LLM 在宽度上的稀疏性可以通过 MoE 这种架构来优化。而深度上也具备稀疏性,故而可以进行裁剪。
背景
这篇博客发现到 GPT-2 在深度上的输出具有相似性。即,第 20 层的输出接入 LM Head 和第 21 层的输出接入 LM Head 是相似,甚至一致的。
故而,模型在深度上可能是稀疏的。所以可以按 block 的维度进行裁剪。如下图所示,
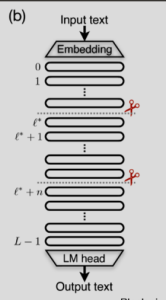
找到三篇相似的工作
- 上交:LaCo: Large Language Model Pruning via Layer Collapse
- Meta:The Unreasonable Ineffectiveness of the Deeper Layers
- 百川:ShortGPT: Layers in Large Language Models are More Redundant Than You Expect
越靠近模型输出的那些层相似度较高,可以通过删除一些“冗余”层来减小模型参数
方法的共通性
- 构建一个“中性”数据集!!!
- 观察不同层的输入/输出
- 用某种度量距离的方法测量不同层是否相似
- 百川:Block Influence
- Meta:角距离
Meta 论文结果
不同模型具有相似的表现
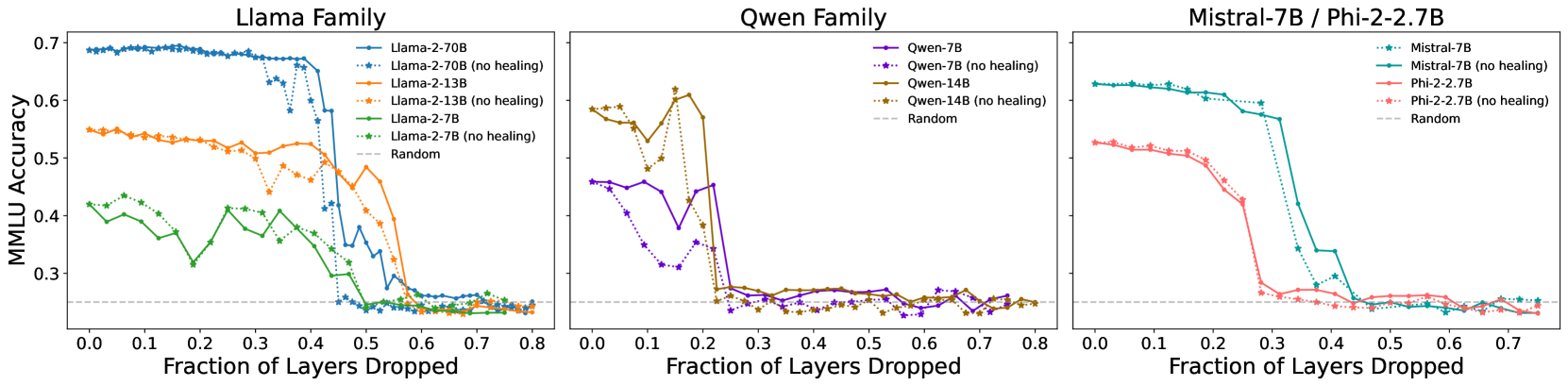
注:
- 实线(healing):扔掉一些层之后进行了训练
- 虚线(no healing): → 扔掉这些层后不训练
- 实线和虚线扔掉的是相同的层
- 横坐标是扔掉的比例
Q:MMLU/BoolQ 指标具备足够的可信度?
A:个人感觉没有,但有后续有其他的一些实验支撑
Q:Qwen 为啥表现不大一样?
A:论文其他部分进行一定的解释,但与本文的重点相关性不强,所以不展开介绍
暴力裁剪 vs 提出的方法
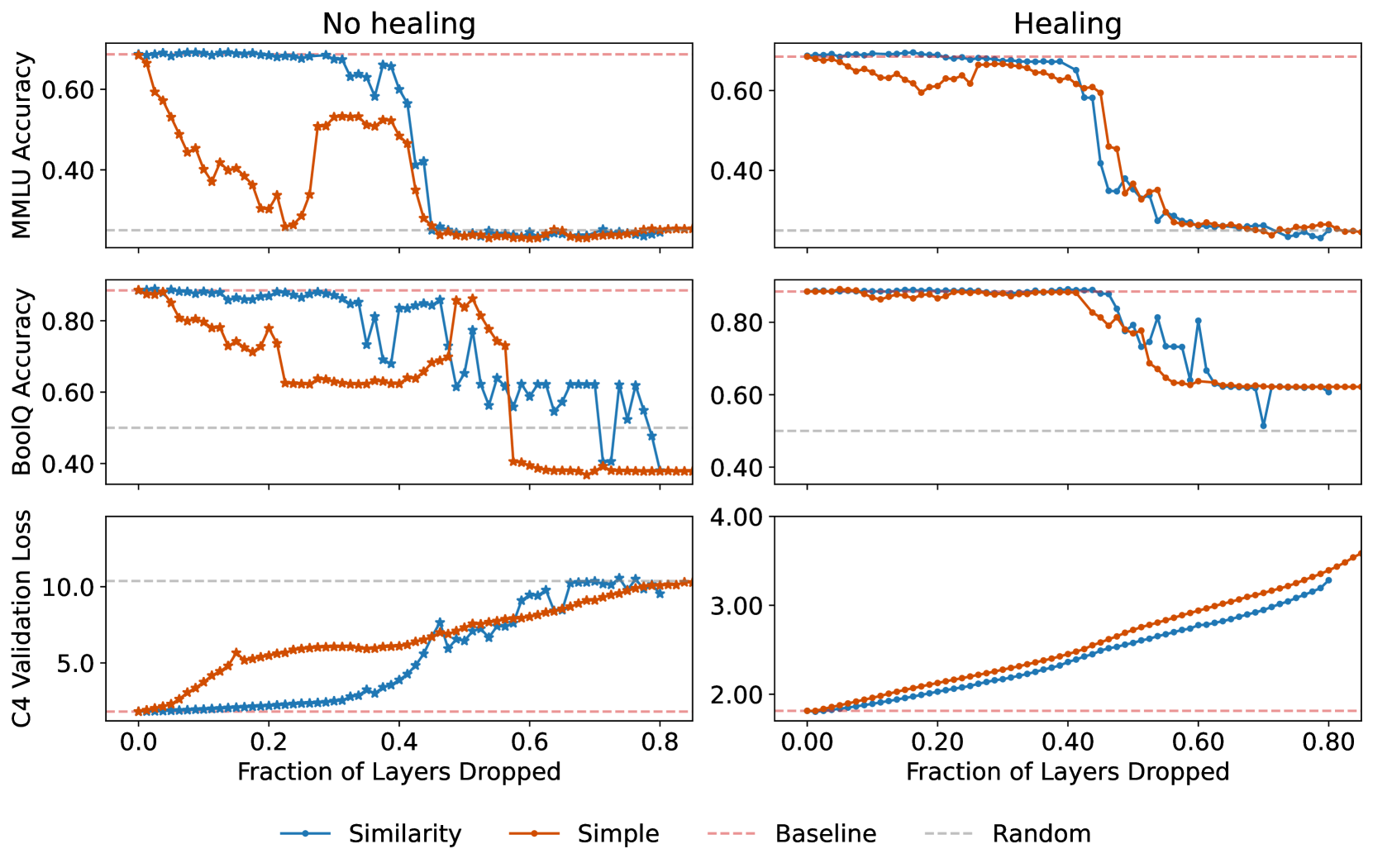
有一种直接粗暴的方法就是直接扔掉最后若干层,这样就不需要数据集啥的来选层。
奇怪的现象就是直接扔掉最后若干层,指标会出现先降低再提升(不训练的情况)。
百川论文的结论
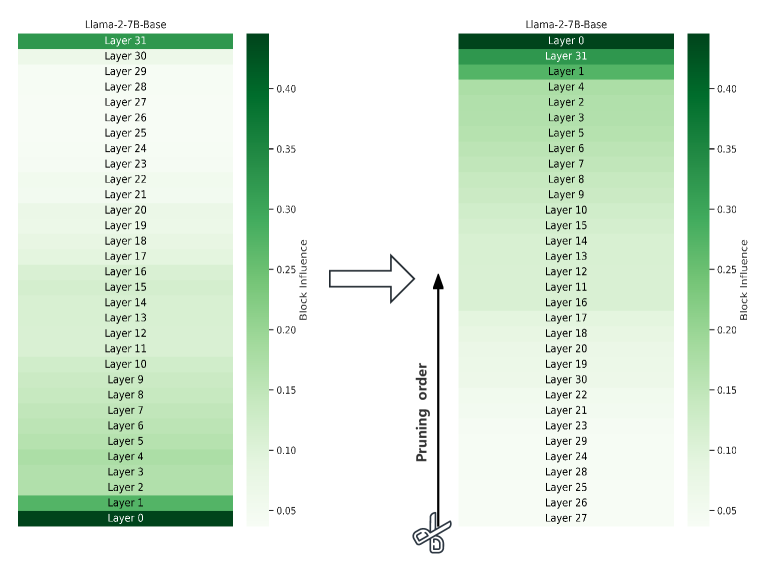
第一层和最后一层很重要!!!
剪枝比率
利用宽度稀疏性,一种优化架构 MoE 可以做到降低一半的参数且保持性能不变。
而在深度稀疏上,这一点是比较难做到的。
| 模型尺寸 | 层数 | 参数量 |
|---|---|---|
| 70B | 80 | 69,434,351,616 |
| 70B | 40 | 35,208,175,616 |
| 70B | 45 | 39,486,447,616 |
| 34B | 48 | 34,201,673,728 |
| 34B | 24 | 17,591,836,672 |
简单来说,对于 70B 模型要剪枝到 34B,需要砍掉一半的层;对于 34B 模型要剪枝到 13B,要砍掉大于一半的层。
通过 Meta 论文的实验结果显示,当裁剪超过 40%,就会有较大的风险不能恢复模型性能。
实验
在 boolq/gsm8k 数据集上简单了进行若干实验,这两个数据集均具备训练集和评测集。所以,对 13B 模型进行暴力裁剪后(~40% 参数)在训练集上进行训练,在评测集上进行评测。
- 裁剪方法:保留最后一层,从最后一层往前数,直至裁剪到 40% 为止。
- 完整训练集:对应评测的训练集+通用的QA/对话数据集
gsm8k
是一个考验数学/逻辑推理能力的评测结果
1 | "conversations": [ |
在该评测上指标直接崩掉,如原来可能是 >70,现在只有 2%
| prompt | pred |
|---|---|
| Janet’s ducks lay 16 eggs per day. She eats three for breakfast every morning and bakes muffins for her friends every day with four. She sells the remainder at the farmers' market daily for $2 per fresh duck egg. How much in dollars does she make every day at the farmers' market? Let's think step by step. | Each egg is 16 eggs/day for 16 eggs/day for 1600000000 / 16 = 128000000. So, the total number of eggs is 128000000. The total number of eggs is 160000000 - 128000000 = 128000000.The answer is 128000000. |
| A robe takes 2 bolts of blue fiber and half that much white fiber. How many bolts in total does it take? Let's think step by step | The rose is 2 bolts of blue fibers. Half that amount is 2 / 2 = 1. So the rose is 2 - 1 = 2 flobs. The answer is 2. |
| Josh decides to try flipping a house. He buys a house for $80,000 and then puts in $50,000 in repairs. This increased the value of the house by 150%. How much profit did he make? Let's think step by step. | The house was originally 80,000 dollars. The new house is 80,000 + 50,000 = 15,000 dollars. The new house is 15,000 dollars. So, the total value of the house is 15,000 + 80,000 + 15,000 = 11,000 dollars. The total value of the house is 11,000 dollars. The total value of the house is 11,000 + 15,000 = 11,000 + 15,000 = 11,000 + 15,000 = |
boolq
而 boolq 相对是一个简单的数据集,输出只需要有 yes or no 即可。
1 | "conversations": [ |
在该指标上结果就是相对正常的,符合 Meta 论文的结果。
- 裁剪前:~84%
- 裁剪后:~68%
- 裁剪+训练后:~85%
所以,模型深度或许是加强模型推理能力的关键因素之一?