NLP基本知识的介绍及NLTK模块的使用。
第三章:加工原料文本
可以从这个项目中获取感兴趣的文本,之后进行分析。
1 | import nltk |
处理文本部分:
requests: 数据获取
BeautifulSoup、re、xpath: 文本处理
feedparser:处理RSS订阅
os:处理本地文件
字符串基本操作在这里请见下图。注:字符串是不可改变的。

关于编码这个大坑,在Python3中做的已经比Python2好太多,在这里也不做介绍了。介绍一些关于编码处理的库。
codecs、unicodedata
正则表达式部分,推荐自主学习。难度系数不算高。搜索关键词,Python, 正则表达式, re即可。值得一提的是,re是目前我了解处理文本速度最快最优雅的一种方式。
英文文本是高度冗余的,忽略掉词内部的元音仍然可以很容易的阅读,有些时候这很明显。例如:declaration 变成 dclrtn,inalienable 变成 inlnble,保留所有词首或词尾的元音序列 。
1 | import nltk |
词干提取器
1 | # 查找词干,laptop与laptops其实只是单复数的区别。词干是相同的 |
分词:
1 | # 使用正则进行分词 |
已经分词好的数据举例:
《华尔街日报》原始文本(nltk.corpus.treebank_raw.raw())和分好词的版本(nltk.corpus.treebank.words())
分词的最后一个问题是缩写的存在,如“didn’t”。如果我们想分析一个句子的意思,将这种形式规范化为两个独立的形式:“did”和“n’t”(不是 not)可能更加有用。我们可以通过查表来做这项工作。
链表与字符串部分不做介绍,是Python字符串的常规操作
补充部分:
建立词汇表流程

编码点:每个字符分配一个编号
解码:通过一些机制来将文本翻译成 Unicode的过程
编码:将Unicode转化为其它编码的过程
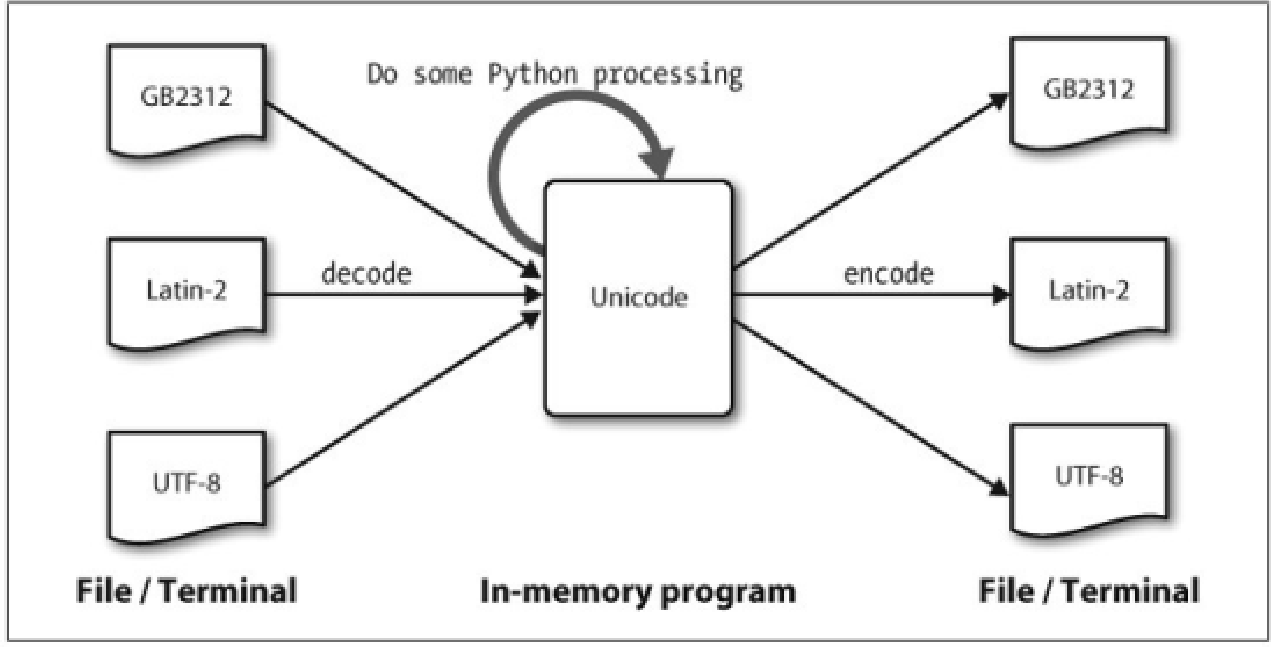
从 Unicode的角度来看,字符是可以实现一个或多个 字形的抽象的实体。只有字形可以出现在屏幕上或被打印在纸上。一个字体是一个字符到字形映射。
规范化文本:如将所有的文本小写保存,使用
lower()这个函数断句:在将文本分词之前,我们需要将它分割成句子
分词(重点内容):
找到一种方法来分开文本内容与分词标志。给每个字符标注一个布尔值来指示这个字符后面是否有一个分词标志
找到将文本字符串正确分割成词汇的字位串。根据一个字典,来根据字典中词的序列来重构源文本。定义一个目标函数,通过字典大小与重构源文本所需的信息量尽力优化它的值。
找到最大化目标函数值的0和1的模式。使用模拟退火算法的非确定性搜索。
第四章:编写结构化程序
大量关于Python代码,不做介绍。此部分适宜阅读人群,使用Python时间不超过一年(不够熟练)
文档说明模块:docstring
调试技术:pdb
绘图:matplotlib
图的绘制:networkx
数据统计表:csv(这里个人推荐有使用pandas,虽然它很”重“)
数值运算:numpy
算法设计:
- 递归
- 权衡空间与时间
- 动态规划
第五章:分类和标注词汇
NLP基本技术:
- 序列标注
- N-gram 模型
- 回退和评估
将词汇按它们的词性(parts-of-speech,POS)分类以及相应的标注它们的过程被称为词性标注(part-of-speech tagging, POS tagging)或干脆简称标注。词性也称为词类或词汇范畴。用于特定任务的标记的集合被称为一个标记集。
词性标注器
1 | import nltk |
标注语料库
1 | # 创建一个有标识的字符串 |
获取已标注的语料库
1 | # 获取标注好的语料库 |
1 | # 未简化的标记 |
Python字典部分不做介绍。
1 | # 使用默认字典可以防止使用未定义的key报错 |
自动标注
1 | import nltk |
评估
使用黄金标准测试数据。一个已经手动标注并作为自动系统评估标准而被接收的语料库。
如果标注器对词的标记与黄金标准标记相同,那么标注器就被认为是正确的。当然这只是相对于黄金标准这个测试数据而言。
关于开发一个已标注的语料库,这是一个庞大的任务,其中涉及到了许多方面。
可以通过nltk.app.concordance()来可视化查找某个语料库中某个单词的词性
| 标记 | 含义 |
|---|---|
| ADJ | 形容词 |
| ADV | 动词 |
| CNJ | 连词 |
| CC | 并列连词 |
| DET | 限定词 |
| EX | 存在量词 |
| FW | 外来词 |
| MOD | 情态动词 |
| RB | 副词 |
| IN | 介词 |
| N | 名词 |
| NP | 专有名词 |
| NUM | 数词 |
| PRO | 代词 |
| P | 介词 |
| TO | 词to |
| UH | 感叹词 |
| V | 动词 |
| VD | 过去式 |
| VG | 现在分词 |
| VN | 过去分词 |
| WH | Wh限定词 |
| NN | 名词 |
| JJ | 形容词 |
| VBP | 一般现在时动词 |
N-gram标注
1-gram标注器:一元标注器(unigram tagger)。用于标注一个标识符的上下文的只是标识符本身。
2-gram 标注器:二元标注器(bigram taggers)
3-gram 标注器:三元标注器(trigram taggers)
N-gram标注不考虑句子边界的上下文。
1 | from nltk.corpus import brown |
存储可以使用python自带的存储模块pickle。
效果:
根据经验来进行判断——一般方法
1
2
3cfd = nltk.ConditionalFreqDist(((x[1], y[1], z[0]), z[1]) for sent in brown_tagged_sents for x, y, z in nltk.trigrams(sent))
ambiguous_contexts = [c for c in cfd.conditions() if len(cfd[c]) > 1]
sum(cfd[c].N() for c in ambiguous_contexts) / cfd.N()研究标注器的错误——混淆矩阵
1
2
3test_tags = [tag for sent in brown.sents(categories='editorial') for (word, tag) in t2.tag(sent)]
gold_tags = [tag for (word, tag) in brown.tagged_words(categories='editorial')]
print nltk.ConfusionMatrix(gold, test)
n-gram标注器的问题
- 模型大小与标注器性能之前的平衡关系。如果使用回退标注器
n-gram可能存储trigram和bigram表,这将会是很大的稀疏矩阵。 - 使用上下文中的词的其他特征作为条件标记是不切实际的。
Brill标注只使用一小部分n-gram标注器。猜每个词的标记,然后返回和修复错误的。从大方面下手,再勾勒细节。规则是语言学可解释的。
1 | nltk.tag.brill.demo() |
下一篇:NLTK阅读笔记Ⅲ