本文从基础的量化开始,介绍 TurboQuant(arXiv:2504.19874)的核心设计。
量化到底在做什么
一句话讲清楚
量化就是把连续实数映射成有限个离散值,用一点误差换更小存储和更高速度。
更形式化地说,它是一个映射:
其中 $B = b \cdot d$,$b$ 是每个坐标的平均 bit 数。还需要一个反映射(反量化):
这个变换天生有损——$Q$ 不是双射,所以永远不可能完美还原原始向量。能做的,是让损失变得可控。
为什么量化在 LLM 里很重要
大模型推理有三个硬约束:
显存:可近似写成 $\text{参数个数} \times \text{每个参数的字节数}$。
- 同样 10 亿参数,FP16 约 2 GB,INT4 只需约 0.5 GB。
带宽:很多推理场景的瓶颈不在算力,而在 HBM 带宽(GPU 的”传送带”)。
- 量化后需要搬运的数据变少,传送带压力下降,速度就上去了。
KV cache:Decoder-only 模型必须把每一层的 key/value embedding 存在 cache 里。
- cache 大小随层数、注意力头数、上下文长度三重增长,是长上下文推理的核心瓶颈。
所以量化可以省显存,是否加速取决于硬件与实现。
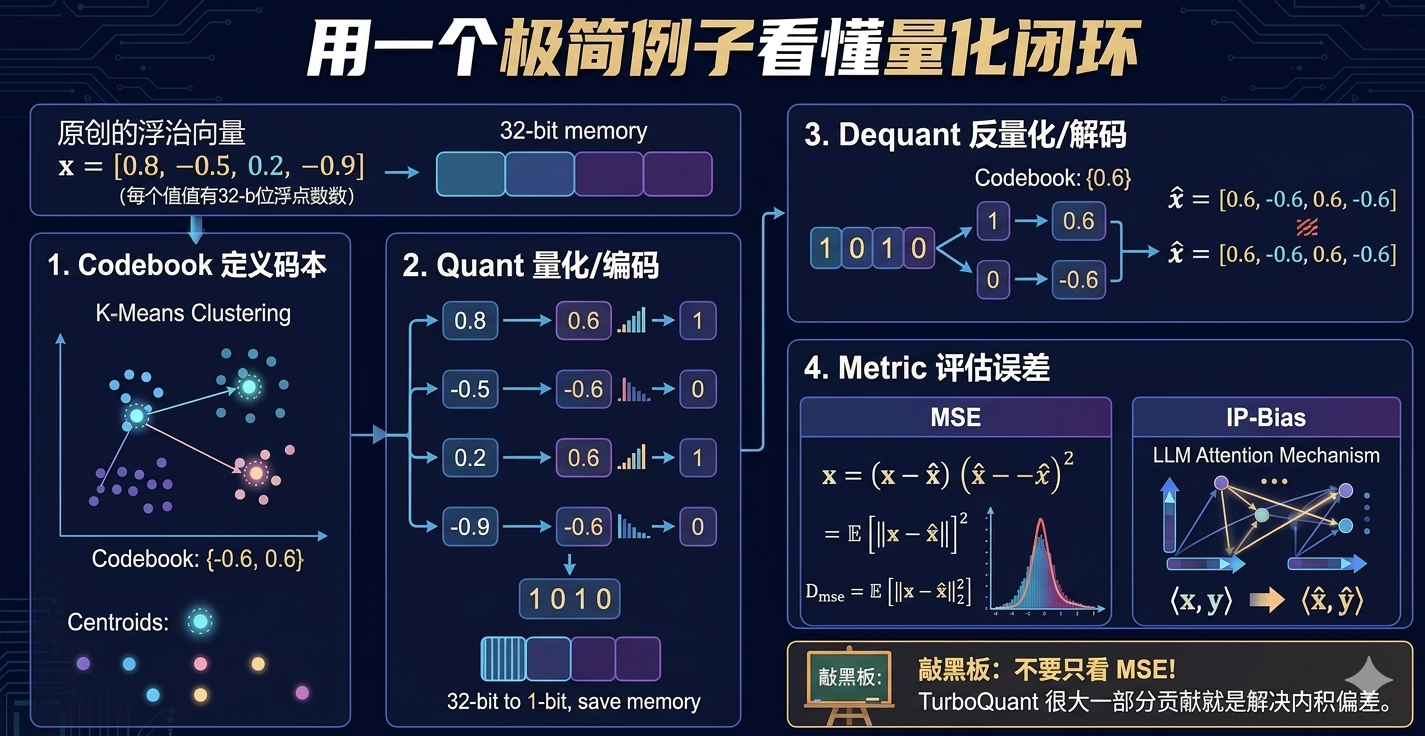
例子
假设有一个长度为 4 的向量:$x = [0.8, -0.5, 0.2, -0.9]$,每个数字原本是 32-bit 的浮点数。
为了省显存,我们决定把每个数字压缩到 1-bit。
1-bit 意味着我们只能使用 $2^1 = 2$ 种状态(0 或 1)。这就引出了量化的四个关键步骤:
1. Codebook(定义码本)
既然只有 2 种状态,我们就只能选出 2 个“代表值”来近似所有可能的数字。
这两个代表值可以人为规定,也可以用 K-Means 对数据进行聚类求中心点。
假设经过统计,得出最优的两个代表值是 {-0.6, 0.6}。这就是码本(Codebook)。
2. Quant(量化/编码)
接下来,把原向量 [0.8, -0.5, 0.2, -0.9] 中的每个数,就近映射到码本里,并记录它的索引:
0.8离0.6更近 $\to$ 选大号代表值,存为索引1-0.5离-0.6更近 $\to$ 选小号代表值,存为索引00.2离0.6更近 $\to$ 选大号代表值,存为索引1-0.9离-0.6更近 $\to$ 选小号代表值,存为索引0
最终存进显存的只有比特串:1010。
这一步,32-bit 变成了 1-bit,这就是空间被省下来的地方。
3. Dequant(反量化/解码)
当 GPU 需要拿这串数字去做矩阵乘法时,它会根据索引去查码本,把比特串 1010 还原出来。
还原出的近似值是:$\hat{x} = [0.6, -0.6, 0.6, -0.6]$。可以看到,它与原向量 x 接近,但不完全一致。
4. Metric(评估误差)
因为还原回来的值与原值不相等,误差就产生了。
怎么评估这个量化算法好不好?
最常用的指标有两个:
MSE(均方误差):算一下原值 $x$ 和近似值 $\hat{x}$ 之间差异的平方和的平均值。
即 $D_{\text{mse}} = \mathbb{E}\left[\lVert x - \hat{x}\rVert_2^2\right]$。
这是评估失真最基础的指标。
IP-RMSE / IP-Bias(内积误差):在 LLM 的注意力机制和向量检索中,真正频繁做的是点积计算。
如果还原后的点积和真实的点积 $\langle x, y \rangle$ 总是有系统性地偏高或偏低,这就是 Bias(偏差)。
注意:不要只看 MSE。
MSE 低不等于内积一定准确,TurboQuant 的重要贡献之一就是修正内积偏差。
有损 vs 无损(容易混淆的地方)
在量化的语境里,很多人会把一些概念搞混:
有损(Lossy):从
0.8变成0.6这个过程(即 Quant),误差是绝对不可逆转的。因此,量化本身天生是有损的。无损(Lossless):针对索引串
1010,如果能用类似 ZIP 压缩(如 Huffman 编码或 ANS 等信息论方法)把它压得更小,解压后依然是完美还原的1010索引串,这就叫无损压缩。
所以”无损压缩”不是说量化无损,而是指在索引编码层的无损存储压缩。
论文的动机
在长上下文大模型推理(KV Cache 压缩)和亿级向量检索场景中,传统的量化方法面临着一个不可调和的矛盾。可以把现有方法简单分为两派:
痛点 1:简单方法(如均匀量化)速度快,但精度差、空间利用率低
均匀量化直接把数据按等间距切分(就像尺子上的等距刻度)。计算极快,不需要提前分析数据分布。但这在数据分布不均匀时会带来巨大的误差。
例子:
2-bit 意味着每个坐标只能落在 $2^2 = 4$ 个代表值之一。
如果用均匀码本(等间距):
最近邻量化后:
如果用非均匀码本(码本点更贴近数据密集的区域):
量化后:
这就是均匀量化最大的缺点:真实世界的数据(如模型激活值)往往集中在某一区域(比如高斯分布的数值大多集中在 0 附近),等间距切分会把大量宝贵的编码空间(bit)浪费在几乎没有数据的边缘区域。
就像把一条路分成 16 段测车流密度,如果车都挤在市中心,你却把郊区和市中心切得一样细,这就是在浪费分辨率。
这种浪费导致了均方误差(MSE)极大,同等空间下的精度极低。
痛点 2:高级方法(如乘积量化 PQ / K-Means)精度高,但耗时且难以在线流式处理
既然均匀量化不好,那怎么找到上面的“非均匀最优码本”呢?
最经典的方法是 Lloyd-Max 算法(可以把它理解为一维数据上的连续 K-Means 聚类)。
它的核心思想是“两步交替优化”。用一个包含 4 个数字的极简数组 [1, 2, 8, 9] 来演示,假设把它量化成 $K=2$ 个代表值(1-bit):
初始化:瞎猜两个初始代表值(码本),比如 $c_1 = 3$ 和 $c_2 = 6$。
第一轮迭代:
固定代表值,更新边界(划定地盘):
计算 3 和 6 的中点边界:$t = (3 + 6) / 2 = 4.5$。这就把数据切成了两块:小于 4.5 的归左边,大于 4.5 的归右边。
所以:左阵营分到了
{1, 2},右阵营分到了{8, 9}。固定边界,更新代表值(选新代表):
计算每个阵营内部的“平均值”(均值能让该阵营内部的 MSE 最小):左边的新代表值:$c_1 = (1 + 2) / 2 = 1.5$
右边的新代表值:$c_2 = (8 + 9) / 2 = 8.5$
第二轮迭代:
- 更新边界:计算新中点 $t = (1.5 + 8.5) / 2 = 5$。
更新代表值:小于 5 的还是
{1, 2},大于 5 的还是{8, 9}。阵营没有变化,新的代表值依然是
1.5和8.5。由于没有变化,所以算法收敛,到此结束!
最终,找到了完美贴合数据分布的最优码本 {1.5, 8.5}。
通过这种聚类找码本的方法,空间利用率极高,MSE 极低。
但这带来一个致命缺陷:需要在线聚类拟合(Online Fitting)!
每次来新数据,必须先攒齐一大批数据,跑一遍耗时的迭代算法才能得到最优码本。
在 KV Cache 这种 Token 逐字输出的场景下,根本等不起聚类的时间;在向量数据库中,这也意味着极其漫长的数据建索引时间。
痛点 3:指标错位,MSE 低不代表“内积”一定准
几乎所有的传统量化方法都在死磕如何降低 MSE(重建误差)。
但是在 LLM 的注意力机制(Attention)和向量检索中,底层频繁计算的其实是两个向量的内积(Inner Product),而不是简单衡量它们长得有多像。
还是刚刚的 2-bit
假设现在来了一个查询向量(Query)$y$:
我们先算一下 $y$ 和刚才那个真实原始向量 $x$ 的点积:
真实内积 $\langle y, x \rangle = -0.782$
在实际的量化检索中,我们拿不到真实的 $x$,只能用量化后的 $\hat{x}$ 来算内积,结果会怎样?
- $y$ 与均匀量化结果 $\hat{x}_{\text{uniform}}$ 的内积 = -0.700 (内积绝对误差 $\Delta = 0.082$)
- $y$ 与非均匀量化结果 $\hat{x}_{\text{non-uniform}}$ 的内积 = -0.710 (内积绝对误差 $\Delta = 0.072$)
尽管聚类优化把 MSE 降低了 41%,但内积误差只从 0.082 降到 0.072,改善幅度有限。
这种因为有损压缩引发的内积计算误差,往往不是正负抵消的随机噪声,而是会引入系统性的内积偏差(Bias)
如果内积估计有系统偏差,在向量检索的 Top-K 排序或 Attention 打分中就会出现持续的定向偏移。
TurboQuant 的思路
论文尝试用一套方法同时处理上述三个痛点:
- 精度:要达到高级聚类算法的极限压缩精度(逼近信息论的理论下界);
- 速度:接近均匀量化的在线效率,免去在线拟合(Zero online fitting),支持数据的即写即查;
- 无偏:通过巧妙的残差补偿算法,彻底消除内积计算的系统性偏差。
关键洞察:先旋转,让分布变得可预测
TurboQuant 的第一步是在量化前做一次随机正交旋转。
核心直觉是:如果原始分布形态复杂(长尾、极值),在线切分和聚类会很慢;那能否先通过变换,把未知分布转成一种稳定、可建模的分布?
只要分布稳定,就可以离线(Offline)预计算码本,数据到达后直接查表(Look-up),从而去掉耗时的在线拟合。
发现:对于任意高维向量,乘上随机正交矩阵后,其坐标分布会收敛到固定形式,即(缩放/平移后的)Beta 分布。
TurboQuant_mse:例子
假设有一个极度“偏科”(长尾极值)的输入向量:
所有的能量都集中在第一维,第二维是 0。
直接拿它去量化,码本很容易“跑偏”。对它进行 1-bit(即 2 个代表值)的量化。
Step 1:准备旋转矩阵 $R$
系统预先生成好了一个随机正交矩阵 $R$。在 2D 里,我们可以假设它恰好是一个逆时针旋转 45 度的矩阵:
Step 2:旋转打散偏置($y = Rx$)
对 $x$ 乘以旋转矩阵 $R$:
可以看到,原本偏向单一维度的 [1.0, 0.0] 被打散成 [0.707, 0.707]。
Step 3:查表量化($\hat{y}$)
既然现在的分布变成了极其标准的稳定分布,根据事先针对 Beta 分布离线算好的 1-bit 最优码本,假设算出来是 {-0.6, 0.6}。
- $y_1 = 0.707$ 离 $0.6$ 更近 $\to$ 映射为 $0.6$
- $y_2 = 0.707$ 离 $0.6$ 更近 $\to$ 映射为 $0.6$
所以中间向量就变成了 $\hat{y} = [0.6,\ 0.6]$(存进显存的只有比特串,即索引 [1, 1])。
Step 4:反旋转重建($\hat{x} = R^\top \hat{y}$)
当矩阵乘法需要用到原始向量时,GPU 根据索引查出 [0.6, 0.6],再乘以反向旋转矩阵 $R^\top$ 进行恢复:
整个过程很快,旋转矩阵和码表都可以预先准备好,查表的复杂度是 O(1),量化的时候做一次矩阵乘法,重建的时候也是做一次矩阵乘法。
再看 TurboQuant_mse 的官方步骤会更直接:
- 生成随机正交矩阵 $R \in \mathbb{R}^{d \times d}$(对高斯矩阵做 QR 分解)。
- 旋转:$y = Rx$。
查表量化:对每维做标量量化 $yi \to c{k^}$,其中 $k^ = \arg\min_k |y_i - c_k|$。
这里的码本 $C$ 就是针对 Beta 分布预先离线计算好的最优码本。
- 获取存储形式:得到 $\hat{y} = [c{k^*(1)}, \dots, c{k^*(d)}]$。
- 反旋转(重建):$\hat{x} = R^\top \hat{y}$。
再回过头来看其他收益
打散方向性偏置:原始向量某些维度可能异常值很大,某些维度很平,这会让逐维量化不稳定。旋转可以把这种偏置分散到各维度。
让逐维独立量化更合理:论文推导表明,随机旋转后各维度不仅分布稳定,而且近似相互独立。
正交矩阵满足 $R^\top R = I$,因此 $|x|_2 = |Rx|_2$,向量长度和内积结构都保持不变。
更重要的一点是:旋转保持了优化目标不变——
在旋转域最小化 MSE,完全等价于在原始域最小化 MSE。
Q:针对 Beta 分布离线计算的最优码本,是否意味着所有数据都可共用一个固定码本?
A:是的。
这正是 TurboQuant 摆脱“在线拟合”的关键。
无论输入是文本 embedding 还是视觉特征,只要乘上随机旋转矩阵 $R$,其坐标分布就会落到固定的 Beta 形式。
所以只需准备这一个全局码本。这个全局码本只和两个参数有关:向量的维度 $d$ 和 目标压缩位数 $b$,完全与输入数据无关。
唯一需要注意的是,由于 Beta 分布的推导前提是向量在单位球面上(即长度为 1,$|x|_2 = 1$)。
所以在工程实现中,我们只需要把真实向量的“长度(L2 Norm)”单独抽出来存成一个 16-bit 浮点数,然后把剩下的方向向量(即除以长度归一化后的向量)交给这个固定的码本去查表量化,最后反量化重建时再把长度乘回去即可。
通过这种“前处理 + 静态全局码表”的设计,论文 Theorem 1 证明:对任意 $|x|_2 = 1$ 的向量,均方误差存在明确上界:
| $b$ | $D_{\text{mse}}$ 上界 |
|---|---|
| 1 | ≈ 0.36 |
| 2 | ≈ 0.117 |
| 3 | ≈ 0.03 |
| 4 | ≈ 0.009 |
这个上界已经非常接近信息论下界,两者仅差约 2.7 倍常数因子。
也就是说,TurboQuant_mse 在 MSE 方向已经接近理论极限。
到这里,通过前处理预旋转 + 全局固定离线码本查表,TurboQuant 已经解决前两个痛点:既保留免拟合的在线效率,也接近高级聚类方法的压缩精度。
TurboQuant_prod:用残差补偿修正内积偏差
论文提出两阶段方案来解决第三个痛点:指标错位,内积偏差。
假设真实向量是 $x = [0.8, 0.5]$。
有个查询向量 $y = [1.0, 0.0]$ 算内积,真实内积是 $\langle y, x \rangle = 0.8 \times 1.0 + 0.5 \times 0.0 = 0.8$。
假设用刚才讲的 TurboQuantmse 算法,把 $x$ 量化成了 $\hat{x}{\text{mse}} = [0.7, 0.6]$。
例子
约定把随机矩阵 $S$ 取成一个便于手算的 45 度旋转矩阵,并约定 $\operatorname{sign}(0)=+1$。
计算“漏掉的误差”
残差 $r$:
残差长度 $\gamma$:
压缩误差方向(QJL)
不能直接存残差 $r$,因为那太占空间了。
于是改用 QJL,只存它的“方向”。
随机旋转:把残差 $r$ 乘以矩阵 $S$。
这里取
则
只取符号:不再存具体数值,只看正负。
- $0.1414$ 是正的,对应
+1 - $0$ 在这个例子里按
+1处理
所以得到
- $0.1414$ 是正的,对应
现在,原本复杂的残差向量就被压成了两个 1-bit 符号。
还原“补丁向量”
当你需要用它修正内积时,算法会根据 $q$ 和前面存下来的长度 $\gamma$ 还原出一个补丁:
先乘回 $S^\top$:
再乘上缩放系数:
所以补丁向量约为
把补丁加回去
最终重建向量变成:
如果查询向量仍取 $y = [1.0, 0.0]$,那么新的内积就是:
真实内积是 0.8,而如果只用 MSE 量化,内积就是 $0.7 \times 1.0 + 0.6 \times 0.0 = 0.7$。
- 阶段 A(大头):用 MSE 量化保证尽量靠近真实向量;
- 阶段 B(修正):通常带有系统方向偏差,因此先计算残差,再用极小代价(1-bit)提取偏差方向,修复偏差。
工程落地:如何选 bit-width
核心框架
bit-width 选择本质是一个有约束的优化问题:
Cost 包含显存、时延、吞吐;Quality 包含任务分数、召回率、内积误差、生成质量。
最低 bit 不是最优方案,达标集合里成本最低才是。
先定三类门槛
上线前先写死:
- 质量门槛:任务分数下降不超过 N%,或检索 Hit@k 不低于阈值
- 性能门槛:P95 时延下降至少 M%,或在时延持平前提下降低显存
- 稳定性门槛:长上下文任务不能出现系统性退化
没有门槛,就没办法做理性比较。
论文给出的关键数据点
来自 KV cache 量化实验:
- 3.5 bit/channel:可实现质量中性(quality neutrality)
- 2.5 bit/channel:只有轻微质量退化(marginal degradation)
这两个数据点是论文的核心工程结论,可以直接作为初始实验的基准配置。
一个具体例子:KV Cache 在 prefill 和 decode 里怎么量化
prefill 阶段:写入多,读取少
假设用户一次性输入了 1024 个 prompt tokens。
prefill 的特点是:这 1024 个 token 的 K/V 要批量生成并写入 cache,但它们在这一轮里主要是“刚算出来就立刻参与注意力”,不会像 decode 那样被反复从历史 cache 中读取。
工程上比较常见的做法是:
- 模型先正常算出这一批 token 的
K和V,这时它们还在BF16/FP16 - 当前层 attention 直接消费这批高精度 K/V,完成本轮 prefill 计算
- 等本轮该写 cache 时,再对每个 token、每个 head 的 K/V 做 TurboQuant 压缩
- 压缩后的 bit-packed 结果写进持久化 KV cache,供后面的 decode 使用
这里的关键点是:prefill 阶段量化主要发生在“写 cache”这一步。
拿其中某一层、某一个 head、某一个 token 的 key/value 向量举例。原始向量长度是 128:
用 TurboQuant_mse 时,这个 token 的 key/value 向量大致会经历下面几步:
- 先取 L2 norm:$s = |k|_2$
- 做归一化:$u = k / s$
- 乘随机正交矩阵:$y = Ru$
- 对
y的每个坐标查离线码本,得到 3-bit 索引 - 把
128个 3-bit 索引打包成紧凑 bitstream - 单独存下
s
这时候,prefill 的收益主要有两个:
- 省显存:
1024个 prompt tokens 如果都写成压缩 cache,后续 decode 的历史负担会小很多 - 减少后续带宽:虽然 prefill 当下不一定明显变快,但后面每一步 decode 都要反复读取这批历史 KV
但要注意,prefill 本身不一定因为 KV 量化就显著加速。
因为 prefill 往往更像一个大 batch 的矩阵计算,瓶颈常常在 GEMM,而不是在读历史 cache。
它更直接的收益是把“后面要背着走的包袱”先减掉。
decode 阶段:写入少,但每步都要读取历史 cache
decode 的情况完全不一样。
假设 prompt 已经是 1024 个 tokens,现在模型开始一个一个往后生成。
当生成第 1025 个 token 时,会发生两件事:
- 当前 token 会新产生一份 K/V,并立刻追加到 cache 末尾
- 当前 token 的 query 要和前面
1024个 token 的所有 key 做注意力,再用所有 value 做加权求和
也就是说,decode 每走一步,都要把“历史上所有 token 的 KV cache”重新读出来一遍。
到了第 2048 个 token,这个读取量会比刚开始大很多。
所以 decode 更像是带宽受限的问题,而不是纯算力问题。
这正是 KV cache 量化最容易见到真实加速的地方。
对某一层来说:
- 不压缩时,读 $1024$ 个历史 tokens 的 KV,需要约 $1024 \times 4\,\mathrm{KB} = 4\,\mathrm{MB}$
- 压缩后,读同样 $1024$ 个历史 tokens,只需要约 $1024 \times 672\,\mathrm{B} \approx 672\,\mathrm{KB}$
读流量一下子从 4 MB 降到不到 0.7 MB。
如果 decode 的瓶颈本来就在 HBM 带宽,这种下降就很可能直接转成时延收益。
decode 阶段到底怎么“用”这些压缩后的 KV
读压缩 cache 时,工程上一般有两条路:
第一条路:先反量化,再算 attention。
流程是:
- 从 HBM 读出 bit-packed 的 key/value
- unpack 出索引
- 按码本查表,恢复旋转域里的近似向量 $\hat{y}$
- 乘回 $R^\top$,再乘 norm,得到近似的 $\hat{k}, \hat{v}$
- 用这些近似值去做标准 attention
这条路实现最直接,但有个问题:如果先把整段历史 cache 全部恢复成 FP16 再送去 attention,中间会产生额外访存,容易抵消前面节省的带宽。
第二条路:把反量化融合进 attention kernel。
更实用的实现通常是:
- 读压缩 bitstream
- 在 kernel 内部边 unpack、边查表、边做缩放
- 立刻和当前 query 做点积,或者立刻参与 value 的加权累加
这样就不会在显存里额外 materialize 一份完整的 FP16 KV cache。
很多 KV cache 量化实现能否真正加速,差别往往在这里:不仅要能压缩,还要避免先解压成大块中间张量再计算。
为什么 prefill 和 decode 的优化重点不同
把前面的流程压缩成一句话:
- prefill 更像“批量生产 + 一次性写库”,重点是低开销写入压缩 cache
- decode 更像“每步反复读取历史”,重点是低带宽读取和融合式反量化
所以在工程上,大家通常会看到这样的现象:
prefill的主要收益是显存下降,速度提升未必明显decode的主要收益是带宽压力下降,因此更容易带来实际吞吐提升
总结来说,KV cache 量化在 prefill 中更偏向“降低存储负担”,在 decode 中更偏向“换取时延与吞吐收益”。
放到 TurboQuant 里,这套流程有什么特别之处
TurboQuant 比较适合这个场景,不是因为它只追求压缩率,而是因为它有两个很工程化的性质:
零在线拟合:不会像 PQ / K-Means 那样,来了新 token 还得先聚类再编码。
token 一算出来就能立即量化写 cache。
码本固定、查表简单:旋转后坐标分布稳定,码本可以离线预计算。
在线阶段只做旋转、查表和 bit packing。
这两点对 decode 很关键。
因为 decode 是一个 token 一个 token 往前走的流式过程,任何需要“攒一批数据再拟合”的方案,到了这里都会非常难用。
参考文献
- TurboQuant: “TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate” (Zandieh et al., 2025) — arXiv:2504.19874
- Lloyd-Max: “Least squares quantization in PCM” (Lloyd, 1982); “Quantizing for minimum distortion” (Max, 1960)
- QJL: “Quantized Johnson-Lindenstrauss” (arXiv:2411.10355)
- Shannon Source Coding: Shannon, C.E. (1948). “A Mathematical Theory of Communication”
- KV Cache 量化: “KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache” (Liu et al., 2024)