本文介绍 Qwen3.5 在注意力机制上的两大变化:Gated Softmax Attention(Q/K Norm + Gate)与线性复杂度的 Gated DeltaNet。文中说明二者混合比例(每四层中三层为 DeltaNet)、从标准 Attention 到线性 Attention 的数学推导、DeltaNet 的状态递推与门控设计,以及和 Mamba 等工作的联系,便于理解 Qwen3.5 在长序列与推理效率上的取舍。
概述
Qwen3.5 在架构上引入了显著的变化,主要体现在两种 Attention 机制的混合使用:
- Qwen3.5 Attention:官方也称为 Gated Softmax Attention,在标准 Attention 基础上增加了 Q/K Norm 和 Gate 参数
- Gated DeltaNet:一种线性复杂度的 Attention 变体,旨在优化长序列处理性能
混合比例:每四层 Attention 中有三层是 Gated DeltaNet。
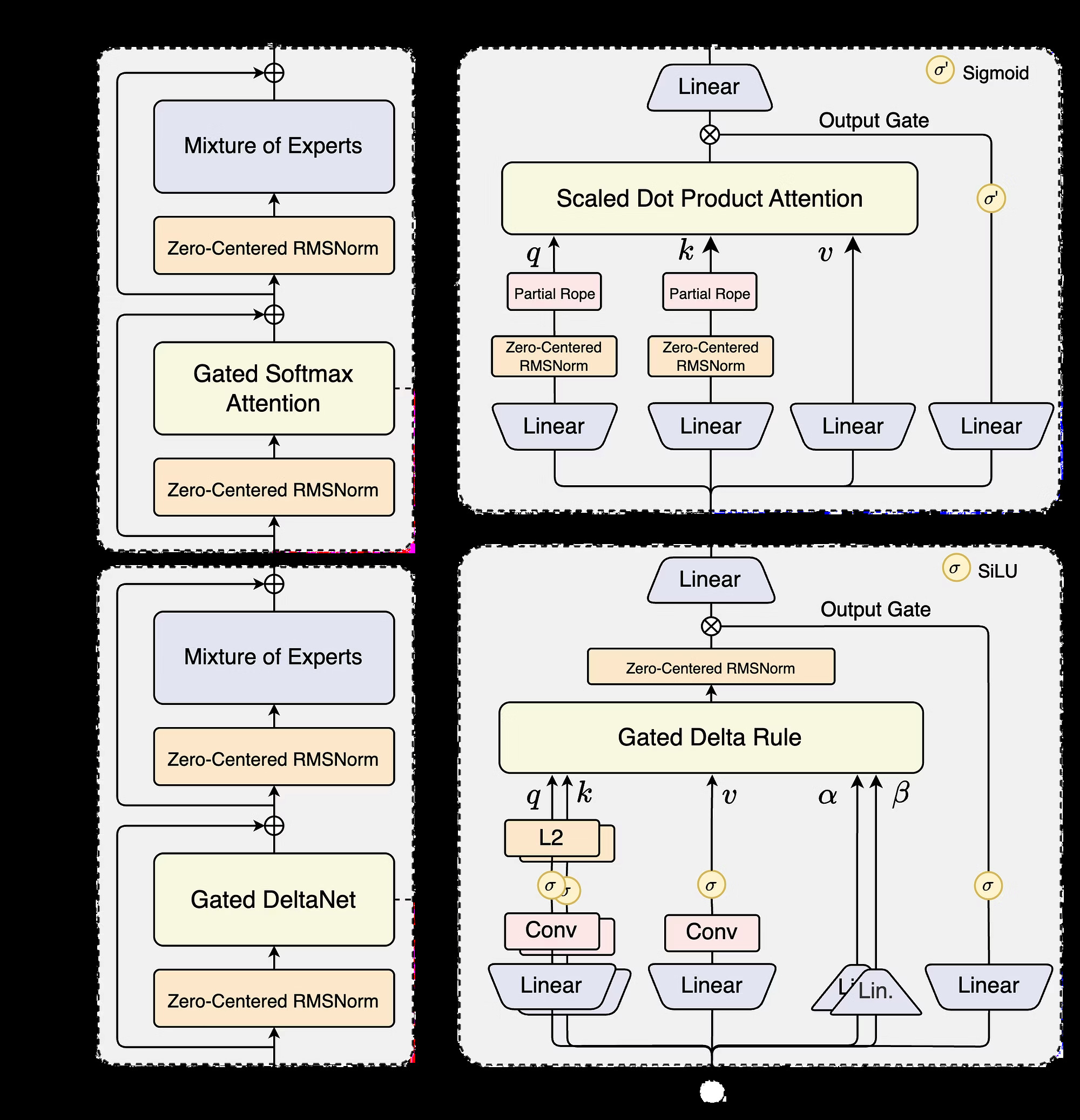
图:Qwen3.5 混合架构 - 左侧为层级堆叠(Gated Softmax Attention 和 Gated DeltaNet),右侧为各层的详细结构
计算量与参数量对比
| 特性 | 标准 Attention | Qwen3.5 Attention | Gated DeltaNet(重点优化) |
|---|---|---|---|
| 计算复杂度 | $O(n^2)$ | $O(n^2)$ | $O(n)$ |
| 参数量 (Attn层) | 基准 (1×) | 约 +25% (Q/Gate翻倍) | 约 +30% (多路投影+卷积) |
性能提升:
- 同参数量的 Qwen3.5 推理速度会比传统模型更快
- 还有更快的空间,因为标准 Attention 工程优化已经很多了,而 Gated 相关优化才刚刚开始
- 特别利好长序列任务(>8k)
Qwen3.5 Attention
核心改进
从图中的对比可以看到,Qwen3.5 Attention 在标准 Attention 的基础上,额外引入了:
- Q/K Norm:归一化处理
- Gate 参数:门控机制
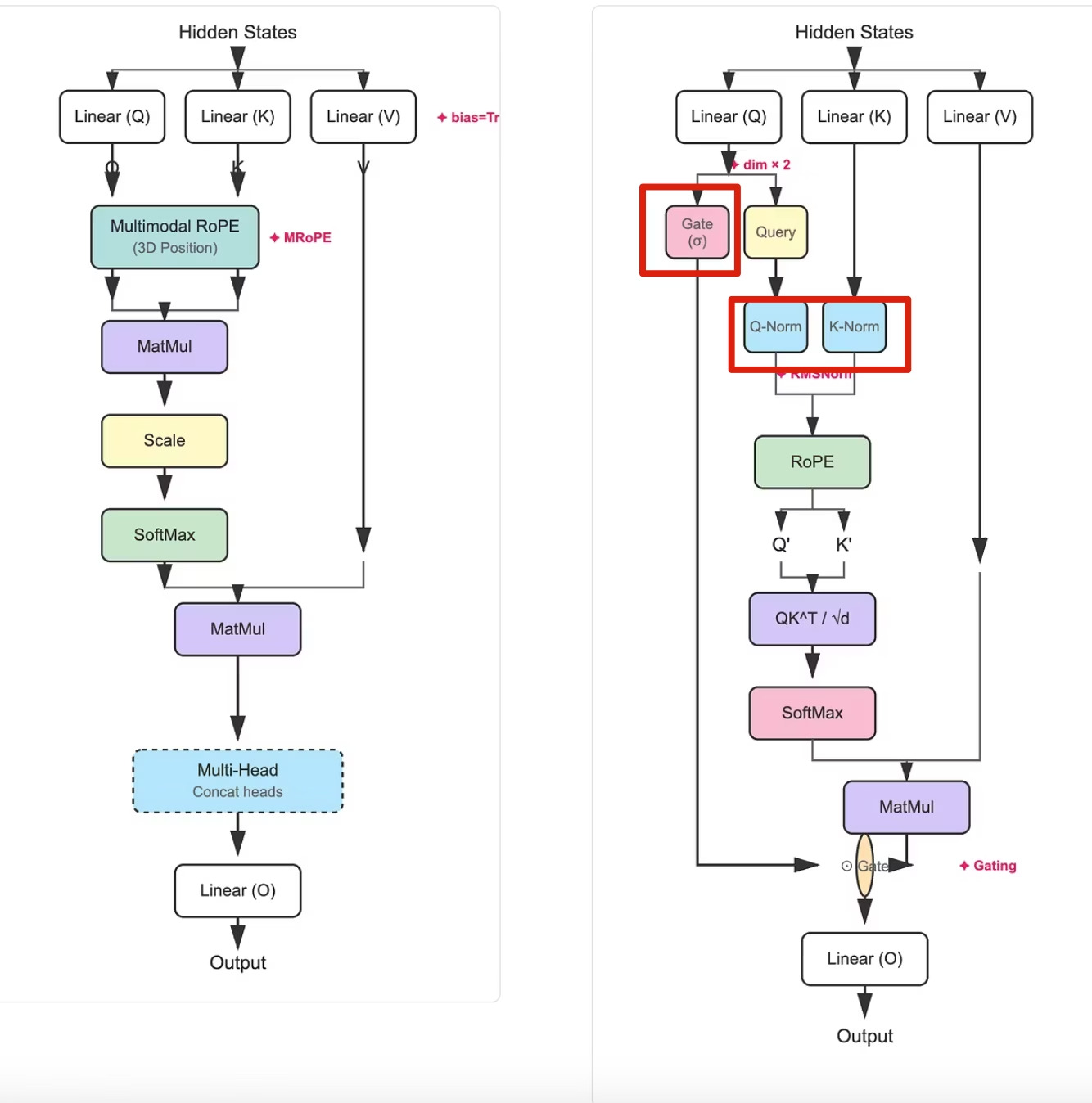
图:左侧为标准 Attention,右侧为 Qwen3.5 Gated Attention,红框标注了新增的 Gate 和 Q/K Norm 组件
三个关键问题
Q1: 为什么要引入 Q/K Norm?
- A:使用 Q/K Norm 可以稳定训练,防止梯度爆炸/消失
Q2: 为什么要引入 Gate 参数?
- A:使用 Gate 增强模型表达能力,选择性地传递信息(受 Mamba 启发)
Q3: 为什么 Gate/Norm 要放在这几个地方?
- A:简而言之,实验来的。参考之前的论文分享:qwen-gated attention for llms
从标准 Attention 到线性 Attention

图:三代 Qwen 架构的演进 - Qwen2-VL Attention(左),Qwen3Next Gated Attention(中),Qwen3.5 Gated DeltaNet(右)
动机
类似工作:DeepSeek 提出的 MLA(Multi-head Latent Attention)
核心思想:改变计算顺序
| 方式 | 计算步骤 | 核心矩阵大小 | 总体复杂度 |
|---|---|---|---|
| 传统 Attention | $QK^T V$ | $(n \times n) \times d$ | $n^2 d$ |
| 线性 Attention | $Q(K^T V)$ | $n \times (d \times d)$ | $nd^2$ |
关键:Q 的形状是 $n \times d$,K 形状是 $d \times n$,V 的形状是 $n \times d$。$K^T V$ 两先乘可以把 n 消掉,就能降低复杂度。
数学推导
原始公式
展开为逐 token 形式:
用核函数替换 exp
代入原公式
把公式展开:
最后一步只是把括号里面的变量定义了一下,实际没有发生任何变化。
这里把 $S_t$ 叫做 t 时刻的状态空间(State),存储了历史信息(类似于 KV Cache)。
状态空间(State)
考虑 t-1 的状态:
从线性 Attention 到 Gated DeltaNet
核函数的问题
传统做法选择了 ELU 这个核函数(满足非负性要求 + 避免梯度消失 + 一阶可导):
其中:
问题:发现它是一个局部线性的激活函数,它让分布变得太均匀了。
如下图所示,softmax 是稀疏的,而 elu 是”均匀”的(稠密?)
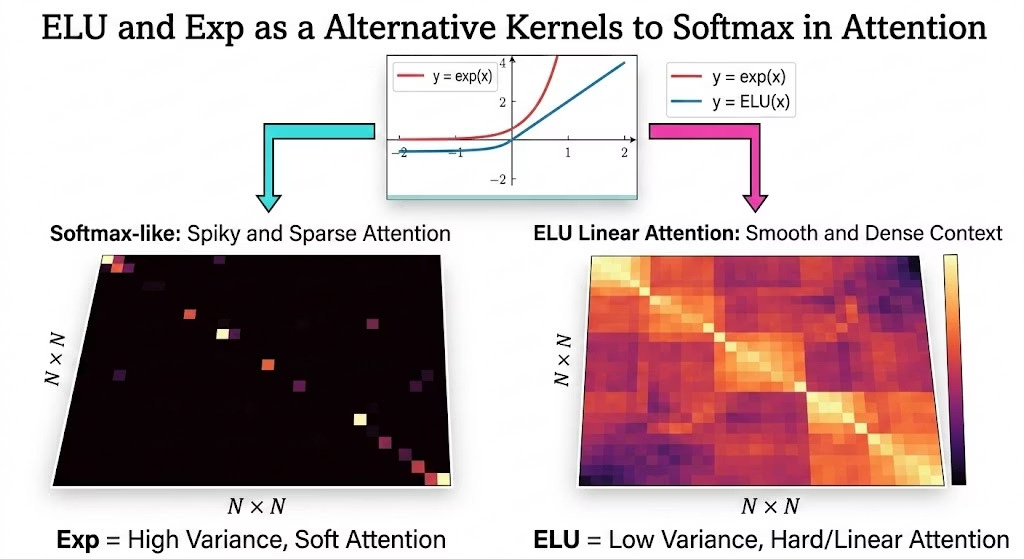
图:Softmax 产生稀疏的注意力模式(左),而 ELU 线性注意力产生稠密的注意力模式(右)
ELU vs. RWKV vs. Mamba
- RWKV:找到了去北京的高速公路(Attention 的快速路径)
- Mamba:坐飞机去北京(完全不同的交通系统 - SSM)
Mamba 的理念:直接放弃 softmax 这套规则(放弃核函数),从控制理论出发 SSM(状态空间模型)

图:三种方法的代码实现对比 - 理论 Linear Attention(左),RWKV(中),Mamba SSM(右)
组件对比
| 组件 | 线性注意力 | Mamba (Selective SSM) |
|---|---|---|
| 状态 (State) | $S_t$ | $h_t$ |
| 状态更新逻辑 | $St = 1 \cdot S{t-1} + \phi(k_t)v_t$ | $ht = \bar{A} h{t-1} + \bar{B} x_t$ |
| 输出逻辑 | $o_t = \phi(q_t)^T S_t$ | $y_t = C h_t$ |
线性注意力通过核函数映射 $\phi$ 实现了计算顺序的重排,从而获得了线性复杂度。
相比之下,Mamba 抛弃了预定义的核函数,转而通过选择性系统(Selective System):
- 将状态转移从单纯的加法(系数为 1)变为指数衰减(系数为 $\bar{A}$)
- 将信息的存入过程从核函数映射变为动态线性变换($\bar{B}$)
比喻
- $h_{t-1}$ 是学生大脑里已经记住的知识(旧状态)
- $x_t$ 是老师现在正在说的一句话(当前输入)
- $\bar{A}(x_t)$ 是学生根据这句话,决定要把脑子里之前的知识忘掉多少
- $\bar{B}(x_t)$ 是学生根据这句话,决定要把多少新内容记到脑子里
- $C(x_t)$ 是学生根据这句话,决定要把多少内容写到笔记本上
Qwen3.5 的关键改进
1. 使用 L2 归一化
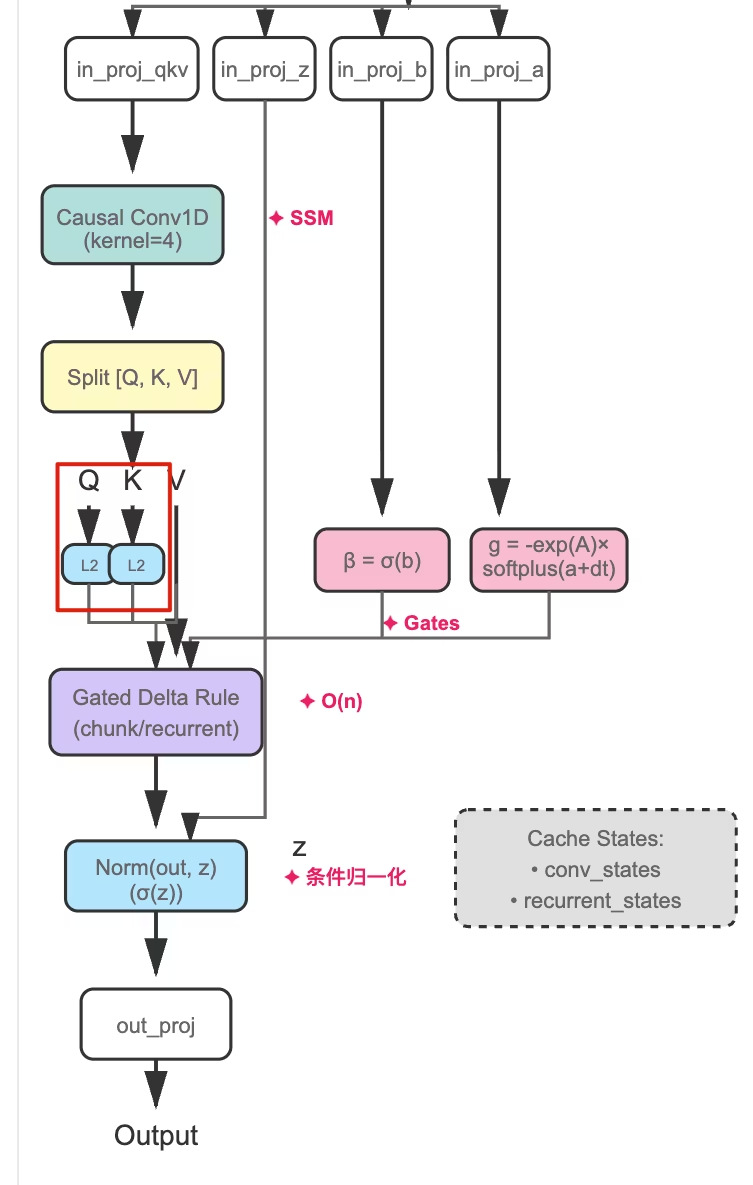
图:Gated DeltaNet 完整架构,红框标注了 Q/K 的 L2 归一化组件
| 特性 | 经典 Linear Attention | Qwen3.5 L2 归一化 |
|---|---|---|
| Q/K 处理 | $\phi(q) = \text{elu}(q) + 1$ $\phi(k) = \text{elu}(k) + 1$ |
$q = \text{normalize}(q, p=2)$ $k = \text{normalize}(k, p=2)$ |
| 优势 | 避免数值溢出 | 数值稳定 + 内积有界 $q^T k \in [-1, 1]$ |
| 表达能力 | - | 比固定 $\phi$ 更具表达力 |
但并没有解决核心问题。
2. 状态空间的问题
标准注意力 vs. 线性注意力
标准注意力:
- 每一个历史 $k_i, v_i$ 都被显式保留
- Softmax 充当了”动态开关”,让模型在 t 时刻可以自己决定给哪个历史 Token 更大的权重
线性注意力:
- 所有的历史信息都被”揉”进了状态空间 $S_t$
- 在求和的时候,第一个词和最后一个词对 $S_t$ 的贡献在数学地位上是绝对平等的(等权加和项)
3. 衰减机制:模糊的过去
原始问题
原公式等权重累积,$S_{t-1}$ 与当前状态权重一致,无法”遗忘”旧信息。
RWKV:引入衰减因子
展开感受一下效果:
但是这样不够灵活,有的信息比较重要,有的不那么重要。所以需要动态控制。
Mamba:动态衰减
所以 $\lambda$ 改成跟 step 相关:
根据输入计算 $\lambda$,引入了权重参数 $W$ 和固定参数 $A$(先验的衰减率,比如 0.9):
但 Mamba 的实践发现这样还是不够,需要分离”遗忘”和”衰减”两个概念。
Qwen3.5:双重门控
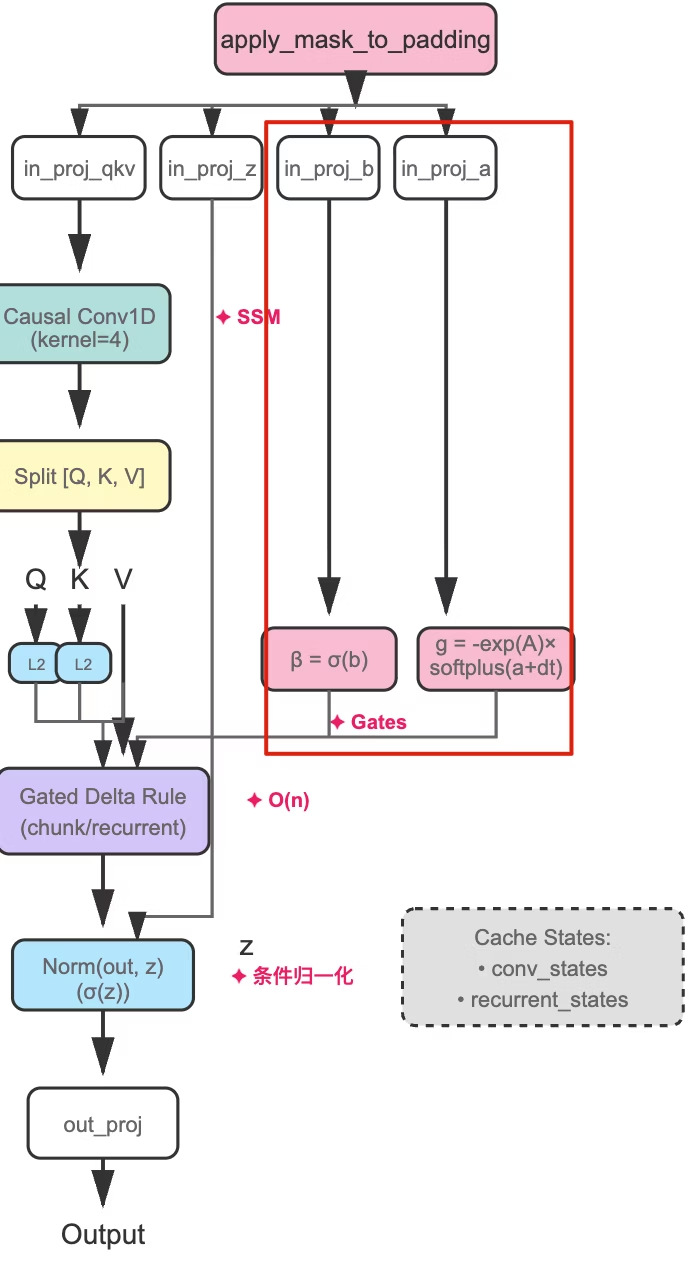
图:Gated DeltaNet 架构,红框标注了双重门控机制(β 和 g)
拆分了两个门控,继续改 $\lambda$:
β 门控(遗忘决策):
- Sigmoid 输出,决定是否遗忘历史状态
g 门控(精细衰减):
- 精细控制衰减幅度,始终为负值确保 $\lambda_t \leq 1$
4. Causal Conv1D:清晰的当下
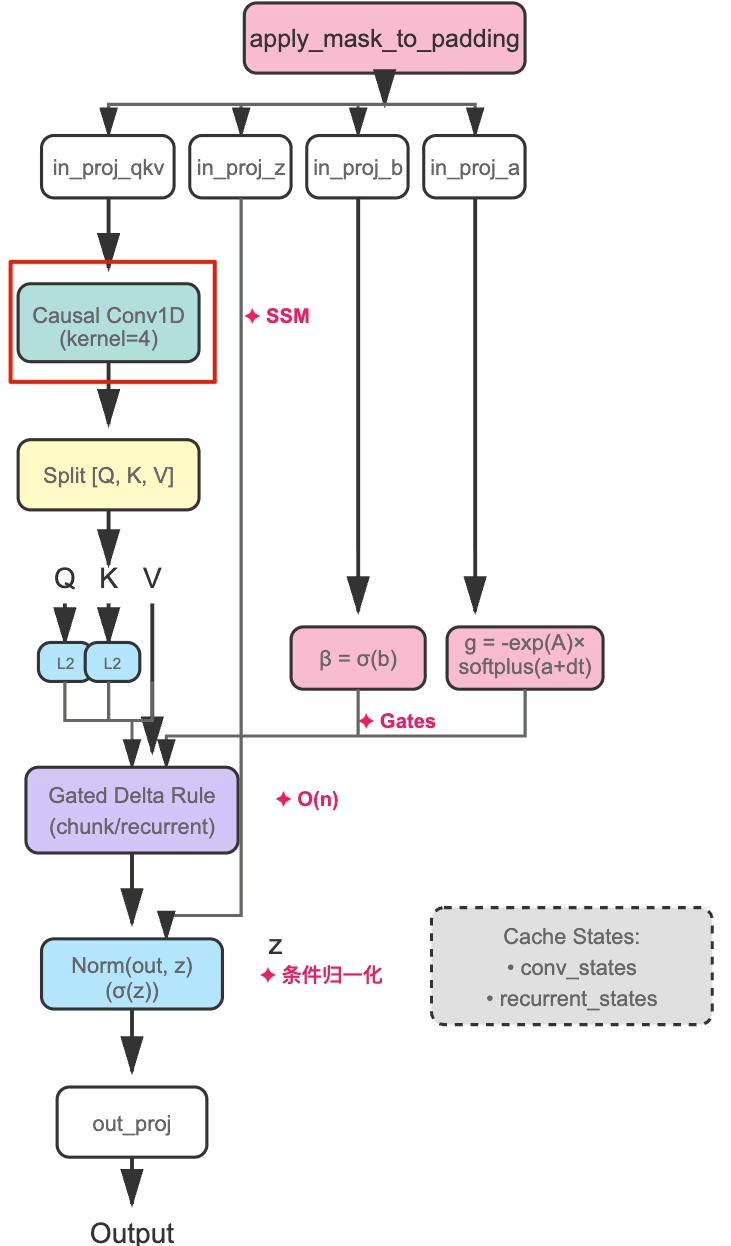
图:Gated DeltaNet 架构,红框标注了 Causal Conv1D 组件
动机
- 先验地觉得越近的 Token 越重要(从标准注意力发现的?)
- n-gram 的结构化表示,比如一个词组 “Not Bad”,在看 Bad 的时候,Not 需要特别地看一眼
Mamba:加层卷积
在 QKV 投影后添加一层 Causal Conv1D:
参数:
kernel_size=4:查看最近 4 个 tokenDepthwise:每通道独立卷积Causal padding=3:只看历史,填充
5. RMSNorm + Z-Gate
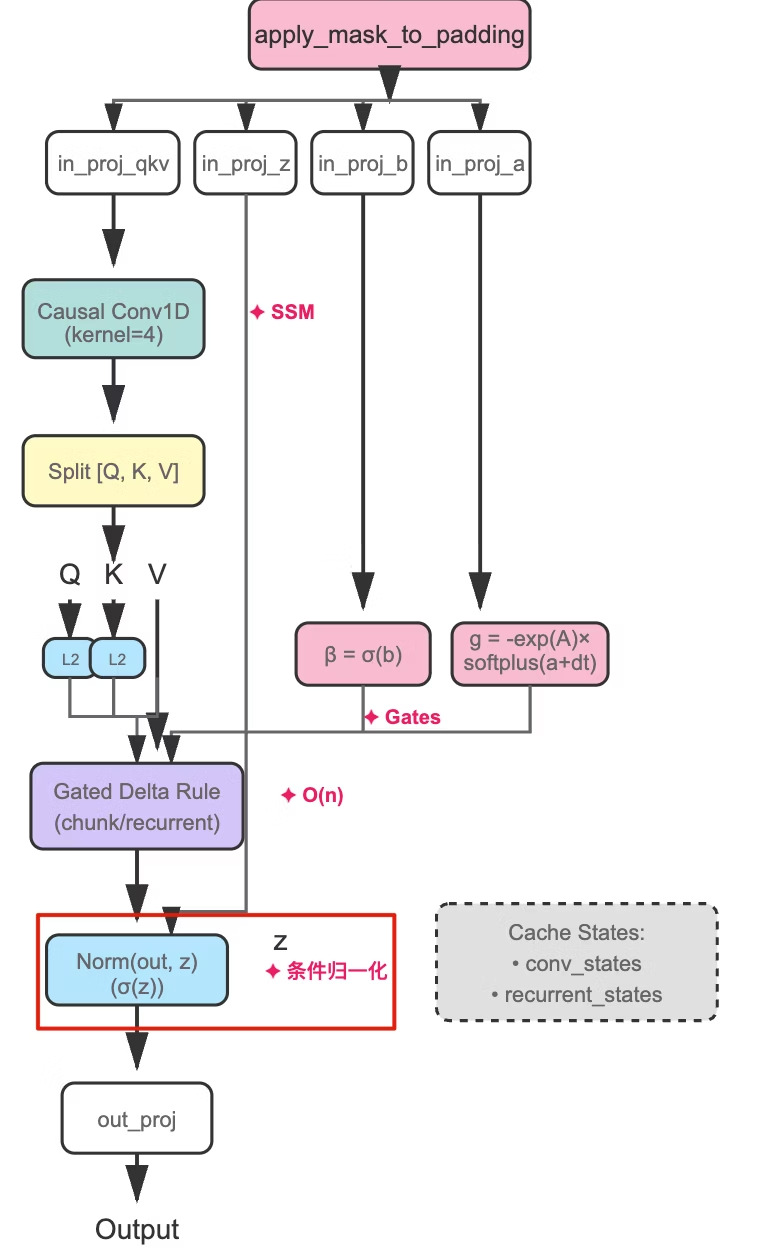
图:Gated DeltaNet 架构,红框标注了输出端的 RMSNorm 和 Z-Gate 组件
从检索到过滤
原做法:
Mamba2 改进:
RMSNorm:把输出 score 拉回到稳定的范围
为什么不用之前说的 L2 Norm?
- Q 和 K 用 L2 Norm 强制向量长度为 1
- 输出若也用 L2 Norm,会丢失 $S_t$ 累积量的强度信息
- RMSNorm 归一化整体尺度,同时保留各维度相对比例
公式对比:
Z-Gate:动态调节 + 抑制噪声
基于当前输入 $x_t$ 动态计算门控值:
- 训练的时候学习何时放大或抑制输出——恢复 Softmax 的动态调节能力
- 类似 GLU,在 Mamba2 等架构中已被验证有效
为什么要对整体进行 Norm 和 Z-Gate 而不是单独的?
如果只对 q 做优化,但 $S_t$ 里的数值已经变得很大或分布很不均匀,那么 $q^T S_t$ 的结果依然会瞬间”冲破”合理的数值区间。只能控制”要搜什么”,但不知道”搜出来的东西质量如何”。
等等,Mamba 不也是递归的吗?为什么不会梯度消失?
看到这里,你可能会有一个疑问:既然 Mamba 采用的是递归结构,那它不就是 RNN 的变种吗?RNN 不都是因为梯度消失/爆炸的问题而被淘汰的吗?为什么 Mamba 就能避开这个陷阱?
这个问题问得太好了!让我们深入挖掘一下。
RNN/LSTM 为什么会”失忆”?
回顾一下传统 RNN 的状态更新公式:
问题就出在这个 $W_h$ 上。无论你输入什么,这个权重矩阵都是固定不变的。想象一下,你在阅读一篇文章时,无论看到的是重要的定理还是无关紧要的例子,你对”记住过去”的策略都是一样的——这显然不合理。
更糟糕的是,当序列很长时,这个固定的 $W_h$ 会被连乘很多次($W_h \times W_h \times W_h \times \ldots$),结果要么指数级衰减(信息丢失),要么指数级爆炸(数值溢出)。这就是著名的梯度消失/爆炸问题。
LSTM 虽然通过门控机制缓解了这个问题,但本质上它还是在用固定的规则处理信息。
Mamba 的”变速箱”:$\Delta$ 参数
Mamba 的天才之处在于引入了 $\Delta_t$ 参数——一个随输入动态变化的”步长”。
Mamba 的离散化公式是:
这里 $\Delta_t$ 会根据当前输入 $x_t$ 实时调整。它的作用就像给模型装了一个”变速箱”:
遇到重要信息时:
- $\Delta_t$ 变得很大
- $\exp(\Delta_t A) \approx 1$
- 信息几乎无损传递,完全抵抗衰减
遇到无关信息时:
- $\Delta_t$ 变得很小
- $\exp(\Delta_t A) \approx 0$
- 模型主动”遗忘”这些噪声
这就像你在读书时,遇到重点会放慢速度仔细消化,遇到废话就快速翻过。模型不再是被动地接受固定权重的约束,而是主动学习如何调整记忆策略。
一个直观的类比
让我们用”采样频率”来类比:
| 场景 | 传统 RNN | Mamba |
|---|---|---|
| 处理密集信息 | 固定频率,容易丢失细节 | 高频采样,精细捕捉 |
| 处理无关背景 | 固定频率,浪费计算 | 低频采样,快速跳过 |
| 长序列处理 | 线性衰减,逐渐”失忆” | 动态时间尺度,智能记忆 |
对比 LSTM:谁更聪明?
| 机制 | LSTM | Mamba |
|---|---|---|
| 遗忘策略 | Forget Gate(基于隐藏状态) | $\Delta$(动态时间尺度) |
| 信息流动 | 通过门控叠加 | 通过连续时间演化 |
| 本质 | 离散的门控开关 | 连续的时间建模 |
Mamba 从控制理论的角度重新设计了序列建模。它不再是简单的”要不要记住”,而是”以什么样的时间尺度来记住”。
小结
Mamba 通过 $\Delta_t$ 参数,将”衰减”从一种”不可控的物理限制”变成了”可学习的逻辑选择”。这听起来是不是有点像 Transformer 的 Attention 权重?没错,Mamba 本质上是把”对历史的关注度”做成了一个递归的动态系统。
既保留了 RNN 的高效递归结构,又绕过了梯度消失的陷阱——这就是 Mamba 的核心创新。
但是递归怎么并行训练?这不矛盾吗?
读到这里,你可能又冒出一个问题:既然 Mamba 是递归的,那训练时不得一步一步算吗?$h_1$ 算完才能算 $h_2$,$h_2$ 算完才能算 $h_3$……这样的话,GPU 的数千个核心不都闲着了吗?训练速度岂不是慢到爆?
这个问题直击要害!确实,递归的最大问题就是串行依赖。但 Mamba 的研究者们使用了一个巧妙的算法——并行扫描(Parallel Scan)——来解决这个矛盾。
递归的困境
让我们先看看问题在哪。假设状态更新是 $ht = \bar{A}h{t-1} + \bar{B}x_t$,展开来看:
每一步都依赖前一步的结果,GPU 只能排队等待。这就像流水线上的工人,每个人都得等前一个人完成才能开工——效率极低。
并行扫描的魔法
Mamba 的解决方案是将长序列切成许多小块(Chunk),每块大约 128 个时间步。然后通过两个步骤实现并行:
第一步:块内并行
虽然每个块内部还是递归的,但可以通过数学变换(类似前缀和算法),将其转化为矩阵乘法,这样就能在 GPU 上并行计算了。
第二步:块间合并
这是最精彩的部分。我们用一个生活化的例子来理解:
想象你在组装一辆汽车:
- 块内部:可以同时组装”发动机”、”车轮”、”车门”、”座椅”
- 块之间:组装完成后,按照顺序把它们安装到车架上
在 Mamba 中,每个 Chunk 计算完后会产生两个东西:
- 状态转移矩阵 $A_{chunk}$
- 输出偏置 $b_{chunk}$
对于两个相邻的块:
将它们合并:
神奇的地方来了:这个合并操作可以递归地应用! 多个 Chunk 可以两两合并,形成一个二叉树结构。
一个具体的例子
假设有 8 个时间步,我们把它们分成 4 个 Chunk:
1 | 原始序列: [x1 x2] [x3 x4] [x5 x6] [x7 x8] |
传统串行:需要 8 步
并行扫描:只需要 $\log_2(8) = 3$ 步!
Mamba 的两面性
这种设计让 Mamba 在不同场景下展现出完全不同的性能:
| 场景 | 策略 | 优势 |
|---|---|---|
| 训练 | 并行扫描(Chunking) | 利用 GPU 并行能力,速度接近 Transformer |
| 推理 | 递归计算(RNN 模式) | 只需保存一个状态向量,内存占用极低 |
对比 Transformer:
| 指标 | Transformer | Mamba(训练) | Mamba(推理) |
|---|---|---|---|
| 训练复杂度 | $O(n^2 d)$ | $O(nd \log n)$ | - |
| 推理复杂度 | $O(n^2 d)$ | - | $O(nd)$ |
| 内存占用 | $O(n^2)$ KV Cache | $O(nd)$ | $O(d)$ 单状态 |
小结
Mamba 通过 Chunking + 并行扫描 这个”魔术”,成功解决了递归的并行化难题。它就像一个变形金刚:
- 训练时变成”并行机器”,充分利用 GPU
- 推理时变回”递归机器”,节省内存
综上
Gated DeltaNet 是基于 Mamba 架构的一次升级,比较新的创新应该只有:
- L2 Norm
- 双重门控
Linear Attention 的演进(速通版)
三种架构的详细对比
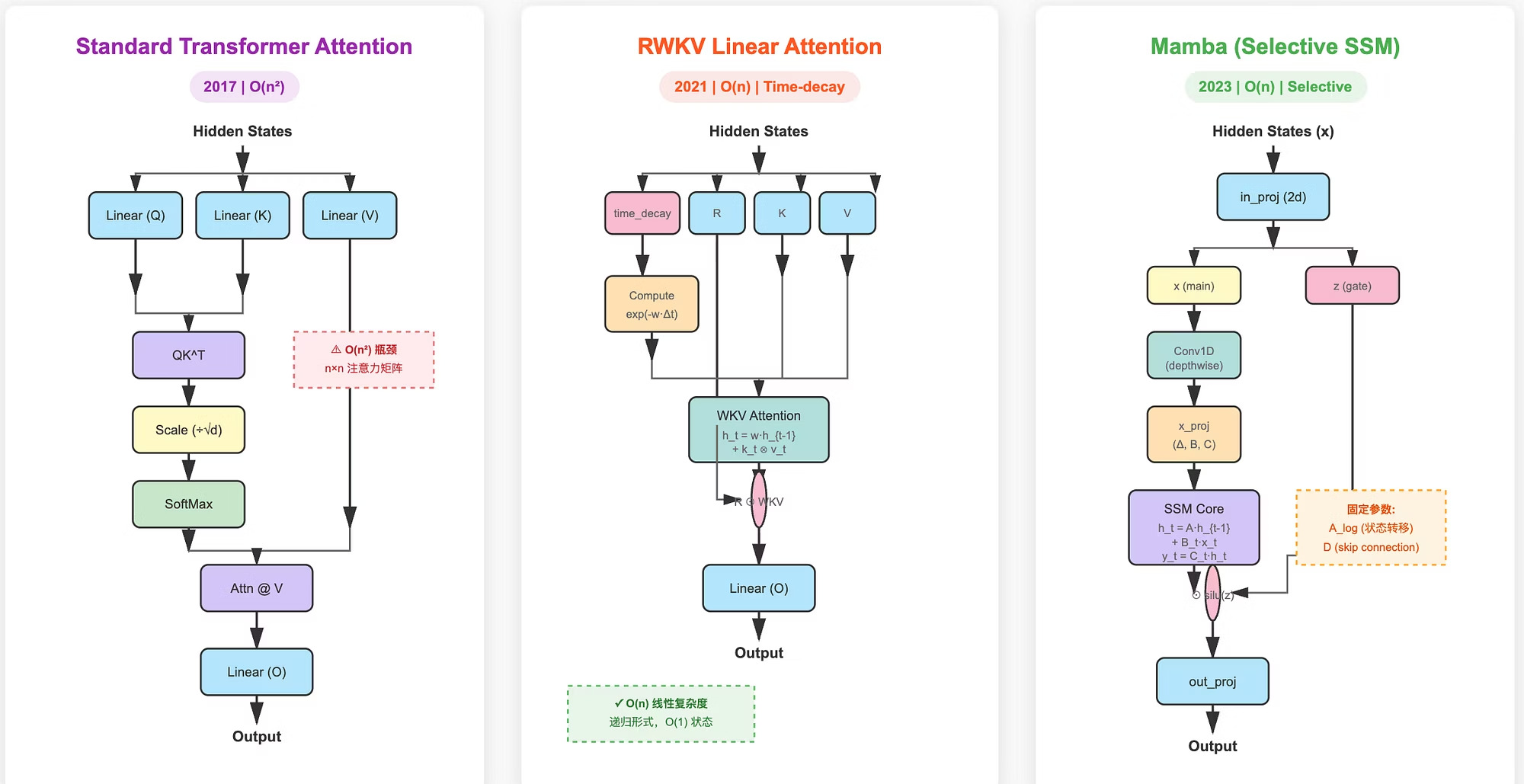
图:标准 Transformer Attention(左),RWKV Linear Attention(中),Mamba Selective SSM(右)的架构对比
演进路径
1 | 1. Transformer (2017) |
架构的变化:三种架构对比
Scaled Dot-Product Attention (标准)
传统 Transformer 架构,使用 softmax 注意力机制。
Time-decay WKV Attention (RWKV)
引入时间衰减因子,实现线性复杂度。
Matrix LSTM (xLSTM)
将经典 LSTM 现代化,使用矩阵状态表示。
结论
Qwen3.5 通过集成 Gated DeltaNet,成功在保持高性能的同时,优化了长序列任务的推理效率(特别是 >8k 的长文本)。这种混合架构标志着主流大模型开始大规模采用线性复杂度算子来应对计算瓶颈。
关键创新点:
- L2 归一化替代传统核函数
- 双重门控机制(遗忘 + 衰减)
- Causal Conv1D 增强局部感知
- RMSNorm + Z-Gate 实现动态调节
参考文献
- 标准 Attention: “Attention Is All You Need” (Vaswani et al., 2017)
- RMSNorm: “Root Mean Square Layer Normalization” (Zhang & Sennrich, 2019)
- GLU/Gating: “Gated Linear Units” (Dauphin et al., 2017)
- Linear Attention: “Transformers are RNNs” (Katharopoulos et al., 2020)
- Mamba (SSM): “Mamba: Linear-Time Sequence Modeling” (Gu & Dao, 2023)
- Qwen3.5 官方: Qwen/Qwen3-Next-80B-A3B-Instruct