EAGLE-3 的自回归草稿器卡在了“速度”和“质量”的对立里:想让草稿更准,就得加深模型;模型越深,串行生成的代价越大。DFlash 的回答很直接:用块扩散模型替换自回归草稿器,单次前向传播并行生成整个 block,让草稿成本与投机长度彻底脱钩。相比 EAGLE-3,加速约 2.5×,平均接受长度提升约 2.2×。
前置知识
- 投机解码:LLM的推理加速-投机解码
- EAGLE 系列:LLM的推理加速-EAGLE三部曲
EAGLE 的天花板
回顾 EAGLE-3:Draft Model 是 1 层 Decoder,自回归地逐个生成草稿 token。投机长度为 \(\gamma\) 时,草稿阶段的总耗时是:
\[T_{\text{draft}}^{\text{AR}} = \gamma \cdot t_{\text{step}}\]
但这带来了一个矛盾:
- 想让草稿更准(提高平均接受长度)→ 需要加深 Draft Model,\(t_{\text{step}}\) 变大
- 想让草稿更快 → 需要减小 \(t_{\text{step}}\),只能用更浅的模型
两个目标天然对立,在自回归框架内无法同时满足。EAGLE-3 实测的平均接受长度(AAL)在 Qwen3-8B 上约为 3.4,继续扩大训练数据或加深模型,收益都趋于饱和。
如果草稿生成不再是串行的呢?
把 \(\gamma\) 个 token 一次性并行生成出来,草稿成本就变成:
\[T_{\text{draft}}^{\text{parallel}} = t_{\text{parallel}}\]
无论 \(\gamma\) 取多大,耗时都是一次前向传播。这样就可以用更深的模型(提升质量),而不必担心延迟随 \(\gamma\) 线性增长。
这就是 DFlash 的出发点。接下来的问题是:什么模型能在单次前向传播中并行生成多个 token?
扩散语言模型
语言扩散模型提供了答案。图像扩散(DDPM)的核心思路是从噪声出发多步去噪,迁移到语言上,“噪声”变成“被 Mask 的 token”,“去噪”变成“预测被 Mask 的位置”。关键在于,每步都可以并行预测所有被 Mask 的位置,不受自回归串行限制。
LLaDA:从 Mask 出发的扩散语言模型
LLaDA(2502.09992) 是一个从头预训练的扩散语言模型,是理解 DFlash 的基础。
训练
加噪:一次采样,不是 T 步链
标准图像扩散(DDPM)需要走完整的 T 步马尔科夫加噪链(通常
T=1000)。LLaDA
的做法更简单:对每条训练样本,只采样一个随机时间步
\(t \sim \text{Uniform}(0,
1)\),然后一次性按比例 \(t\) 把
token 替换为 [M],就得到了训练输入。
本质上,LLaDA 把“扩散”简化成了“随机 mask”,时间步 \(t\) 是一个连续值,代表 mask 的比例,没有离散的多步链。
以句子 The cat sat on the mat 为例,假设采样到 \(t = 0.5\):
1 | 原句: The cat sat on the mat |
每条样本独立采样 \(t\),因此模型会见过各种各样的 mask 程度:从 \(t \approx 0\)(几乎不 mask,相当于做完形填空)到 \(t \approx 1\)(几乎全 mask,相当于从头生成)。
为什么不像 BERT 固定 15%?
BERT 的 15% 是经验值,只让模型学会“在大量上下文下猜少数词”。LLaDA 的随机比例让模型同时学会两件事:\(t\) 小时,模型练习精细的局部填补;\(t\) 大时,模型练习在上下文很少时凭借全局语义生成。推理阶段的多步去噪正好会用到这两种能力:前几步 mask 比例大,后几步 mask 比例小,模型要覆盖整个区间。
预测与 Loss
将加噪序列输入模型,一次前向传播同时预测所有
[M] 位置的原始 token。因为没有因果 mask,每个
[M] 都能看到序列中所有未被 mask 的
token(双向注意力)。
训练 loss 只在被 mask 的位置计算交叉熵:
\[\mathcal{L}(\theta) = -\mathbb{E}_{t,\, x_t} \left[ \frac{1}{L} \sum_{i:\, x_t^i = \text{M}} \log p_\theta(x_0^i \mid x_t) \right]\]
上例中,loss 只由位置 1(The)、位置 3(sat)、位置 6(mat)贡献;位置 2、4、5 不参与。
推理
推理时需要事先确定输出长度 \(L\),从一条全 Mask 序列出发,经过 \(T\) 步去噪逐步恢复。
以生成 6 个 token(on the mat . It was)为例,共 \(T = 3\) 步:
Step 1(\(t=1\),全 Mask):
1 | 输入: [M] [M] [M] [M] [M] [M] |
当前步要解锁 \(\lfloor L \cdot (1 - s/T) \rfloor = \lfloor 6 \times (2/3) \rfloor = 4\) 个 token,保留置信度最高的 4 个:
1 | 输出: on the mat . [M] [M] |
Step 2(\(t=0.67\)):
1 | 输入: on the mat . [M] [M] |
当前步要解锁 \(\lfloor 6 \times (1/3)
\rfloor = 2\) 个,但只剩 2 个 [M],保留置信度高的 1
个:
1 | 输出: on the mat . [M] was |
Step 3(\(t=0.33\)):
1 | 输入: on the mat . [M] was |
最后一步,全部接受:
1 | 最终: on the mat . It was |
置信度策略是推理时的超参,不是训练出来的
每一步要解锁多少个 token,由公式 \(n_{\text{unmask}} = \lfloor L(1 - s/T) \rfloor\) 决定。它会随时间步 \(s\) 动态变化,越到后期解锁得越少,也越谨慎。模型输出的 softmax 概率直接作为置信度,阈值由这个公式隐式确定,不需要额外训练任何参数。
这和训练过程是对得上的:训练时模型见过各种 mask 比例,从 \(t\approx 1\) 的“几乎全 mask”到 \(t\approx 0\) 的“几乎不 mask”都有;推理的每一步,恰好对应训练时的某个 \(t\) 值。模型在高 mask 比例下学会“大胆猜”,在低 mask 比例下学会“精细填”,两种能力一起支撑了多步去噪。
论文实验也证实,低置信度重 Mask 策略显著优于随机重 Mask(例如在 GSM8K 上 70.0 vs 21.3)。

在 2.3T token 上预训练后,LLaDA 8B 在 MMLU(65.5)、GSM8K(78.3)、HumanEval(59.8)上与同规模自回归模型相当,部分任务超越。
关键特性:每一步都是一次前向传播处理整个序列,所有
[M]
并行预测。代价也很明确:需要事先确定输出长度,而且要走多步迭代(通常
\(T = 10 \sim 20\) 步)。
块扩散:把自回归和扩散融合起来
纯扩散语言模型有一个实际问题:生成时需要提前确定输出长度,不如自回归模型灵活。而且其生成质量(尤其是长序列)通常弱于自回归模型。
Block Diffusion(BD3-LM,2503.09573) 提出了一种折中方案:块间自回归,块内扩散。
核心思路
将序列划分为 \(B\) 个 block,每个 block 含 \(L'\) 个 token:
- 块间:自回归——第 \(b\) 个 block 以前面所有干净 block 为条件,按顺序逐 block 生成
- 块内:扩散——每个 block 内部并行预测所有 \(L'\) 个 token,不受位置顺序限制
以 12 个 token 分成 3 个 block(每块 4 个)为例:
1 | Block 1:the quick brown fox |
训练
Attention Mask 的精确设计
块扩散的核心在于一套三层组合的 Attention Mask,同时编码了「块内双向」和「块间因果」两种约束。
BD3-LM 把序列中的 token 分为两类:干净 token(前面已完成的 block \(x^{<b}\))和加噪 token(当前 block \(x_t^b\))。针对这两类 token 之间的交互,定义了三个子 mask:
- \(M_{\text{BD}}\)(Block-Diagonal):加噪 token 之间的自注意力,只能看到同一 block 内的其他加噪 token
- \(M_{\text{OBC}}\)(Offset Block-Causal):加噪 token 对干净 token 的跨块注意力,只能看到前面所有干净 block
- \(M_{\text{BC}}\)(Block-Causal):干净 token 的注意力,只能看到同 block 内以及前面 block 的 token(标准因果)
完整 Attention Mask 的结构:
\[M_{\text{full}} = \begin{bmatrix} M_{\text{BD}} & M_{\text{OBC}} \\ 0 & M_{\text{BC}} \end{bmatrix}\]
用矩阵示意(3 个 block,每块 3 个 token,加噪 block = Block 2,干净 block = Block 1 + Block 3 已完成部分):
1 | B1t1 B1t2 B1t3 | B2t1 B2t2 B2t3 | B3t1 B3t2 B3t3 |
关键点:加噪 block(Block 2)的每个 token 都能看到所有干净的前置 block(Block 1),以及本 block 内的全部加噪 token(双向),但看不到后面的 block。这让块内去噪时能充分利用前文语义,同时块内各位置并行预测。
训练时每个 block 独立采样噪声比例
训练一条样本时,每个 block 独立采样自己的噪声时间步 \(t_b \sim \text{Uniform}(0, 1)\),互不干扰。这样一次前向传播就同时训练了所有 block 的去噪能力,效率比逐 block 分开训练高约 20–25%。
以 3 个 block 的样本为例:
1 | Block 1:t₁ = 0.8 → [M] [M] brown [M] (80% 被 mask) |
模型在一次前向传播中,同时以各 block 的干净前置内容为条件,预测三个 block 中被 mask 的位置,loss 在所有被 mask 的位置上累加:
\[\mathcal{L} = \sum_{b=1}^{B} \mathbb{E}_{t_b,\, x_{t_b}^b} \left[ \sum_{i:\, x_{t_b,i}^b = \text{M}} \log p_\theta(x_0^{b,i} \mid x_{t_b}^b,\, x^{<b}) \right]\]
注意这里 \(x^{<b}\) 是该 block 前面所有 block 的干净版本。训练时模型始终以干净上下文为条件预测当前 block,这和推理时的行为完全一致。
噪声调度:按 block 大小优化裁剪范围
BD3-LM 的另一个细节是,mask 比例并非完全均匀采样,而是对每种 block 大小 \(L'\) 单独优化一个“裁剪窗口”\([\beta, \omega]\),在这个区间内均匀采样 \(t\),区间外设为 0 或 1。这样可以降低梯度方差,稳定训练。实验发现:
- \(L' = 4\):使用 \([0, 1]\)(不裁剪)
- \(L' = 16\):使用 \([0.3, 0.8]\)
- \(L' = 128\):使用 \([0.5, 1.0]\)(倾向于高噪声)
推理:KV Cache 跨 block 传递
推理时逐 block 生成,每个 block 内部走多步扩散去噪,完成后把该 block 的 KV Cache 缓存起来,直接传给下一个 block,避免对前置内容重复计算注意力。
\[x_{\text{noisy}},\; K^b,\; V^b \;\leftarrow\; x_\theta(x_{t}^b,\; K^{1:b-1},\; V^{1:b-1})\]
以生成 jumps over the lazy dog sits down here(2 个
block,每块 4 token)为例:
生成 Block 1(无前置上下文):
1 | 初始: [M] [M] [M] [M] |
生成 Block 2(以 Block 1 的 KV Cache 为条件):
1 | K¹, V¹ 已缓存(来自 Block 1 的 jumps over the lazy) |
最终输出:jumps over the lazy dog sits down here
“解锁后不再重新 mask”(Carry-Over
Unmasking)是一个重要约束:块内一旦某个 token
被解锁,后续去噪步骤就不会把它重新变回 [M]。这和 LLaDA
的“低置信度重 Mask”策略不同。LLaDA 是全序列扩散,需要通过重 Mask
迭代修正;BD3-LM 因为有块间因果依赖,一旦某个 block
完成,就必须保持稳定,才能作为下一个 block 的可靠上下文。

与纯扩散的对比
纯扩散模型(如 LLaDA)从全 mask 出发,没有任何上下文,必须多步迭代(T = 10~20 步)才能逐步收敛。块扩散在生成质量和灵活性上比纯扩散更好,但块内仍然是扩散过程,需要若干步去噪。
这里先澄清一点:块扩散本身并不等于单步生成。它只是把扩散的范围从全序列缩小到了一个 block,具体还要走几步,取决于实现。DFlash 借用了这套架构,但它为什么能做到单步,要到下一节才能说清楚。
关键权衡
- \(L'=1\):退化为纯自回归(逐 token 生成,无并行)
- \(L'=L\):退化为纯扩散(全序列一次生成,无法动态延伸长度)
- 中间值(\(L'=4\sim 16\)):块内并行提速,块间 KV Cache 保持灵活性和生成质量
BD3-LM 在 LM1B 上的困惑度:\(L'=4\) 达到 28.23,\(L'=16\) 为 30.60,均优于同类扩散模型(MDLM 31.78),且不需要提前固定序列长度。
DFlash:把块扩散变成投机解码的草稿器
回到最初的问题:既然扩散模型能一次并行生成 \(\gamma\) 个 token,为什么 DFlash 不直接用 LLaDA 这样的纯扩散模型,或者直接照搬块扩散?
问题出在“多步”上。LLaDA 需要 \(T = 10~20\) 步去噪,每一步都是一次完整前向传播,草稿总成本是 \(T \times t_{\text{full}}\),并不比 EAGLE 的串行生成便宜。块扩散同样有多步去噪,直接拿来用也解决不了这个问题。
关键区别在条件强度。LLaDA 从全 mask 开始,几乎是在“凭空生成”,所以只能靠多轮迭代一点点收敛。投机解码却完全不是这个场景:每次生成草稿时,前缀(prompt + 已生成内容)已经给全了,当前 block 的不确定性小得多,一步预测往往就够。这和块扩散里“前置 block 已完成,并作为当前 block 的条件”其实是同一类结构。
所以 DFlash 只保留块扩散最有用的部分:attention 结构和“mask 一个 block、单步并行补全”的生成范式。块内双向注意力负责并行预测多个位置,块间因果结构负责和投机解码的左到右验证对齐。多轮扩散里的反复加噪、去噪和迭代调度被拿掉了,但推理时仍然会用 mask token 作为当前 block 的占位符。
因此,DFlash 的 Draft Model 虽然沿用了块扩散的 attention 架构,但训练目标是直接的 token 级交叉熵,推理时只做一次 masked block prediction,而不是 \(T\) 步迭代去噪。它本质上是一个借用了块扩散 attention mask 的并行预测器,草稿成本真正压缩到 \(1 \times t_{\text{draft}}\),与 \(\gamma\) 基本脱钩。

架构设计
DFlash 的 Draft Model 是一个 5 层 Transformer(Qwen3-Coder-30B 使用 8 层),与 Target Model 共享 token embedding 和 LM Head。
初始化上,它也不是一个完全独立的小语言模型。论文训练细节明确写到:token embedding 和 LM Head 直接与 Target Model 共享,并在训练中保持冻结,只更新 Draft Transformer 层本身。这样做有两个好处:一是显著减少可训练参数;二是让草稿器天然工作在和 Target 一致的表示空间里,更像一个贴在 Target 上方的轻量 diffusion adapter,而不是从零学起的第二个 LM。
关键创新:多层特征注入到每层 Attention 的 K/V 上下文
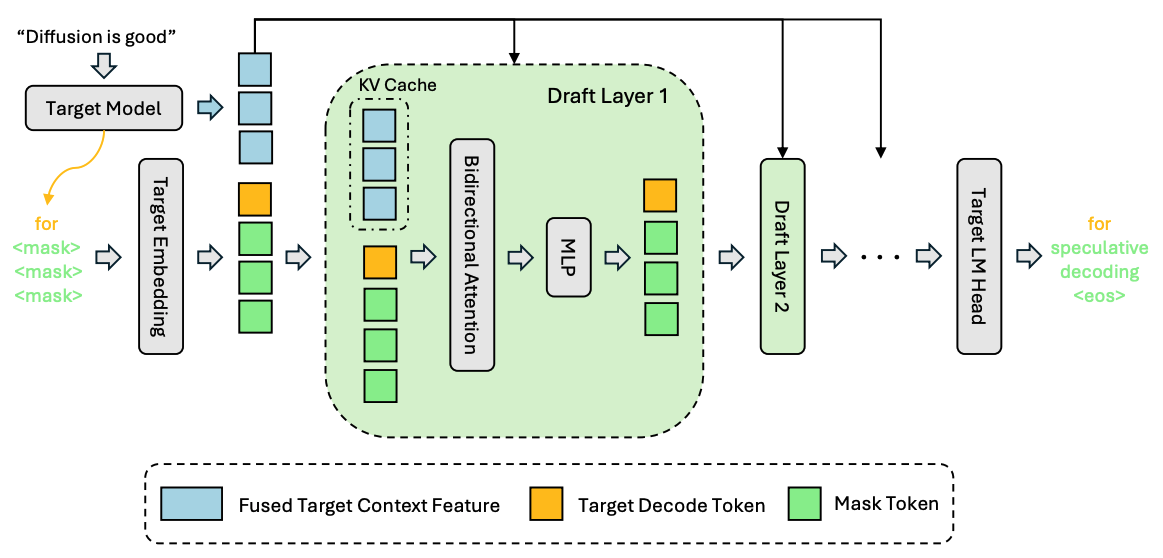
最朴素的做法,是把输入直接送进 Draft Model,让它自己完成并行预测。但 Draft Model 只有 5 层,自身表达能力有限;反过来看,Target Model 跑完 32 层之后,中间层隐向量里已经带着很丰富的上下文语义,例如词性、语义关联和长程依赖。这些信息,Draft Model 自己很难重新推一遍,Target Model 却已经算好了。
DFlash 的做法就是把这些中间结果直接“喂”进 Draft Model,相当于给它开一条捷径。而且不是只在输入端注入一次,而是把它们作为额外的 K/V 上下文注入到每一层 Attention 里,让这条捷径在每一层都持续生效,不会随着深度增加而衰减。
以 Target Model 有 32 层、hidden_size=4096、上下文长度为 10 为例,具体步骤如下。论文主实验通常提取 5 个 Target 中间层;开源实现里这组层位也是可配置的:
Step 1:从 Target Model 提取若干个中间层的隐向量
在第 2 层到倒数第 3 层之间均匀采样若干层。论文默认是 5
层,从浅层到深层均匀覆盖;代码里这组 target_layer_ids
也可以由配置覆盖。每层输出形状都是 [batch, 10, 4096]。
Step 2:拼接 + Projection 降维
以提取 5 层为例,把 5 份隐向量沿特征维度拼接:
1 | [batch, 10, 4096] × 5 → concat → [batch, 10, 20480] |
Projection 是一个轻量线性层,把多层语义压缩回单份 hidden_size,额外参数量不大,但能把浅层到深层的上下文信息压成一份更容易使用的条件特征。
Step 3:注入到 Draft Model 每一层的 K/V 序列
这里的注入方式值得细说。如果只是用一个没有注入的块扩散草稿器,Draft
Model 每层的 Attention 只能在 [M] tokens 之间互相
attend,外加前缀 token 提供的历史 K/V:
1 | 无注入时: |
DFlash 的做法更准确地说,是把融合特征 \(g\) 当作一段额外上下文,与当前 block 的 hidden states 分别经过同一套 K/V 投影后,再前置(prepend)到每一层注意力的 K/V 序列前面:
1 | DFlash 注入后: |
这和 EAGLE-3 把 Target 特征拼在 input embedding 上的做法有本质区别:EAGLE-3 的特征只影响第 1 层输入,随着层加深会逐渐被稀释;DFlash 在每一层都把 Target 特征放进 K/V,每一层 Attention 都能直接“看到” Target 的语义,深度越深,收益越稳定。
与 EAGLE-3 的对比
| EAGLE-3 | DFlash | |
|---|---|---|
| 特征注入位置 | 只在 Draft Model 输入端(一次) | Draft Model 每一层 Attention 的 K/V 上下文 |
| 随层深度传播 | 特征信息逐层稀释 | 每层都能直接 attend 到 Target 特征 |
| Draft Model 深度 | 1 层(加深收益有限) | 5 层(深度可扩展) |
正因为每层都有 Target 特征的直接注入,加深 Draft Model 才能持续带来收益,而不会像 EAGLE-3 那样深度提升后接受率趋于饱和。

核心推理伪代码
把实现抽成几行,其实就是下面这件事:
1 | next_tok, hidden = Target.prefill(prefix) # Target 先给出块首 token,并提取中间层特征 |
真正的优化点其实就两个:把块首 token 交给 Target 锚定,以及把 Target 的中间层语义常驻注入 Draft 的每一层 Attention。前者让单步块预测更稳,后者让一个很浅的 Draft 也能拿到足够强的上下文条件。
训练:位置权重衰减
训练时,Draft Model 需要预测 block 内 \(\gamma\) 个 token。越靠后的位置越难预测,且实际上接受率也更低。DFlash 用指数衰减权重来优先优化靠前的位置:
\[\mathcal{L} = \sum_{k=1}^{\gamma} w_k \cdot \text{CE}\!\left(\hat{p}_k,\, p_k^*\right), \quad w_k = \exp\!\left(-\frac{k-1}{\gamma_{\text{decay}}}\right)\]
| Block 大小 \(\gamma\) | \(\gamma_{\text{decay}}\) |
|---|---|
| 16 | 7 |
| 10 | 5 |
| 8 | 4 |
训练上,DFlash 还有一个很关键、但论文正文里一句话容易看漏的设计:随机锚点(random anchors)。它不是像标准块扩散那样把 response 均匀切成 block,再在每个 block 里随机 mask 若干位置;而是从 response 里随机采样 anchor token,把这个 anchor 作为 block 的第一个干净 token,然后把后面 \(\gamma - 1\) 个位置 mask 掉,让 Draft 一次并行预测。这样训练出来的 Draft,正好对应推理时“先由 Target 给出一个 bonus token,再并行补后续 block”的行为。
训练时,所有这样的 masked blocks 会拼成一个大序列,用稀疏 attention 一起算:同一 block 内双向注意力,不同 block 之间互相不可见,同时都可以看到对应注入的 Target context feature。这样既保持了训练-推理对齐,又能用 Flex Attention 一次性高效训练很多 block。
训练超参数:6 epochs,AdamW,学习率 \(6\times 10^{-4}\),最大序列长度 3072 tokens(Qwen3-Coder 为 4096);每条序列随机采样 512 个 anchor 位置。论文还提到训练既可以在线进行(每步现算 Target hidden feature),也可以离线缓存这些特征再训练 Draft,以减小开销。
验证:沿用投机解码的左到右验证
论文层面,DFlash 仍然属于 lossless speculative decoding:最终输出始终由 Target Model 的验证过程约束。但如果对照开源实现,表达上最好不要直接把它写成“原始 speculative sampling 论文里的标准拒绝采样公式”。当前代码更接近下面这套流程:
- Target Model 先给出当前 block 的第一个 token
- Draft Model 以这个干净 token 为锚点,单次前向传播并行补出后续 \(\gamma - 1\) 个候选位置
- Target Model 对整段 block 并行计算 posterior
- 按位从左到右接受与 posterior 一致的最长前缀;一旦不一致,就用 Target 的 token 继续下一轮
所以更稳妥的理解是:DFlash 沿用了投机解码“由 Target 验证并兜底”的无损框架,但开源实现采用的是最长前缀接受式的具体工程实现。 这样写既保留了论文主旨,也更贴近代码。
把它和 EAGLE 系列放在一起看会更清楚:自回归草稿器每步只能生成一个 token。为了提高覆盖率,只能在每个位置继续分叉,长成一棵草稿树,再用 tree attention 并行验证整棵树。DFlash 一步直接输出 \(\gamma\) 个 token,天然就是线性序列,不需要树结构,验证流程也更简单。换句话说,树是自回归草稿器为了补救串行生成缺陷才引入的结构,DFlash 则绕开了这个补丁。
为什么 5 层 Draft Model 比 1 层更快?
这是 DFlash 最反直觉的地方。直觉上,5 层应该比 1 层慢。
实际的对比:
| 方法 | 草稿过程 | 实际延迟(\(\gamma=16\)) |
|---|---|---|
| EAGLE-3 (1L) | 16 次串行 × 1 层前向 | \(16 \times t_{1\text{L}}\) |
| DFlash (5L) | 1 次并行 × 5 层前向 | \(t_{5\text{L}}\) |
由于矩阵乘法的并行性,\(t_{5\text{L}} \ll 16 \times t_{1\text{L}}\)。论文实测里,DFlash 的草稿成本低于 EAGLE-3(16):用 5 层换来了更低的总延迟,也换来了更高的预测质量。
这里有一个值得细想的问题:既然已经有 Target Model 特征注入,用 1 层草稿器不够吗?
在 EAGLE 里,加深草稿器是两难的:1 层快,但质量有上限;加到 2 层,每一步就多一层,\(\gamma\) 步累计下来延迟几乎翻倍,所以 EAGLE 很难跳出 1 层。到了 DFlash,这个约束没了。不管草稿器是 1 层还是 5 层,都只需要 1 次前向传播,加深带来的额外延迟很小。既然深度不再是主要负担,就可以用更多层做更充分的特征整合:每层变换都在继续融合 Target 语义和块内各位置的依赖关系,对 \(\gamma\) 个位置的联合预测也会更准。于是 5 层比 1 层接受率更高,而延迟几乎不变,自然更划算。
说白了,并行生成把“加深模型”这件事,从负担变成了收益。
实验结果
平均接受长度(AAL)
在 Qwen3-8B 上:
| 方法 | AAL(温度=0) | AAL(温度=1) |
|---|---|---|
| EAGLE-3 (budget=16) | 2.96 | 2.83 |
| EAGLE-3 (budget=60) | 3.40 | — |
| DFlash(block=16) | 6.49 | 5.48 |
DFlash 的 AAL 约为 EAGLE-3 的 2.2×。这意味着每轮 Target Model 验证后平均接受的 token 更多,Target Model 调用频率更低。

端到端加速比
Transformers 后端:
| 模型 | DFlash 加速比 | vs EAGLE-3(16) |
|---|---|---|
| Qwen3-4B | 4.91× | +2.47× |
| Qwen3-8B | 4.86× | +2.40× |
温度=1(采样模式)下:Qwen3-4B 4.24×,Qwen3-8B 4.03×。
SGLang 后端(B200 GPU,并发=1):
| 模型 | DFlash 加速比 |
|---|---|
| Qwen3-4B(数学) | 8.01× |
| Qwen3-8B(数学) | 5.1× |
| Qwen3-Coder-30B | 3.5× |
| LLaMA-3.1-8B(GSM8K) | 2.4× |
| LLaMA-3.1-8B(HumanEval) | 2.8× |
DiffuSpec:无需训练的扩散草稿器
前面讲的是 DFlash 这条“强绑定 Target Model”的路线。下面再看两篇思路不同的工作:它们把扩散草稿器保持为独立模型,但也因此要额外处理和验证器之间的对齐问题。
DiffuSpec(2510.02358) 是同期把扩散语言模型引入投机解码的工作。它最吸引人的地方是完全不需要额外训练,直接把一个预训练的扩散语言模型当草稿器插进去就能用。
核心问题:扩散是双向的,验证是单向的
扩散语言模型用双向注意力,一次并行预测多个位置,输出的是对整个序列的联合分布。而投机解码的验证步骤需要的是从左到右的因果条件概率:\(p(t_k \mid t_1, \ldots, t_{k-1})\)。这两者之间有根本性的对齐问题。
DiffuSpec 用两个机制来弥合这个对齐缺口:
因果一致性路径搜索(CPS)
扩散模型一次前向传播后,对每个位置输出一个候选 token 集合(取 softmax 概率最高的 top-M 个),\(\gamma\) 个位置合起来构成一个 token lattice。每个位置都有多个候选,所以所有位置拼起来的组合数是指数级的。
问题在于:扩散模型选出的联合最优组合,不一定符合自回归的因果条件(即“用前 \(k-1\) 个 token 预测第 \(k\) 个”)。CPS 在这个 lattice 上做从左到右的 beam search(默认 beam=3),对每条路径用两个分数的加权和打分:扩散模型对该 token 的置信度,加上一个小型因果语言模型(n-gram 或轻量 LM)对该路径因果一致性的评分。最终选出分数最高的那条路径作为草稿序列。
以生成 4 个位置的草稿为例:
1 | 扩散模型输出的候选集合(每个位置 top-3): |
候选集的大小根据每个位置的熵自适应调整:预测越确定的位置候选越少,越不确定的位置候选越多(上限 \(M_{\max}=15\)),这样可以同时兼顾搜索质量和效率。
自适应草稿长度(ADL)
草稿长度 \(\gamma\) 在推理过程中动态调整。ADL 用指数移动平均(EMA)追踪两个信号:每轮草稿的有效生成长度 \(L^{\text{gen}}\)(遇到 EOS 截断)和实际被接受的长度 \(L^{\text{acc}}\),然后按如下规则更新下一轮的 \(\gamma\):
\[k_{t+1} = \text{clip}\!\left(\lfloor L^{\text{gen}} \rfloor + \delta \cdot \mathbf{1}[L^{\text{acc}} \geq L^{\text{gen}}],\ k_{\min},\ k_{\max}\right)\]
接受率高(\(L^{\text{acc}} \geq L^{\text{gen}}\))时,\(\gamma\) 增加 \(\delta\)(默认 10 个 token);接受率低时,\(\gamma\) 收缩回 \(L^{\text{gen}}\) 附近。默认 \(k_{\min}=20\),\(k_{\max}=30\),控制器开销为 \(O(1)\)。
实验结果
在 Qwen-2.5-72B 和 LLaMA-2-70B 上测试,无训练情况下:
| 任务 | 加速比 |
|---|---|
| MT-Bench | 3.09× |
| 翻译 | 3.38× |
| 数学 | 4.02× |
| 摘要 | 2.41× |
| 平均 | 3.08× |
平均接受长度(MAT)达到 6.99,接近需要额外训练的 EAGLE-2。
局限
CPS 搜索引入了额外延迟;草稿长度需要提前指定上限;不同任务的接受率差异较大,ADL 需要仔细调参。本质上,无训练意味着扩散模型和 Target Model 之间没有显式对齐,只靠搜索策略弥合。
SpecDiff-2:用训练解决对齐问题
SpecDiff-2(2511.00606) 是对 DiffuSpec 的后续工作。它的判断也很明确:只在推理时靠 CPS 搜索补救,治标不治本;扩散草稿器和自回归验证器之间的分布对齐,最好在训练阶段解决。
两个对齐机制
Streak-Distillation(训练阶段)
用一个代理验证器(贪心接受)来给扩散模型提供训练信号:模型生成的草稿,如果验证器连续接受了 \(k\) 个 token,就给这条路径正梯度;否则给负梯度。本质是让扩散模型学会“生成验证器愿意接受的序列”。
训练的草稿模型是现成的扩散语言模型(DiffuCoder-7B 或 DiffuLLaMA-7B),在此基础上微调。
Self-Selection Acceptance(推理阶段)
推理时并行采样 \(K\) 条草稿,用 Target Model 给每条草稿打分,选期望吞吐最高的那条提交验证。用少量额外的并行计算换更高的接受率。
实验结果
在 Qwen2.5-72B 和 LLaMA-2-70B 上:
| 模型 | 任务 | 加速比 |
|---|---|---|
| Qwen2.5-72B | Math-500 | 4.62× |
| LLaMA-2-70B | 综合 | 3.61× |
| 平均 | 4.71× |
相比 DiffuSpec 的 3.08× 提升了约 55%。
局限
Streak-Distillation 训练成本较高(约 50k–60k GPU hours);Self-Selection 需要并行生成 \(K\) 条草稿,引入了额外的显存和计算开销;跨 tokenizer 或跨模型族的迁移效果会下降。
现在的瓶颈与未来方向
三者对比
| DiffuSpec | SpecDiff-2 | DFlash | |
|---|---|---|---|
| 是否需要训练 | 否 | 是(蒸馏) | 是(从头训练) |
| 对齐方式 | CPS 搜索(推理时) | Streak-Distillation(训练时) | Target 特征直接注入每层 Attention 的 K/V |
| 草稿器深度 | 独立扩散模型 | 独立扩散模型 | 5 层,深度嵌入 Target 语义 |
| 平均加速比 | ~3× | ~4.7× | ~5×(Transformers)/ ~8×(SGLang B200) |
| 核心思路 | 扩散并行 + 搜索对齐 | 扩散并行 + 训练对齐 | 扩散并行 + 特征融合对齐 |
DiffuSpec 和 SpecDiff-2 都把扩散模型当作一个独立的草稿器,再通过外部手段(搜索或蒸馏)让它和 Target Model 对齐。DFlash 走的是另一条路:让草稿器从设计上就依赖 Target Model,把 Target 的中间特征直接注进 Draft 的每一层,对齐问题在架构层面先解决掉。
瓶颈与可能方向
DFlash 的加速比已经很高了,但这条路上还有几个很现实的瓶颈。
瓶颈一:高并发下加速比大幅下降
DFlash 的测试主要在并发 = 1(单请求)的场景下进行,此时 GPU 计算资源充裕,并行草稿生成能发挥出最大收益。但在生产环境的高并发场景下,GPU 已经被多个请求占满,草稿生成和验证都面临资源竞争,加速比会显著缩小。这是所有投机解码方法的共同瓶颈,不只是 DFlash 的问题。
可能方向:针对批处理推理专门设计的扩散草稿器,或者结合 Continuous Batching 的流水线调度,让草稿生成和验证在时间轴上错开。
瓶颈二:草稿长度 γ 需要手动调
当前 DFlash 的 block size(即 \(\gamma\))在训练时就固定了(8、10 或 16)。不同任务、不同模型的最优 \(\gamma\) 差异很大:数学推理适合长草稿(接受率高),开放对话适合短草稿(接受率低、长草稿浪费)。训练时固定 \(\gamma\) 意味着一个模型无法自适应。
可能方向:类似 DiffuSpec 的 ADL,在推理时动态调整 \(\gamma\);或者训练时覆盖多种 block size,推理时按任务类型切换。
瓶颈三:扩散草稿器本身的训练成本
DFlash 的草稿器需要针对每个 Target Model 单独训练(6 epochs,最大序列长度 3072),不同模型族之间不能直接复用。这意味着每换一个 Target Model 就要重新训练草稿器,部署成本较高。
可能方向:先做草稿器的通用预训练,在大规模语料上得到一个扩散基础草稿器;再用少量数据对特定 Target Model 做轻量对齐,思路有点像 SpecDiff-2 的蒸馏,但成本可以更低。
瓶颈四:显存占用增加
DFlash 的草稿器有 5 层,且每层 Attention 都要额外携带由 Target 特征投影得到的 K/V 上下文,显存占用高于 EAGLE-3 的 1 层草稿器。在显存紧张的场景(如边缘设备或多路并发)下,这会限制可用的批大小。
可能方向:特征压缩(减少注入的 Target 层数),或者压缩草稿器里额外的 K/V 上下文状态。
更长远:扩散与自回归的深度融合
DFlash 本质上还是“自回归 Target + 扩散草稿”的两阶段结构,Target Model 本身没有变。更激进的方向,是让 Target Model 自身也具备并行生成能力,比如把它训练成一个混合自回归-扩散模型,在解码阶段直接输出多个 token 的联合分布,彻底消除对单独草稿器的依赖。这个方向目前还处于早期探索阶段(如 D3LLM 等工作),离生产可用还有一段距离。
小结
DFlash 的核心洞见其实很朴素:投机解码的草稿器不必是自回归的,只要能快速生成多个候选 token,就能拿来做草稿。
块扩散恰好提供了这个能力:块内并行生成 \(\gamma\) 个 token,草稿成本和 \(\gamma\) 基本脱钩。再加上对 Target Model 深层特征的全层 K/V 上下文注入,Draft Model 的预测质量明显上去了,平均接受长度也从 EAGLE-3 的 3.4 提升到 6.49。
如果把 EAGLE 系列和 DFlash 放在一起看,主线其实一直没变:尽量减少 Target Model 的前向次数。区别只在于,EAGLE 主要靠更好的草稿树;DFlash 则同时压低草稿成本、抬高草稿质量,于是把加速比又往前推了一截。
参考文献
- DFlash(2602.06036) — 本文主角
- LLaDA(2502.09992) — 掩码扩散语言模型
- Block Diffusion / BD3-LM(2503.09573) — 块间 AR、块内扩散
- DiffuSpec(2510.02358) — 无训练扩散草稿器 + CPS
- SpecDiff-2(2511.00606) — Streak-Distillation 对齐训练
- EAGLE(2401.15077) — 特征级自回归草稿器
- EAGLE-2(2406.16858) — 动态草稿树
- EAGLE-3(2503.01840) — 多层特征融合
- Speculative Decoding(2211.17192) — 投机解码原论文
- D3LLM(2601.07568) — 自回归-扩散深度融合探索