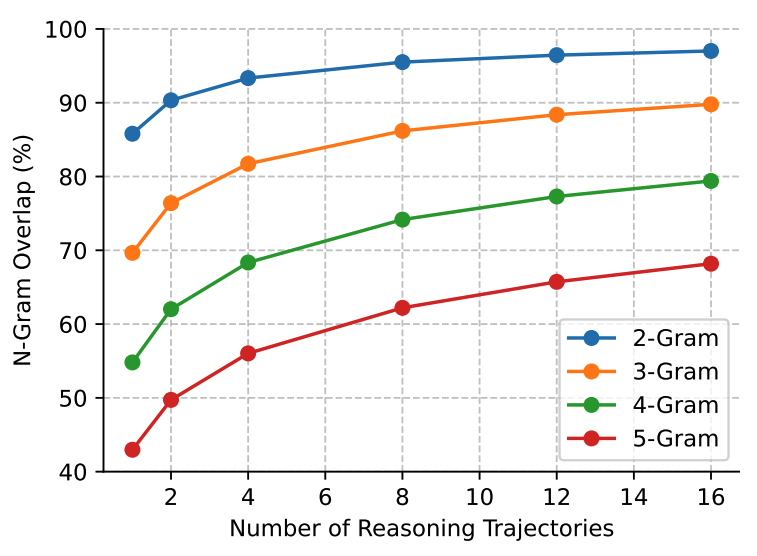
使用 DeepSeek-R1-Distill-Qwen-7B 在 AIME-2024 数据集上发现有大量的 n-gram 重复轨迹。
Gumbel-Top-K 并行采样
通常在使用 top-k 采样的时候会需要三步,
- 从分布中找到最大的 k 个概率
- 将 k 个概率重新归一化
- 从归一化后的 k 个概率值中再采样
代码实现
1 | import torch |
Gumbel-Top-K 并行采样只需要一步就能直接对原始的分布进行 top-k 采样。
主要利用了Gumbel噪声,其生成过程为
- 从标准均匀分布 $U(0,1)$ 中生成一个随机数 $u$。
- 通过以下公式计算 Gumbel 噪声 $g$:
通过将这个噪声与原分布相加,即可直接采样得到 top-k 采样。其具备数学理论保证。
1 | import torch |
STAND 方法
构建查找树
第一次见到 I am 这个输入,生成的 top-3 token 及其概率如下表所示
| token | 概率 |
|---|---|
| Bob | 0.7 |
| Mary | 0.2 |
| Tom | 0.05 |
graph TD
A[I] --> B[am]
B --> C[Bob, 0.7]
B --> D[Mary, 0.2]
B --> E[Tom, 0.05]
当第二次见到 I am 输入的时候,会对这个树进行更新,假设此时生成的 top-3 token 及其概率为
| token | 概率 |
|---|---|
| Bob | 0.3 |
| Mary | 0.6 |
| Sue | 0.05 |
此时会更新每个节点的概率,
- 对于之前的所有 token,给权重 $k{prev} / (k{prev} + 1)$。在第二次的时候,就是 1 / (1 + 1) = 0.5
- 对于新见到的 token,给权重 $1 / (k_{prev} + 1)$。在第二次的时候,是 1 / (1 + 1) = 0.5
即每次更新的 token 权重会越来越弱。
再结合之前的概率,和新见到 token 的概率,重新计算
| token | 概率 |
|---|---|
| Bob | $0.7\times 0.5+0.3\times 0.5 = 0.5$ |
| Mary | $0.2\times 0.5+0.6\times 0.5 = 0.4$ |
| Tom | $0.05\times 0.5=0.025$ |
| Sue | $0.05\times 0.5=0.025$ |
所以,树会更新为
graph TD
A[I] --> B[am]
B --> C[Bob, 0.5]
B --> D[Mary, 0.4]
B --> E[Tom, 0.025]
B --> F[Tom, 0.025]
每次更新树时(或者某个时机),会对这颗树进行裁剪,只保留概率最高的前10个token及其对应的概率进行存储。
从实验结果来看,这颗树会变得深且宽。
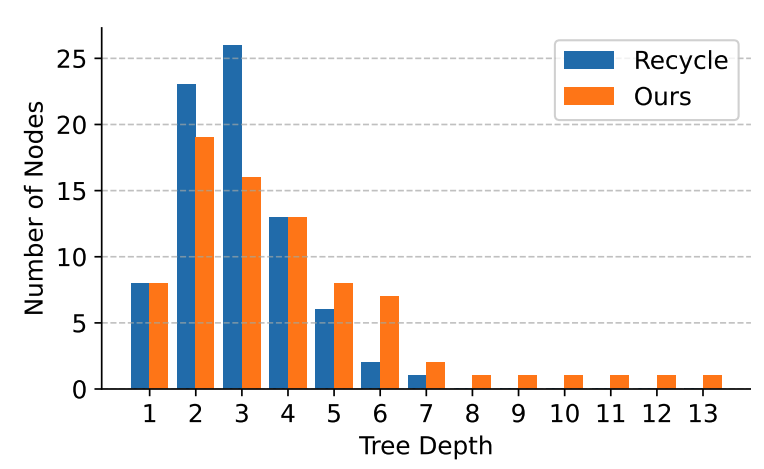
深度 意味着,STAND 在推理阶段可以一次性提供很长的 token 序列以供校验。
推理阶段
会从 4-gram 开始在表中搜索,逐步减少至 2-gram。如果 4-gram 查到了,那就不需要搜 3-gram 了
假设在 4-gram 的时候搜索到 Let x be the
在表中查到了下面这颗树。
graph TD
A[Let x be the] --> B[variable, 0.8]
A --> C[unknown, 0.5]
A --> F[integer, 0.025]
B --> D[y, 0.4]
C --> E[quantity, 0.025]
在下一个子节点中找到 10 个概率最大的 token,再从中用 Gumbel-Top-K 并行采样 k 个 token。
不断循环,直至抵达叶子节点。
获取到这些候选句子后,进行并行地校验。
结果
构建查找树的是先验的,即是一颗静态树。会初始化一棵有 625个节点的大树,然后对 AIME-2024 数据集中的 30 个样本进行推测解码。最后选出最有效的前 80 个节点,并将它们重组为一个紧凑的树形结构。
- Trajectories -> 轨迹,生成 N 次的结果
- AIME/GPQA/LCB -> 不同评测集
- T/A -> 表示吞吐量和平均接受长度
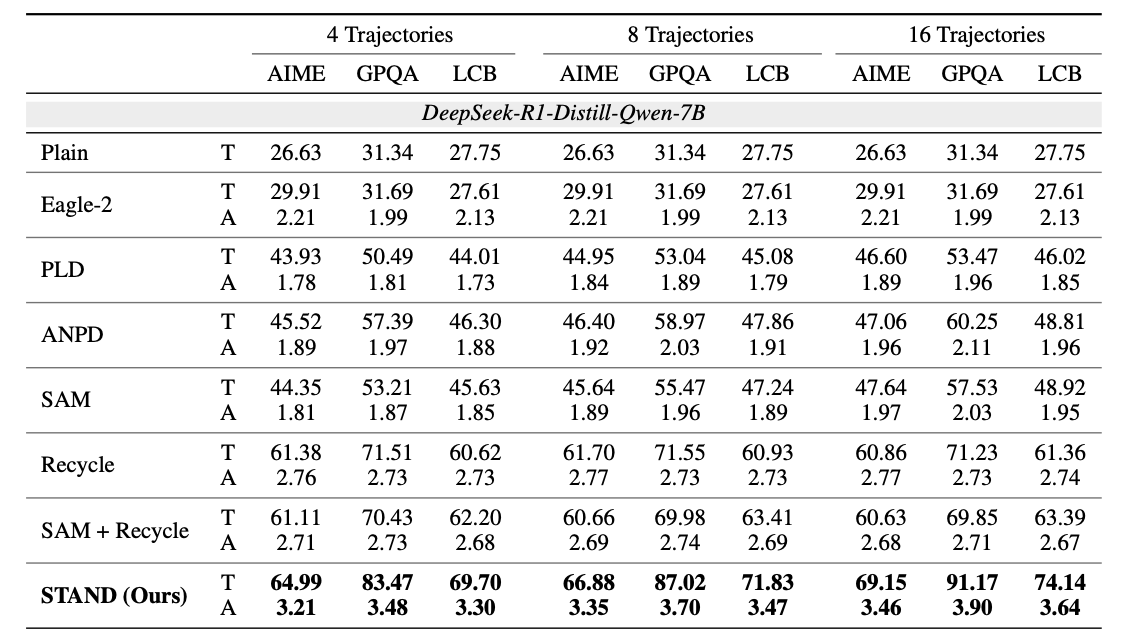
这里并没有放模型效果指标,想必是结果不会差。只放了速度对比。其比较大的优势是在采样生成多个句子的时候,收益会更显著。
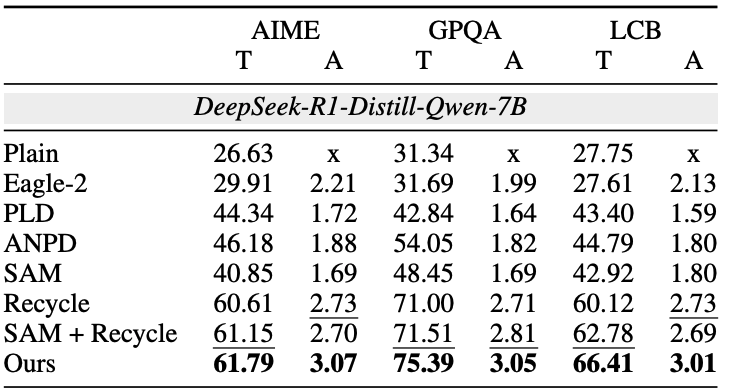
只生成一次的情况下,也有速度优势。
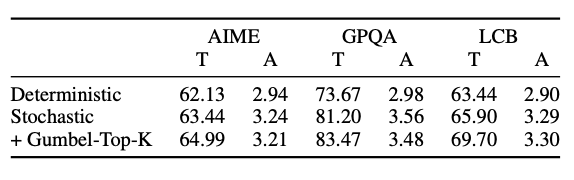
消融实验,验证了 Gumbel-Top-K 会增加一点点速度,比直接贪心选择候选 token 会更快。

- Heuristic/Optimized -> 动态构建树和预先构建好树
- Acc. Lens -> 平均接受长度
- IND/OOD -> 域内和域外
证明
- 预先构建好树会有效果上的提升
- 通过 A 数据集(IND)构建好树,在 B 数据集(OOD)上也会有速度收益